KazLLM et l'IA souveraine : guide pour les fonctionnaires du Kazakhstan

Le 11 février 2026, lors d’une réunion gouvernementale, le président Tokayev a publiquement critiqué KazLLM. Le modèle, lancé en grande pompe en décembre 2024, ne compte que 600 000 utilisateurs – soit 3 % de la population du pays. À titre de comparaison : ChatGPT est utilisé par 2,6 millions de personnes au Kazakhstan. Le président a été direct : KazLLM « ne peut pas rivaliser avec ChatGPT ».
Cette déclaration pose la question sans détour. Pourquoi le Kazakhstan a-t-il besoin de son propre modèle linguistique si les solutions globales fonctionnent mieux ? Et si l’IA souveraine est nécessaire – pourquoi perd-elle la partie ?
La réponse est plus complexe qu’il n’y paraît. Parce que KazLLM n’est pas « le ChatGPT kazakh ». C’est un outil fondamentalement différent, avec une mission différente. Les comparer revient à comparer une centrale électrique nationale avec un appareil électroménager importé.
Pourquoi un pays a-t-il besoin de son propre modèle linguistique
Quand un fonctionnaire traite les demandes des citoyens via ChatGPT, trois choses se produisent simultanément. Les données personnelles des citoyens sont envoyées sur les serveurs d’OpenAI aux États-Unis. Le contexte de la langue kazakhe – morphologie agglutinante, alternance codique entre kazakh et russe – est interprété avec des pertes. Et l’État ne contrôle ni la disponibilité du service, ni son coût, ni sa politique de traitement des données.
Ce n’est pas un risque théorique. Quand l’Italie a bloqué ChatGPT en 2023 pour violation du RGPD, les processus étatiques qui en dépendaient se sont arrêtés. Quand OpenAI impose des restrictions pour certaines régions – les conséquences sont imprévisibles. La question de la responsabilité des décisions prises avec l’aide de l’IA dépasse largement le cadre technologique.
Un modèle souverain résout ce problème de manière architecturale. Les données ne quittent pas l’infrastructure nationale. Le modèle est entraîné sur la langue kazakhe en tenant compte des dialectes régionaux. Et l’État contrôle chaque élément de la pile – des capacités de calcul aux algorithmes.
Le Kazakhstan n’est pas seul dans cette démarche. Les Émirats arabes unis ont construit Falcon, le Japon – Fugaku-LLM, Taïwan – TAIDE, Singapour – SEA-LION. Chacun de ces pays est arrivé à la même conclusion : la dépendance aux modèles d’autrui est une vulnérabilité stratégique.
Ce qu’est réellement KazLLM
KazLLM – officiellement ISSAI KAZ-LLM – a été développé par l’Institut des systèmes intelligents et de l’intelligence artificielle (ISSAI) de l’Université Nazarbayev, en collaboration avec QazCode (filiale de VEON/Beeline Kazakhstan). Le soutien international a été assuré par le Barcelona Supercomputing Center et le GSMA Foundry. En mars 2025, le modèle a reçu le GSMA Foundry Excellence Award et a été présenté au Mobile World Congress de Barcelone.
Étonnamment, malgré cette reconnaissance internationale – 600 000 utilisateurs contre 2,6 millions pour ChatGPT. Le prix est impressionnant, mais les chiffres racontent une autre histoire.
Techniquement, le modèle est construit sur l’architecture Meta Llama 3.1 – un framework open-source éprouvé. L’équipe n’a pas construit l’architecture à partir de zéro, mais a adapté une architecture existante en réentraînant les poids neuronaux pour donner la priorité à la langue kazakhe. Deux versions sont disponibles : une version compacte de 8 milliards de paramètres pour les tâches rapides et une version complète de 70 milliards de paramètres pour les analyses complexes. Les deux modèles sont publiés en open source sur Hugging Face – on peut les télécharger, les tester et les déployer sur sa propre infrastructure.
