Kimi de Moonshot en 2026 : K2.6, K2.7-Code et agents pour le manager

Un modèle chinois open source peut-il rivaliser avec les fleurons propriétaires d’OpenAI et d’Anthropic ? D’après notre évaluation indépendante – oui. Kimi de Moonshot AI a été le premier modèle chinois à rejoindre le groupe d’élite aux côtés des meilleurs modèles au monde – rivalisant directement avec GPT-5.4 et Claude Sonnet 4.5. Et il est entièrement gratuit pour un usage de base.
En 2026, Kimi est passé d’un modèle unique à toute une famille : le fleuron K2.6 pour le travail quotidien, la K2.7-Code spécialisée pour le développement, et l’agent de bureau Kimi Work, qui exécute des tâches directement sur votre ordinateur. Voici ce que cela apporte à un manager, les résultats de notre benchmark et comment y accéder.
Qui est Moonshot AI
Moonshot AI est une startup pékinoise fondée en 2023 par d’anciens collaborateurs de ByteDance (le créateur de TikTok). L’entreprise est soutenue par Alibaba et HongShan (anciennement Sequoia China). Le fondateur et CEO – Zhilin Yang – est chercheur spécialisé en NLP.
La startup a misé sur deux axes : le contexte long et les capacités agentiques. La première version de Kimi, en 2024, avait attiré l’attention grâce à une fenêtre contextuelle record pour l’époque. Début 2026, K2.5 a porté ces deux axes dans la ligue d’élite, avant d’être remplacée à l’été par K2.6 et la K2.7-Code dédiée au code.
Ce que sait faire Kimi
Tous les modèles Kimi reposent sur une architecture Mixture-of-Experts : 1 000 milliards de paramètres, mais seuls 32 milliards sont actifs à chaque instant. Cela permet de combiner puissance et efficacité – les réponses sont rapides et le coût via API est plusieurs fois inférieur à celui de Claude ou de GPT.
Caractéristiques clés :
- Fenêtre contextuelle de 256K tokens – soit environ 350 à 500 pages de texte par requête
- Multimodalité native – comprend le texte, les images et la vidéo nativement
- Quatre modes de fonctionnement : Instant (réponses rapides), Thinking (analyse approfondie), Agent (tâches autonomes avec outils) et Agent Swarm (travail parallèle de sous-agents – jusqu’à 100 sur K2.5 et jusqu’à 300 sur K2.6)
- Code ouvert – licence MIT, poids disponibles sur HuggingFace
Agent Swarm : la fonctionnalité phare
C’est une approche fondamentalement nouvelle. Au lieu de résoudre une tâche de manière séquentielle, Kimi peut la décomposer en sous-tâches et lancer des dizaines, voire des centaines de sous-agents spécialisés en parallèle (jusqu’à 300 sur K2.6, avec une coordination atteignant 4 000 étapes). Chaque sous-agent travaille indépendamment, tandis que l’agent principal coordonne le résultat.
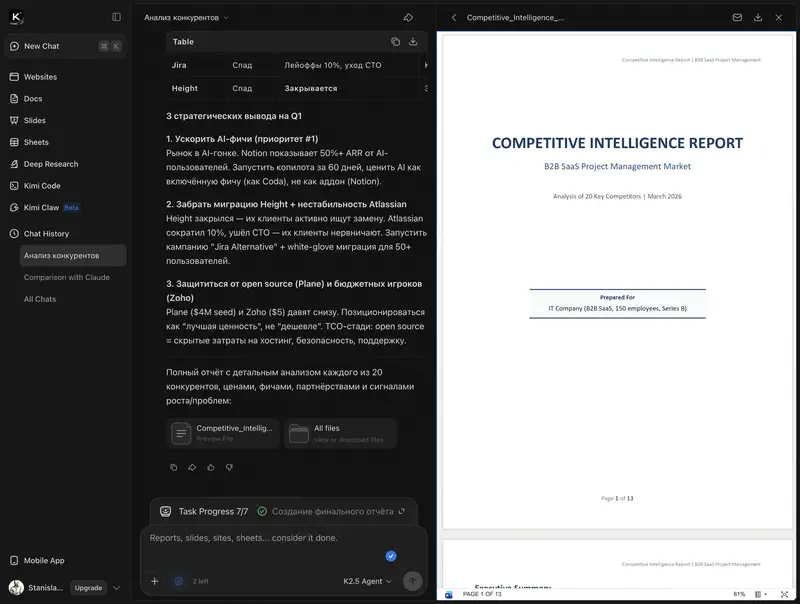
Pourquoi attendre 10 minutes quand on peut diviser la tâche en 100 flux ? En mode Swarm, Kimi K2.5 exécute une requête analytique complexe en 2 à 3 minutes au lieu de 10. Au test BrowseComp (navigation et recherche web), Agent Swarm a obtenu 78,4 % – le meilleur score parmi tous les modèles testés, y compris GPT-5.2.
