LLM locaux pour managers : ce que vous pouvez vraiment faire tourner chez vous

Toute personne qui travaille suffisamment longtemps avec ChatGPT ou Claude finit tôt ou tard par se poser cette question : est-il possible de faire tourner quelque chose de comparable directement sur son ordinateur portable – sans abonnement, sans fuite de données, sans dépendre de serveurs distants ?
En 2026, la réponse est oui, mais avec des nuances qui comptent plus que la réponse elle-même.
Cet article s’adresse à celles et ceux qui utilisent déjà des LLM en cloud et veulent comprendre ce qu’apporte réellement l’exécution locale, quel matériel il faut, et où les attentes se heurtent à la réalité. Sans plongée technique, mais avec des chiffres concrets.
Pourquoi faire tourner un modèle en local, au juste
Avant de parler matériel, il vaut mieux répondre à une question plus importante.
Les services cloud ont trois limites réelles que l’on ressent en pratique : la confidentialité des données (vous n’êtes pas toujours certain que vos échanges clients ne sont pas indexés), la dépendance à la disponibilité (ChatGPT tombe aux heures de pointe, Claude a des limitations régionales), et le coût dès que l’usage devient intensif.
Un modèle local règle ces trois points d’un coup : les données ne quittent pas votre machine, cela fonctionne hors-ligne, et après le téléchargement initial cela ne coûte rien. C’est sa vraie valeur – et non pas « GPT-5 gratuit à la maison », ce qui serait faux.
Reste à savoir à quel prix – en termes de matériel et de qualité des réponses.
De quoi parle-t-on : les modèles et leur taille
La taille d’un modèle de langage se mesure en milliards de paramètres – les nombres que le modèle a « mémorisés » pendant son entraînement. On utilise la lettre B : 7B, 14B, 70B.
Pour un manager, ce n’est pas un terme technique mais un indice pratique : combien de mémoire vive il faut pour que le modèle démarre.
Règle approximative : un modèle occupe environ un gigaoctet et demi de mémoire par milliard de paramètres en compression 4 bits. Un modèle 7B pèse donc environ 5 Go, un 14B près de 9 Go, un 32B autour de 20 Go, et ainsi de suite. Sur un portable doté de 16 Go de RAM, tout ce qui dépasse 14B ne tiendra plus entièrement dans la mémoire rapide – le modèle se met à « swapper » et ralentit sensiblement.
La quantification, c’est précisément cette compression. Le modèle d’origine stocke des nombres en haute précision ; la quantification réduit cette précision pour diviser la taille par 2 à 4. Une petite perte de qualité en échange de la possibilité de faire tourner le modèle tout court.
Pour donner l’échelle : les modèles phares du cloud comme Claude Sonnet 4.6 et GPT-5.4 ne divulguent pas officiellement leur nombre de paramètres, mais selon les estimations de l’industrie on parle de centaines de milliards, voire de milliers de milliards de paramètres dans une architecture Mixture-of-Experts. Même si seule une partie est active (disons 30 à 50B par requête), le poids total du modèle se compte en téraoctets et exige un datacenter équipé de dizaines d’accélérateurs spécialisés. Un modèle local 8B sur un portable, c’est environ 1 % de la taille d’un modèle phare du cloud. D’où l’écart de qualité sur les tâches complexes : pas parce que les auteurs de modèles locaux sont moins bons, mais parce que l’échelle diffère de deux ordres de grandeur. Ci-dessous un graphique du nombre de paramètres des modèles que vous pouvez faire tourner localement ou en cloud, via Epoch AI.