L’avantage clé réside dans les données. Une équipe spécialisée « Token Factory » de l’ISSAI a, pendant neuf mois, collecté et curé un corpus d’entraînement de plus de 150 milliards de tokens. Les sources comprennent des ressources web kazakhes, des archives gouvernementales et de la littérature académique. Le modèle est entraîné sur quatre langues – kazakh, russe, anglais et turc – avec prise en charge de l’alternance codique, lorsqu’une personne passe d’une langue à l’autre dans la même phrase. C’est précisément ce qui distingue KazLLM des modèles globaux : une compréhension profonde de la réalité multilingue de la région.
Pourquoi la comparaison avec ChatGPT est-elle alors inappropriée ? Le président du conseil d’administration de Kazakhtelecom, Bagdat Mussin, l’a formulé par analogie : un modèle linguistique fondamental est une centrale électrique nationale. Il produit de l’« énergie intellectuelle ». ChatGPT et les services similaires sont des appareils électroménagers : utiles, pratiques, mais branchés sur une prise étrangère.
L’ISSAI lui-même a publié une analyse détaillée de la situation après les critiques de Tokayev. L’ampleur des ressources parle d’elle-même : pour créer Llama, Meta a mobilisé plus de 16 000 nœuds NVIDIA DGX H100 et plus de 400 chercheurs. L’équipe de l’ISSAI a travaillé sur 8 nœuds DGX H100, fournis par une entreprise privée de télécommunications.
Par ailleurs, l’institut reconnaît : « L’IA est une course. De nouveaux modèles apparaissent environ tous les six mois, et KazLLM doit continuer à évoluer ». Cependant, après le transfert du modèle à Astana Hub en décembre 2024, l’ISSAI « n’a pas été sollicité pour poursuivre son développement ». Le modèle est resté sans mise à jour, tandis que les concurrents publiaient de nouvelles versions chaque trimestre.
Alem LLM et le supercalculateur Alem.Cloud
Parallèlement à KazLLM, l’État a déployé un projet d’infrastructure d’une tout autre envergure. Alem.Cloud – le supercalculateur national et le cluster de calcul le plus puissant d’Asie centrale. Ses caractéristiques : 2 exaflops de performance (FP8), 512 GPU NVIDIA H200.
L’obtention de ces puces a été en soi une manœuvre géopolitique – elle a nécessité des négociations avec les États-Unis pour obtenir des licences d’exportation dans un contexte de restrictions mondiales sur les livraisons de GPU avancés.
Alem LLM – le second modèle souverain – fonctionne sur cette infrastructure. Comme KazLLM, il est multilingue (kazakh, russe, anglais, turc) et destiné aux services étatiques. La différence clé réside dans l’intégration profonde avec la ressource informatique nationale : les données sont traitées sur le territoire du Kazakhstan, sur des équipements d’État.
C’est sur cette infrastructure que se construit la Plateforme nationale d’intelligence artificielle – un environnement sécurisé où les développeurs étatiques et les universités partenaires accèdent à des capacités de calcul, des jeux de données nettoyés et des modèles pré-entraînés. Lors du Forum de Davos en janvier 2026, des partenariats ont été annoncés avec NVIDIA, OpenAI et Scale AI – dans les domaines du supercalcul, de l’infrastructure éducative et de la préparation des données via RLHF.
Agents IA pour l’administration publique : projets vs réalité
Les modèles abstraits prennent de la valeur quand ils se transforment en outils concrets. Le Kazakhstan a annoncé le déploiement de plus de dix agents IA spécialisés pour les processus étatiques. Mais il faut distinguer les plans de la réalité.
Ce qui fonctionne déjà :
- AI Therapist – le seul agent avec un pilote confirmé. Lancé dans 30 cliniques de la région d’Akmola. Il analyse les conversations médecin-patient en temps réel, produit des diagnostics préliminaires avec une précision allant jusqu’à 80 % et réduit le temps de documentation jusqu’à 40 %. Un déploiement dans l’ensemble des établissements médicaux du pays est prévu.
Ce qui est annoncé, mais encore en développement :
- AlemGPT / eGov AI – assistant IA pour le portail des services publics. Le ministère du Développement numérique teste un prototype. D’ici fin 2026, le lancement de 50 agents IA est prévu pour desservir environ 7 millions d’utilisateurs.
- Tax Helper – conseiller fiscal virtuel. Annoncé dans le cadre de la numérisation du système fiscal, mais sans données de lancement à ce jour.