Par ses capacités, Kimi peut rivaliser notamment avec Notebook LM de Google. Pour les présentations interactives – le résultat est plutôt convaincant au premier abord. Certes, les données datent de l’année dernière.
Pour un manager, c’est pertinent dans des scénarios comme « analyse 10 sites concurrents et produis une synthèse » ou « prépare un rapport à partir de plusieurs sources ».
Ce que montrent les benchmarks
Sur les benchmarks industriels standard, Kimi K2.5 rivalise solidement avec les meilleurs modèles propriétaires :
| Benchmark | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | DeepSeek V3.2 |
|---|---|---|---|---|
| HLE avec outils | 50,2 % | 45,5 % | 43,2 % | 40,8 % |
| BrowseComp (Agent Swarm) | 78,4 % | 54,9 % | 24,1 % | 67,6 % |
| SWE-Bench Verified (code) | 76,8 % | 80,0 % | 80,9 % | 73,1 % |
| AIME 2025 (maths) | 96,1 % | 100,0 % | 92,8 % | 93,1 % |
| VideoMMMU (vidéo) | 86,6 % | 85,9 % | 84,4 % | – |
Kimi K2.5 domine en tâches agentiques (recherche, navigation, travail autonome) et en compréhension vidéo. En programmation, il cède face à Claude ; en mathématiques – face à GPT-5.2. Mais il s’agit d’écarts de 3 à 4 points de pourcentage, pas d’un gouffre.
Comme toujours, benchmarks et usage réel – ce sont deux choses différentes. Mais la tendance est claire : Kimi K2.5 joue dans la même ligue que les fleurons.
La gamme Kimi : K2.5, K2.6 et K2.7-Code
Aujourd’hui, la gamme Kimi compte trois modèles. La K2.5 de base a cédé la place à la K2.6 incrémentale (celle qu’on retrouve dans le sélecteur de modèles de Perplexity), et le 12 juin est sortie K2.7-Code. Attention à ne pas confondre : K2.7-Code est un modèle spécialisé pour le code ; elle n’est pas prévue pour le chat quotidien.
Ce qui rend K2.7-Code intéressante :
- Conçue pour le développement long-horizon : planifie, édite, exécute des outils et débogue le code sur plusieurs étapes en une boucle. Pour les tâches de gestion ordinaires, restez sur K2.5/K2.6.
- Architecture et contexte – 1 000 milliards de paramètres, 32 Md actifs (MoE), fenêtre de 256K tokens, poids ouverts (MIT modifiée) sur Hugging Face, via l’API Kimi et Kimi Code.
- ~30 % de « tokens de raisonnement » en moins que K2.6 – une boucle agentique qui consommait ~1 000 tokens pour réfléchir à une modification en consomme désormais ~700. À l’échelle, c’est une économie directe.
- Appels d’outils fiables via MCP – elle invoque les outils externes via le protocole de façon fiable : vérifications CI, mises à jour de tickets et modifications multi-fichiers en une seule passe.
Prix – 0,75 $ / 3,50 $ par million de tokens entrée/sortie : assez bon marché pour faire tourner un agent de code au quotidien.
Prudence avec les chiffres : tous les résultats publiés de K2.7-Code sont des benchmarks maison de Moonshot (Kimi Code Bench v2 : de 50,9 à 62,0 ; MCP Mark Verified 81,1 contre 76,4 pour Claude Opus 4.8). Aucun résultat indépendant sur des suites publiques au lancement – comme dans l’histoire de GLM-5.2, les victoires annoncées par l’éditeur méritent vérification.