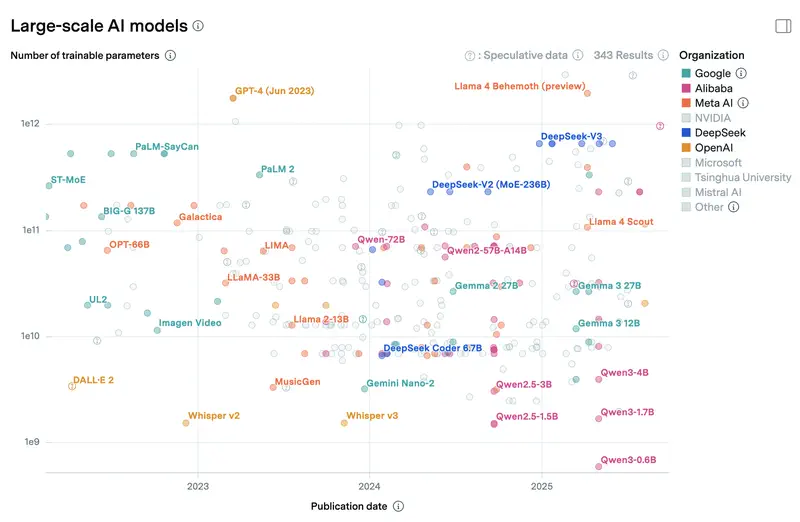
Quels modèles sont pertinents en avril 2026
Le paysage des modèles ouverts évolue plus vite que la plupart des politiques internes des entreprises. Le tableau d’avril 2026 réserve des surprises à ceux qui ont suivi l’actualité de l’IA dans la presse occidentale : en première ligne, on trouve non seulement Meta et Google, mais aussi toute une série de laboratoires chinois et une surprise signée OpenAI.
DeepSeek V3.2 – le leader incontesté parmi les modèles ouverts. Un MoE 671B avec 37B de paramètres actifs par requête, sorti en décembre 2025, fenêtre de contexte de 163 000 tokens. Nous avons analysé DeepSeek en détail : sur les tâches managériales, il se place régulièrement dans le cluster de tête. Pour un usage local, le V3.2 complet est hors de portée – impossible à déployer sur du matériel personnel. En revanche, les distillats basés sur lui (7B, 14B) tournent avec 8 Go de VRAM et se montrent nettement plus solides que les modèles locaux classiques de même taille sur les tâches d’analyse et de logique.
La famille Qwen d’Alibaba – deuxième axe majeur parmi les modèles exécutables en local. Qwen 3.5 est sorti entre février et mars 2026 et couvre une gamme allant de 0,8B au modèle phare 397B MoE, non destiné à un usage local. Pour la maison, les tailles clés sont 27B dense (~16 Go de VRAM en Q4, exécutable sur un GPU 8 Go), 9B et 4B. Le 2 avril est sorti Qwen 3.6-Plus en architecture MoE avec un contexte d'1 million de tokens. Dans notre revue Qwen, la famille s’est distinguée : Qwen brille sur les tâches multilingues, y compris au-delà de l’anglais – un paramètre important en pratique pour les managers qui travaillent dans plusieurs langues.
Les laboratoires chinois sont devenus, dans l’ensemble, une véritable alternative aux modèles phares occidentaux. Parmi les modèles ouverts les plus remarquables de cette sphère :
- Xiaomi MiMo-V2-Pro (mars 2026) – un modèle de raisonnement, contexte d'1 million de tokens.
- MiniMax M2.5 et M2.7 (février-mars 2026) – grands modèles MoE avec un contexte de 196 000 tokens.
- Z.ai GLM 5.1 (7 avril 2026) – la sortie la plus fraîche de cette liste, contexte de 202 000 tokens.
- MoonshotAI Kimi K2.5 (janvier 2026) – contexte de 262 000 tokens.
- StepFun Step 3.5 Flash (janvier 2026) – plus compact que les autres, mais largement utilisé dans les pipelines.
Aucun de ces modèles ne peut tourner sur un portable – ils fonctionnent via API ou en self-hosted sur du matériel sérieux (64 Go de mémoire ou plus, configurations multi-GPU). Mais ils montrent où se situe réellement le marché de l’IA ouverte.
gpt-oss-120b d’OpenAI (août 2025) – cas rare où OpenAI a publié des poids ouverts. Un modèle MoE 120B toujours très utilisé huit mois après sa sortie. Pour le faire tourner en local, il faut un Mac Studio avec 64 Go ou plus, ou une station de travail avec deux cartes graphiques.