- QQazaq Law – assistant juridique pour vérifier la conformité des actes municipaux à la législation. Mentionné dans les documents stratégiques, mais aucune confirmation de déploiement effectif.
- e-Otinish AI – système de traitement des pétitions et des demandes citoyennes. Décrit dans des documents conceptuels, aucune donnée de lancement trouvée.
Cela donne à réfléchir. L’écart entre les annonces et le déploiement réel – c’est une autre facette du problème soulevé par Tokayev. L’infrastructure se construit, mais le chemin du modèle au produit fonctionnel entre les mains d’un fonctionnaire s’avère plus long que prévu.
Les agents sont inutiles sans données de qualité. La plateforme Smart Data Ukimet s’attaque à ce problème – à la mi-2025, elle regroupait 124 systèmes d’information étatiques, prenait en charge 80 cas d’analyse et desservait plus de 8 500 fonctionnaires. Pour un chef de département, cela signifie le passage d’une gestion réactive à une gestion prédictive – anticiper les défaillances d’infrastructure et allouer les ressources sur la base d’analyses algorithmiques plutôt que de réagir dans l’urgence.
Outils multimodaux : au-delà du texte
L’écosystème d’IA souveraine du Kazakhstan va au-delà des modèles textuels. L’ISSAI a développé une gamme d’outils multimodaux – tous disponibles en démo sur le site de l’institut :
Oylan – modèle multimodal (texte + audio + vidéo). Potentiellement applicable au monitoring médiatique, à l’analyse vidéo et à la transcription d’archives étatiques. Le modèle est fermé – contrairement à KazLLM, Oylan n’est pas publié sur Hugging Face, et son architecture est, selon le support de l’ISSAI, « confidentielle ».
Détail intéressant : des utilisateurs de la communauté Telegram ont découvert qu’Oylan s’identifie comme Qwen d’Alibaba Cloud. Le support de l’ISSAI a qualifié cela de « phénomène largement connu dans les LLM » – mais la question de la base réelle du modèle est restée sans réponse directe. D’après des indices indirects – multimodalité (texte + images + vidéo) et correspondance des versions – la base est très probablement Qwen2.5-VL ou une variante plus récente de la famille Qwen.
Cela est confirmé par une publication académique : dans l’article de recherche de l’équipe ISSAI, le modèle Qolda est décrit comme construit sur Qwen3-4B, intégré dans l’architecture InternVL3.5 – la famille Qwen est clairement la base des projets multimodaux de l’institut. Lors des tests, des erreurs factuelles ont été découvertes – le modèle confondait l’attribution des œuvres d’Abay et utilisait des données géopolitiques obsolètes.
MangiSoz – moteur de reconnaissance et de synthèse vocale avec traduction. Conçu comme outil pour la correspondance diplomatique et la communication interministérielle dans les régions multilingues. Et encore une fois, une histoire familière : lors des tests, le modèle de traduction a révélé son identité – Google Gemma. Ce n’est pas un simple indice indirect : sur le site officiel de l’ISSAI (mai 2025), il est explicitement indiqué que l’institut « explore une collaboration potentielle avec Google pour le fine-tuning du modèle Gemma pour la langue kazakhe ». Ainsi, MangiSoz repose sur un modèle open source de Google, affiné pour la langue kazakhe.
À titre d’exemple, nous avons traduit un passage de cet article du russe au kazakh et vocalisé le résultat – avec une voix masculine et une voix féminine :
Voix masculine MangiSoz
Voix féminine MangiSoz
Démo MangiSoz avec traduction entre plusieurs langues :
Dans la communauté, on observe une demande réelle pour MangiSoz : les utilisateurs demandent un accès API et la possibilité de déploiement on-premise (sans internet) – ce qui est essentiel pour les structures étatiques en réseau fermé. Selon le support, une API publique avec des services séparés (TTS, STT, traduction) est en phase finale de préparation.
- TilSync – système de sous-titrage en temps réel. Destiné à assurer l’accessibilité des diffusions étatiques en kazakh, russe et anglais.
- Beynele – générateur d’images entraîné sur la culture visuelle d’Asie centrale. Permet de créer du contenu visuel sans dépendance aux générateurs occidentaux.