Pour les managers : si votre équipe écrit du code, K2.7-Code vaut un test comme agent-développeur peu coûteux ; pour le texte, l’analyse et la communication, K2.5/K2.6 restent – ce sont elles que nous avons testées dans le benchmark ci-dessous.
Kimi Work et OK Computer : Kimi comme agent
Au-delà des modèles, Moonshot développe des produits agentiques – ici Kimi concurrence directement Perplexity Computer et Claude Cowork.
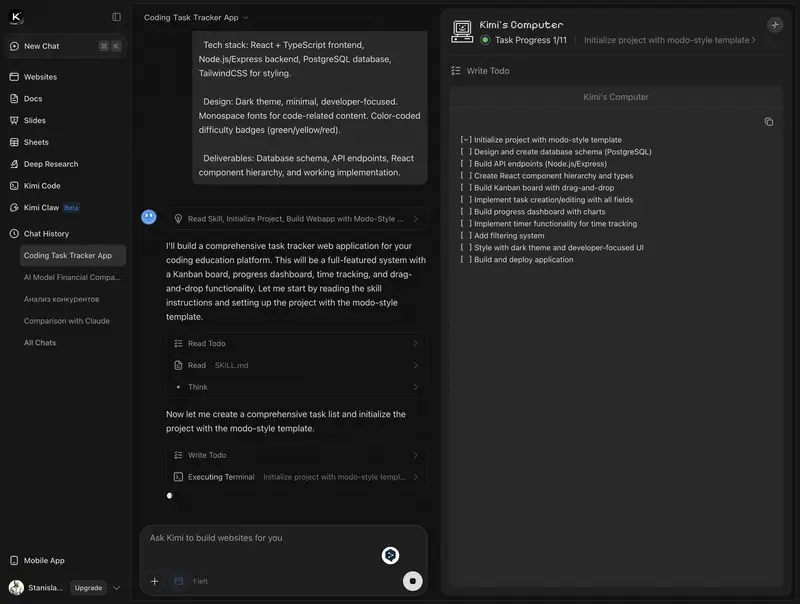
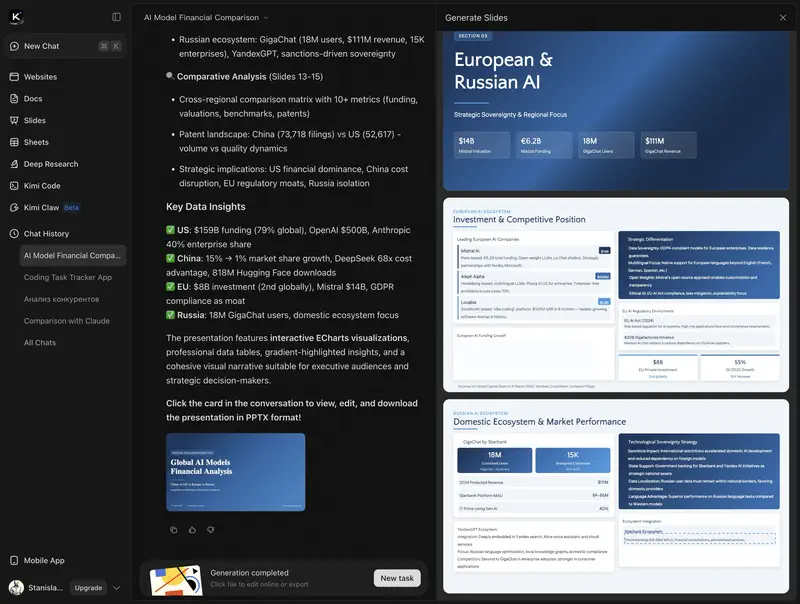
- OK Computer – mode agent directement dans le chat Kimi : à partir d’un prompt, il construit des sites multi-pages et des diapositives éditables prêtes à l’emploi, traite jusqu’à 1 M de lignes de données d’un coup et produit texte, audio, images et vidéo. Pour un manager : un premier jet de présentation, de landing page ou de rapport de données en un seul prompt.