Gemma 4 26B A4B de Google – c’est la version de Gemma qui est réellement utilisée en pratique. Pas le 31B, pas le 12B, mais bien le 26B en architecture MoE avec 4 milliards de paramètres actifs par requête – d’où le « A4B » dans le nom. Contexte de 262 000 tokens, il tourne via Ollama sur un portable de 16 Go de RAM plus vite que ses équivalents dense de la même classe. La version 4B tourne sur un téléphone via Google AI Edge Gallery.
NVIDIA Nemotron 3 Super – contexte de 262 000 tokens, disponible gratuitement sur OpenRouter. Choix populaire pour les expérimentations avec des agents et des pipelines, lorsqu’il s’agit de ne pas payer à chaque requête.
Mistral Nemo – un modèle compact pour l’inférence sur CPU. Plus modeste que les leaders, mais dans la catégorie « tourne sans carte graphique », c’est un vrai cheval de trait.
Mentionnons à part les modèles abondamment discutés dans les publications techniques mais moins présents dans l’usage courant : Llama 4 Scout, Llama 3.3 70B, Phi-4, Mistral Small 3.1. On les retrouve souvent dans les installations self-hosted – là, le choix se fait par intégrations et habitudes plus que par popularité.
Quel matériel il faut et ce que vous obtenez
C’est ici que les attentes et la réalité divergent le plus.
Option minimale : n’importe quel portable moderne avec 16 Go de RAM
Un portable avec 16 Go de RAM et sans carte graphique fera tourner des modèles jusqu’à 8-10B via llama.cpp ou Ollama, en s’appuyant sur le processeur classique. Ça fonctionne – mais lentement.
La vitesse de génération sur CPU se situe entre 3 et 8 tokens par seconde. ChatGPT, lui, produit du texte à environ 40-80 tokens par seconde (c’est ce que vous percevez comme « ça tape vite »). 8 tokens par seconde, c’est à peu près un ou deux mots toutes les deux secondes. Pour les réponses longues, on a l’impression d’un ralenti. Utilisable, mais pas toujours confortable.
Pour des tâches simples – résumer un texte court, répondre à une question précise – c’est parfaitement tolérable. Pour un dialogue itératif, cela devient vite fastidieux.
Option correcte : puces Apple M-series ou RTX 3060 12 Go
C’est le seuil à partir duquel un LLM local commence à ressembler à un véritable outil, et non plus à une démonstration technologique.
Un Mac équipé d’une puce M3, M4 ou M5 avec 16 à 32 Go de mémoire unifiée est sans doute la meilleure plateforme pour les LLM locaux aujourd’hui. La raison : l’architecture unifiée, où le CPU et le GPU partagent la même mémoire, permet de faire tourner rapidement des modèles sans carte graphique dédiée. Le framework MLX d’Apple, optimisé pour ces puces, fonctionne 20 à 30 % plus vite que llama.cpp standard sur le même matériel.
Qwen 3.5 9B sur un M3 Pro produit environ 25-35 tokens par seconde. Gemma 4 26B A4B (MoE avec 4B actifs) sur un M4 Max atteint 30-45 tokens par seconde avec une capacité effective du modèle bien supérieure. Un Mac avec 32 Go tient sans peine 15-30 tokens par seconde sur la classe 13B, et 25-50 tokens sur des modèles 27-32B avec 64 Go. À ce stade, c’est une vitesse de chat tout à fait normale. Depuis mars 2026, Ollama est officiellement passé à MLX comme backend principal sur Apple Silicon – autrement dit, en installant simplement Ollama sur un Mac récent, vous bénéficiez déjà des performances optimisées.