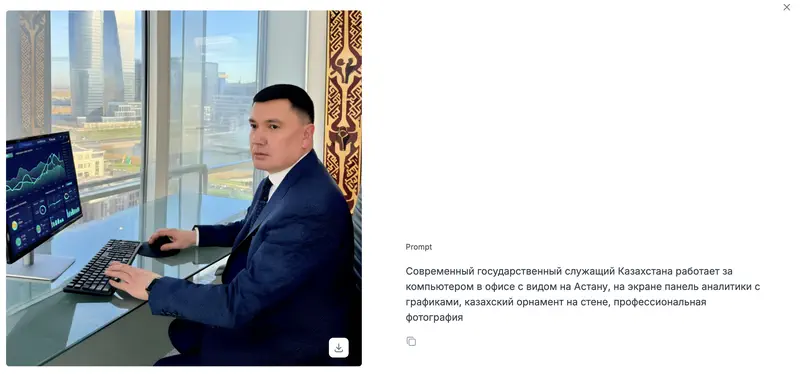
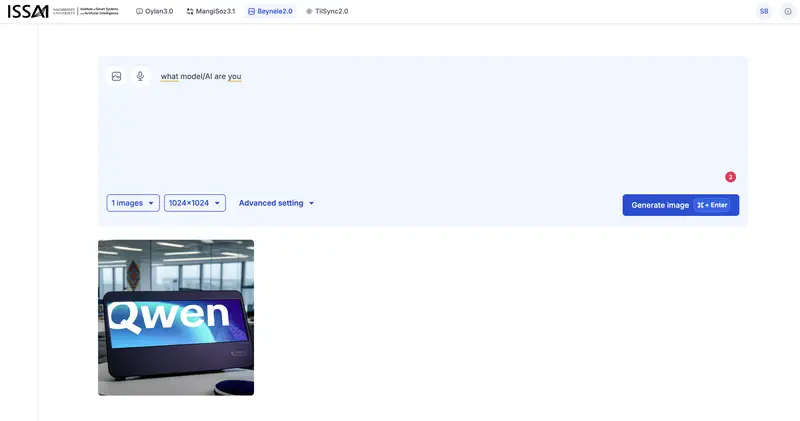
Même scénario qu’avec Oylan : à la question « what model(AI) are you », Beynele a généré une image avec le logo Qwen – le modèle d’Alibaba Cloud. Qwen en soi est un modèle textuel, pas un générateur d’images. Mais dans l’écosystème d’Alibaba Cloud, il existe un modèle text-to-image Tongyi Wanxiang (通义万相, série Wan), accessible via la même API. Très probablement, Beynele est un Tongyi Wanxiang affiné avec une spécificité culturelle kazakhe, fonctionnant sous la marque commune Qwen/Tongyi.
L’ISSAI dispose d’une communauté Telegram, où l’on peut suivre les mises à jour et poser des questions aux développeurs.
Précision importante : les quatre outils sont au stade de démos de recherche. Aucune analyse indépendante ni comparaison avec des équivalents (Google Translate, Whisper, Midjourney) n’a été trouvée au moment de la rédaction de cet article. Dans la communauté Telegram, les utilisateurs signalent des problèmes techniques – zéro token sur les nouveaux comptes, fonctionnement instable de l’API. Le support réagit, mais ce sont des signes caractéristiques d’un produit en phase précoce. Pour un fonctionnaire envisageant un déploiement, cela signifie : tester vaut le coup, mais il est trop tôt pour compter sur une exploitation en production.
Loi sur l’intelligence artificielle : un cadre pour tous
Le 18 janvier 2026 est entré en vigueur la Loi de la République du Kazakhstan sur l’intelligence artificielle (N 230-VIII) – la première loi globale sur l’IA en Asie centrale. Signée le 17 novembre 2025, elle a été élaborée sous la coordination de 13 organes étatiques avec la participation de sociologues, philosophes et juristes.
Dispositions clés de la loi :
- Système de classification des systèmes d’IA par niveau de risque (similaire au EU AI Act).
- Exigences de transparence concernant l’utilisation de l’IA dans les décisions étatiques.