- Kimi Work – application de bureau (macOS Apple silicon et Windows) tournant sur K2.6, qui agit sur votre propre ordinateur. Vous fixez un objectif en mots ; l’agent mène la recherche, en tire une note de marché en diapositives prêtes (sections en parallèle) et, via l’extension WebBridge, utilise votre navigateur comme un humain : cherche, fait défiler, extrait des données, remplit des formulaires. À l’intérieur, le même Agent Swarm, jusqu’à 300 sous-agents.
Pour les managers : Kimi Work et OK Computer transforment Kimi d’un chat en « employé numérique » – briefez-le le soir, récupérez un brouillon de note ou de présentation au matin. Réserve principale : les données sont traitées par un service chinois, à prendre en compte pour les informations sensibles.
Résultats de notre benchmark
Dans notre benchmark indépendant – où nous testons les modèles sur des tâches managériales réelles dans plusieurs catégories – Kimi K2.5 s’est solidement installé dans le groupe d’élite, parmi les tout meilleurs modèles disponibles. Il rivalise directement avec GPT-5.4 et Claude Sonnet 4.5 – ce qui est remarquable pour un modèle open source et gratuit.
Kimi K2.5 est performant dans presque toutes les catégories : communication, planification, analyse, formation et développement, résolution de problèmes. Pas de point faible marqué – le modèle offre une qualité élevée et constante quel que soit le type de tâche. Cette régularité est d’ailleurs l’un de ses traits distinctifs : là où la plupart des modèles montrent des hauts et des bas selon les catégories, Kimi reste remarquablement stable.
Pour les utilisateurs qui souhaitent une qualité de pointe sans souscrire un abonnement, Kimi K2.5 est l’option gratuite la plus performante. C’est un modèle véritablement d’élite, utilisable sur kimi.com sans dépenser un centime – une alternative remarquable à ChatGPT Plus et Claude Pro.
Comment se situe-t-il par rapport aux autres modèles chinois ? MiniMax M2.7 est très proche et excelle en management d’équipe. MiMo V2 Omni de Xiaomi se distingue dans les scénarios d’apprentissage. Qwen3.5 Plus affiche de solides performances, à peine en retrait. Mais globalement, Kimi K2.5 occupe la première place parmi les modèles chinois – et surpasse nettement tous les modèles russes (GigaChat, YandexGPT).
Consultez nos résultats interactifs complets avec les comparaisons détaillées de DeepSeek et Qwen.
Résultats interactifs complets →
Kimi K2.5 face aux autres modèles chinois
Pour un manager qui choisit parmi les outils disponibles, la comparaison au sein du « groupe chinois » importe davantage qu’une compétition abstraite avec Claude.
| Modèle | Point fort | Accès chat | Coût |
|---|---|---|---|
| Kimi K2.5 | Polyvalence, recherche | kimi.com | Gratuit / 18–185 €/mois |
| MiniMax M2.7 | Management d’équipe | minimaxi.com | Gratuit |
| Qwen3.5 Plus | Planification | chat.qwen.ai | Gratuit (API uniquement) |
| MiMo V2 Omni (Xiaomi) | Scénarios d’apprentissage | mimo.xiaomi.com | Gratuit |
| GLM-5 (Z.ai) | Management d’équipe | chat.z.ai | Gratuit (API uniquement) |
| DeepSeek V3.2 | Rapport qualité-prix | chat.deepseek.com | Gratuit (API uniquement) |
| Qwen3 Max | Raisonnement | chat.qwen.ai | Gratuit (API uniquement) |
Conclusions du tableau :
Kimi K2.5 est le meilleur modèle chinois en termes globaux. Il domine sur le plus large éventail de catégories de tâches managériales, sans point faible significatif.
Mais il n’est pas le meilleur dans chaque catégorie. MiniMax M2.7 le devance en management d’équipe. DeepSeek V3.2 offre le meilleur rapport qualité-prix. Qwen3.5 Plus est plus performant en planification.
En termes d’accessibilité, Kimi se distingue. C’est l’un des rares modèles d’élite disposant d’un chat entièrement gratuit. Les plans payants de Kimi (18–185 €/mois) débloquent des capacités agentiques que les concurrents ne proposent tout simplement pas dans leur interface de chat.
Comment accéder à Kimi K2.5
Interface web : kimi.com
Le site kimi.com est accessible depuis l’Europe sans restriction. Connexion via compte Google – c’est la méthode la plus simple et la plus rapide.