La RTX 3060 12 Go – pour les utilisateurs Windows, c’est la voie la plus accessible pour rejoindre la même ligue. La carte d’occasion coûte entre 200 et 300 EUR, et 12 Go de VRAM suffisent à faire tourner confortablement des modèles 7B et 14B. Gemma 4 26B A4B tient aussi dans 12 Go grâce à l’architecture MoE. Qwen 3.5 27B dense ne tient pas en entier dans 12 Go, mais Qwen 3.5 9B produit environ 20-40 tokens par seconde sur une RTX 3060. Côté vitesse, on est à peu près au niveau d’un bon Mac.
Nuance importante sur le terme. L’inférence, c’est le processus par lequel un modèle déjà entraîné répond à votre requête (par opposition à l’entraînement, où on ajuste le modèle sur des données). L’inférence GPU signifie que le modèle tourne sur la carte graphique et non sur le processeur. La carte graphique multiplie les matrices en parallèle dix à plusieurs dizaines de fois plus vite qu’un CPU, et pour les modèles de langage cela fait la différence entre « délai d’une seconde » et « minute d’attente ».
Pour l’inférence GPU, c’est bien la mémoire vidéo (VRAM) qui compte, pas la RAM classique. Les 12 Go de VRAM de la RTX 3060 sont bien 12 Go dédiés au modèle. Si le modèle n’entre pas dans la VRAM, une partie est déchargée en RAM et la vitesse chute d’un facteur plusieurs.
Pour voir concrètement ce que vous obtenez selon la taille du modèle, comparez trois exécutions sur une même tâche : Gemma 4 26B A4B (le Gemma le plus populaire sur OpenRouter, exécutable sur un portable grâce au MoE), gpt-oss-120b (poids ouverts d’OpenAI, nécessite un Mac Studio ou deux cartes graphiques) et DeepSeek V3.2 (modèle phare cloud de l’écosystème ouvert, ~37B actifs en MoE) :
En pratique, Gemma 4 26B A4B produira une réponse structurée, distinguant les deux cas – mieux qu’un modèle 8B typique, mais la conclusion systémique reste généralement prévisible. gpt-oss-120b proposera une stratégie plus nuancée et posera des questions de clarification pertinentes, même si la profondeur dépend de la requête précise. DeepSeek V3.2, au niveau d’un modèle phare cloud, livrera une structure avec priorisation, des délais réalistes et une observation non triviale sur les quatre restants. C’est précisément cette différence que l’on paie en cloud.
Option avancée : 70B et au-delà
La classe 70B en compression 4 bits occupe environ 48 Go de mémoire (40 Go et plus pour la pleine qualité). Il faut un Mac Studio avec 64 Go, un serveur avec plusieurs cartes graphiques ou une station de travail avec une RTX 4090 24 Go couplée à de la mémoire supplémentaire. La RTX 4090 tient Gemma 4 26B A4B et les modèles dense jusqu’à 31B, à 50-85+ tokens par seconde. gpt-oss-120b n’entre pas dans cette catégorie – un MoE 120B exige 64 Go et plus de mémoire unifiée, ou deux cartes.
La vitesse, à ce stade, tourne autour de 8-15 tokens par seconde. La qualité s’approche de GPT-5 Mini. Mais le ticket d’entrée démarre à environ 1 500-2 000 EUR de matériel. Ce n’est plus « essayer à la maison », c’est un investissement réfléchi avec une justification concrète.
20 tokens par seconde – c’est rapide ou lent ?
C’est une question qu’on explique rarement de façon claire.
Un token, c’est à peu près 3/4 d’un mot en anglais, un peu moins en français selon la longueur des mots. Vingt tokens par seconde, cela fait environ 15 mots par seconde, soit à peu près 900 mots par minute. À titre de comparaison : un lecteur moyen lit 200-300 mots par minute.
Vingt tokens par seconde – c’est rapide. Vous lirez plus lentement que le modèle n’écrit. Expérience agréable.
Huit tokens par seconde – environ 6 mots par seconde. Encore lisible, mais on sent la pause sur les phrases longues. Acceptable pour les tâches sans urgence.
Trois tokens par seconde – c’est quasiment une sortie ligne à ligne. Une réponse longue prend un temps notable. On peut travailler, mais oubliez le dialogue continu.