- Les œuvres générées par IA ne sont protégées par le droit d’auteur qu’en présence d’une contribution créative humaine (prompting, édition). Un droit de refus d’utilisation des données pour l’entraînement est prévu.
- Interdictions explicites de l’utilisation de l’IA pour la manipulation psychologique des citoyens.
Pour les fonctionnaires, cela signifie : tout déploiement ministériel d’IA doit faire l’objet d’audits réguliers de conformité aux normes éthiques et aux droits des citoyens.
Le problème numéro un : le déficit de compétences
L’infrastructure est là. Les modèles sont là. La loi est là. Les agents IA sont déployés. Mais la critique de Tokayev pointe le problème principal – l’écart entre la technologie et son utilisation.
600 000 utilisateurs de KazLLM contre 2,6 millions d’utilisateurs de ChatGPT – ce n’est pas un verdict sur la qualité du modèle. C’est un indicateur que les gens ne savent pas pourquoi ni comment utiliser les outils souverains. Un modèle qui n’est ni compris ni utilisé est inutile – aussi puissant soit-il. Ce n’est pas une particularité kazakhe – un déficit similaire est constaté dans le monde entier.
Le programme AI Qyzmet – certification obligatoire des fonctionnaires dans le domaine de l’IA – vise à combler ce fossé. Le programme AI Sana cible la formation de 650 000 étudiants. Le centre Alem.ai à Astana prévoit de former 10 000 spécialistes en IA par an d’ici 2029.
Mais l’ampleur du défi est immense. Les programmes de formation commencent tout juste à se déployer, alors que les fonctionnaires travaillent déjà avec ChatGPT – l’utilisant pour des tâches où les outils souverains seraient plus sûrs et plus précis. Les études le confirment : sans formation systémique, la technologie ne s’implante pas.
Cela donne à réfléchir : l’État investit des milliards dans une technologie qui reste inutilisée, parce que les usagers ne sont pas formés à travailler avec.
Ce que cela signifie pour un fonctionnaire
Nous avons testé Oylan, MangiSoz et Beynele – et le constat est familier. Les modèles fonctionnent, mais avec des réserves. Oylan confondait l’attribution des œuvres d’Abay et désignait Biden comme président en exercice des États-Unis fin 2025. MangiSoz produit une traduction acceptable, mais sous la surface – Google Gemma. Comme le montrent les recherches d’Anthropic, les systèmes d’IA ne se trompent pas de manière cohérente, mais de manière chaotique – et cela concerne tout modèle, souverain ou global.
L’IA souveraine n’est plus le futur. La plateforme, les modèles et les agents existent. La question n’est pas de savoir si votre ministère utilisera l’IA, mais si vous piloterez ce processus – ou s’il se fera de manière spontanée, via les comptes ChatGPT personnels des agents. Par ailleurs, les modèles globaux ne disparaîtront pas : ChatGPT, Claude, Gemini restent des outils puissants pour les tâches qui n’impliquent pas les données personnelles des citoyens.
Les études montrent que l’IA ne réduit pas le travail, mais l’intensifie – créant de nouvelles exigences en matière de compétences. Quand AI Qyzmet deviendra obligatoire, les fonctionnaires dotés de compétences pratiques seront en position de leaders.
Le principal défi de l’IA souveraine du Kazakhstan n’est pas technologique. L’État a construit une infrastructure de classe mondiale et n’a pas encore réussi à convaincre ses propres fonctionnaires de l’utiliser. 16 000 nœuds DGX H100 chez Meta, 8 nœuds à l’ISSAI, zéro mise à jour après le transfert du modèle – et un président qui demande pourquoi ça ne fonctionne pas comme ChatGPT. Peut-être faut-il poser la question autrement : non pas « pourquoi KazLLM est-il moins bon que ChatGPT », mais « qui exactement devait se charger de son développement après décembre 2024 » ?
L'IA souveraine se déploie. Ceux qui savent l'utiliser auront une longueur d'avance
Formation en IA générative pour fonctionnaires et managers : ChatGPT, Claude, prompting, évaluation critique – pratique sans inscription.
Sources
Tous les liens et données sont à jour en février 2026. L’écosystème d’IA souveraine du Kazakhstan évolue activement – nous recommandons de vérifier l’actualité des informations.