L’interface est disponible en anglais et en chinois uniquement – pas de version française. Mais le modèle comprend le français et répond en français. La qualité des réponses en français est toutefois inférieure à celle en anglais (comme pour tous les modèles chinois), mais suffisante pour la majorité des cas d’usage.
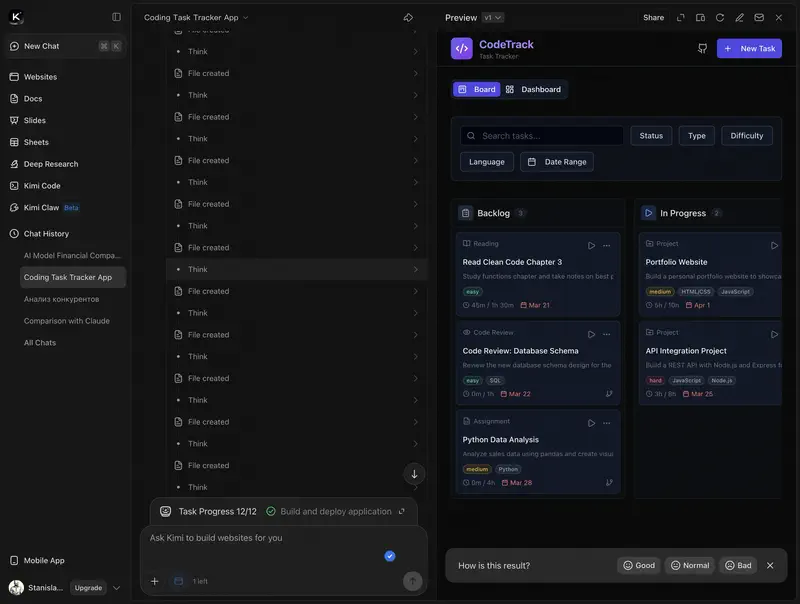
Trois modes de fonctionnement principaux :
- Instant – réponses rapides pour les tâches quotidiennes : correspondance, réponses aux questions, travail sur documents
- Thinking – analyse approfondie avec « chaîne de raisonnement », le modèle montre son processus de réflexion
- Agent – exécution autonome de tâches : génération de documents (.docx, .pdf, .xlsx), recherche web, opérations multi-étapes. Si vous demandez un rapport avec tableaux – c’est précisément ce mode
Note RGPD : Kimi K2.5 est un service de la société chinoise Moonshot AI. Les données transmises peuvent être traitées sur des serveurs hors de l’UE. Pour un usage professionnel impliquant des données sensibles ou personnelles, vérifiez la conformité avec la politique de protection des données de votre organisation. Pour des tâches générales d’analyse, de rédaction ou de recherche – le risque est comparable à celui des autres services IA cloud.
Applications mobiles
Kimi est disponible sur iOS et Android. Les fonctionnalités sont identiques à la version web, y compris tous les modes de fonctionnement.
Accès API
L’API Moonshot est accessible directement depuis l’Europe. Kimi K2.5 est également disponible via des agrégateurs comme OpenRouter, ce qui simplifie l’intégration et la facturation.
Tarifs et abonnements
Niveau gratuit (Adagio)
- Requêtes textuelles illimitées en modes Instant et Thinking
- Jusqu’à 3 requêtes par mois aux agents (documents, tableaux, présentations)
- 1 requête Deep Research par mois
- File d’attente aux heures de pointe
Le niveau gratuit suffit pour tester le modèle et déterminer s’il convient à vos besoins. Pour un usage quotidien – c’est trop limité.
Plans payants
| Plan | Prix | Ce qu’il offre |
|---|---|---|
| Moderato | ~18 €/mois ($19) | Plus de requêtes agentiques, priorité, génération de présentations |
| Allegretto | ~36 €/mois ($39) | Limites encore plus élevées, multitâche des agents, accès à Kimi Claw |
| Vivace | ~185 €/mois ($199) | Agents illimités, vitesse maximale, contexte étendu |
La tarification est en USD, payable par carte bancaire internationale (Visa, Mastercard). Les prix en euros ci-dessus sont indicatifs.