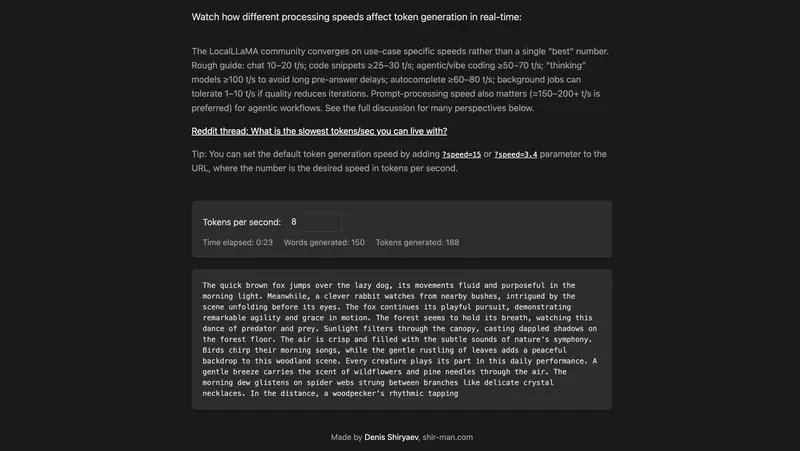
Chacun des chiffres ci-dessus est un lien cliquable vers le simulateur shir-man.com/tokens-per-second, où le texte apparaît en temps réel à la vitesse choisie. Une minute d’expérimentation vaut mieux qu’une longue description.
Pour référence : GPT-5 produit 40-80 tokens par seconde selon la charge serveur. En heures creuses, plus vite ; aux heures de pointe, plus lentement. Une bonne installation locale est tout à fait comparable en perception.
Il y a une nuance importante dont on parle peu : sur les modèles de raisonnement (reasoning), la vitesse d’affichage n’est que la moitié de l’histoire. Avant de commencer à répondre, un tel modèle peut « réfléchir » plusieurs minutes en interne – en générant une chaîne de raisonnement cachée que vous ne voyez pas. Un modèle de raisonnement local sur un portable peut passer 5 à 10 minutes en analyse interne, puis une minute à afficher la réponse à 20 tokens par seconde. À l’écran, cela ressemble à ceci : vous posez une question, le curseur clignote, rien ne se passe – le modèle travaille. C’est normal en mode reasoning, mais il faut y être préparé. En cloud, la même chose se produit en 10 à 30 secondes grâce à la puissance du datacenter. Pour un dialogue itératif, la différence est critique ; pour une tâche de fond (« réfléchis pendant que je prends un café »), beaucoup moins.
Qualité : une comparaison honnête
C’est ici qu’il faut faire attention aux attentes.
Un modèle local 8B n’égale pas GPT-5 ni Claude Sonnet. Autant le comprendre avant le téléchargement, pas après. Dans notre classement de 54 modèles sur les tâches managériales, GPT-5.4 obtient 4,8 sur 5, Claude Sonnet 4.5 4,78, Gemini 2.5 Pro 4,46. Un modèle local 8B typique se situerait entre 2,8 et 3,3 – là où figurent, dans le même classement, GigaChat-Ultra (3,26) et Llama 4 Maverick (2,95). Pas parce qu’ils sont mauvais – c’est simplement une autre catégorie de tâches.
Les modèles concrètement exécutables en local, dans notre benchmark, se présentent ainsi : Gemma 3 12B obtient 3,58 (cluster 3), Qwen3 32B 3,67, Gemma 3 27B 3,75. C’est déjà plus intéressant : à peu près le niveau d’Alice AI de Yandex (3,86) ou légèrement en dessous. Phi-4, le modèle 3,8B de Microsoft largement recommandé pour son « intelligence » sur les tests synthétiques, n’obtient que 2,27 – dernière place parmi les 54 modèles. Un rappel que les benchmarks synthétiques et les tâches managériales sont deux choses différentes. Consultez notre benchmark avant de choisir un modèle.