Coût via API
| Option | Tokens en entrée | Tokens en sortie | ~Coût d’analyse d’un rapport de 100 pages |
|---|---|---|---|
| Moonshot API (direct) | $0,60 / 1M | $3,00 / 1M | ~$0,50 |
| OpenRouter | $0,45 / 1M | $2,20 / 1M | ~$0,35 |
Pour comparaison : Claude Opus 4.5 pour une tâche équivalente – environ $3, GPT-5.2 – $1,50. Kimi K2.5 est 6 à 8 fois moins cher que Claude.
Mais parmi les modèles chinois, Kimi n’est pas le plus économique. DeepSeek V3.2 coûte 3 fois moins, Qwen3.5 Plus – 1,5 fois moins.
Limites et risques
Qualité linguistique en français – faiblesse prévisible. Comme GLM-5, Kimi K2.5 fonctionne nettement mieux en anglais et en chinois. En français, le modèle se débrouille, mais avec une perte de nuances. Si la tâche le permet – formulez vos prompts en anglais.
Vitesse de réponse – Agent Swarm est rapide pour les tâches complexes, mais le mode Thinking classique est plus lent que Claude et GPT. Lors d’un test indépendant, le temps de réponse médian de Kimi K2.5 était de 29,2 secondes contre 4,6 pour Claude Sonnet 4.6. Cela fait réfléchir : si Agent Swarm promet la vitesse par le parallélisme, pourquoi le mode classique est-il 6 fois plus lent que la concurrence ? Pour des requêtes ponctuelles, c’est tolérable ; en usage intensif – c’est perceptible.
Censure chinoise – fonctionne comme pour les autres modèles chinois : les sujets politiquement sensibles sont bloqués. Pour des tâches managériales, cela pose rarement problème.
Résidence des données (RGPD) – les données sont traitées sur des serveurs de Moonshot AI, probablement hébergés en Chine. Pour des données à caractère personnel ou confidentiel, évaluez la conformité avec votre politique interne et le RGPD. Privilégiez l’API avec des données anonymisées pour les cas d’usage sensibles.
Taille du modèle – 1 000 milliards de paramètres signifie qu’héberger Kimi K2.5 sur vos propres serveurs est irréaliste pour une entreprise classique. Ce n’est pas Qwen3.5 9B, que l’on peut déployer sur un seul GPU.
Faut-il l’essayer ?
Kimi est objectivement la gamme de modèles chinois la plus forte de 2026. Performance de niveau élite, technologie Agent Swarm unique et accès de base entièrement gratuit – le tout confirmé par des tests indépendants.
Pour un manager, la recommandation dépend du contexte. Si vous avez besoin d’un outil polyvalent avec une recherche performante, de l’analyse et des capacités agentiques – Kimi K2.5 mérite d’être testé. Surtout si vos tâches impliquent de travailler avec plusieurs sources, de préparer des rapports ou de mener des recherches multi-étapes.
Si le prix est votre critère principal – DeepSeek V3.2 reste le choix le plus économique, à un coût trois fois inférieur. Si votre priorité est le management d’équipe, les tâches RH et le feedback – GLM-5 reste n°1 dans cette catégorie.
Fait notable : le modèle chinois le plus performant de 2026 n’est pas celui qui a fait le plus de bruit en début d’année. Kimi K2.5 a dépassé DeepSeek et Qwen sans déclarations tapageuses. Cela amène à se demander : dans quelle mesure le battage médiatique est-il un indicateur fiable pour choisir un outil de travail ?
Rendez-vous sur kimi.com, connectez-vous via Google et consacrez une heure aux tests. Le niveau gratuit suffit pour vous forger votre propre opinion.
Nous analysons Kimi K2.5 et d'autres outils IA en pratique
9 leçons diagnostiques : essayez Kimi K2.5 et d'autres modèles sur des tâches réelles – et découvrez les erreurs que commettent la plupart des managers. Sans inscription.
Continuez votre apprentissage
Ouvrez le manuel et reprenez là où vous vous êtes arrêté










Stanislav Belyaev
Engineering Leader chez Microsoft18 ans a diriger des equipes d'ingenieurs. Fondateur de mysummit.school. 700+ diplomes chez Yandex Practicum et Stratoplan.