Pour les 70B et plus, le tableau change. Les modèles de cette classe n’ont pas été testés directement dans le benchmark, mais leurs paramètres les rapprochent du cluster 3 – approximativement dans la zone 3,5-3,8, soit le niveau de Qwen3 32B ou un peu au-dessus. C’est déjà un outil sérieux pour la plupart des tâches quotidiennes. L’écart avec Claude Sonnet ou GPT-5 subsiste sur les tâches qui demandent une compréhension contextuelle profonde ou des déductions à plusieurs étapes – mais pour résumer des documents, préparer des brouillons et traiter des requêtes structurées, il est nettement plus faible.
Pour voir l’écart de vos propres yeux – voici le GPT-5.4 Nano d’entrée de gamme face au modèle phare GPT-5.4 sur une tâche managériale typique. GPT-5.4 Nano coûte un ordre de grandeur moins cher et, en vitesse de réponse, il est comparable à un bon modèle local 70B. Comparez ce que l’on perd en choisissant un modèle plus faible :
La différence ne se lit pas dans la beauté des formulations mais dans la profondeur de l’analyse : le mini-modèle traite généralement les trois causes comme équivalentes et donne des recommandations générales, le modèle phare sépare les symptômes de la cause racine et pose des questions qui vont au fond. Un modèle local 70B se comporte plus près du mini-modèle, un local 8B nettement moins bien.
Scénarios concrets où un 8B local se débrouille bien :
- Résumer des documents et des transcriptions de réunions
- Générer des brouillons de mails et de rapports sur modèle
- Questions-réponses simples sur un document chargé
- Mise en forme et structuration de texte
Scénarios où mieux vaut revenir au cloud :
- Analyse complexe avec conclusions non évidentes
- Travail sur hypothèses concurrentes
- Tâches où la précision factuelle est critique
- Instructions longues, à plusieurs étapes avec conditions
Comprendre quelle IA utiliser, et quand – c'est précisément ce que font les 9 exercices pratiques du module ouvert. Essayez gratuitement, sans inscription.
Sans paiement requis • Notification au lancement
Le smartphone comme plateforme locale
Un sujet à part, qui était encore une expérimentation il y a un an et qui constitue aujourd’hui un scénario tout à fait utilisable.
Gemma 4 4B de Google (sorti le 2 avril 2026) est l’une des options mobiles clés. Il s’exécute via Google AI Edge Gallery pour iOS et Android, se télécharge une fois et fonctionne entièrement hors-ligne. Sur un iPhone 16 Pro avec puce A18 Pro et 8 Go de mémoire (1 100 EUR) ou un Samsung Galaxy S24/S25 Ultra (900 EUR) – environ 15-20 tokens par seconde. Phi-4 3,8B de Microsoft offre une vitesse comparable sur les mêmes appareils. Llama 3.2 3B et Qwen 3.5 4B se lancent aussi via PocketPal ou MLC LLM.
Qwen 3.5 en versions 0,8B et 4B tourne aussi sur téléphone via PocketPal. Vitesse sur les téléphones haut de gamme (iPhone 17 Pro, Pixel 9 Pro, Samsung S24/S25) – 5-20 tokens par seconde. Sur le milieu de gamme avec 6 Go de RAM, c’est plus modeste ; il faut au minimum 8 Go de mémoire pour un usage confortable.
La valeur pratique de l’exécution sur téléphone reste cantonnée à quelques scénarios : analyse d’un document confidentiel sans accès Internet, brouillon rapide sans cloud, démonstration de concept. Pour un travail régulier, l’écran et l’interface d’un téléphone ne sont pas l’environnement idéal. Mais comme possibilité – c’est bien réel.
Outils : que faut-il installer
Ollama – la façon la plus simple de commencer. S’installe comme un programme ordinaire, les modèles se téléchargent d’une seule commande (ollama pull qwen3.5:9b), fonctionne via le navigateur ou toute application compatible avec l’API OpenAI. Depuis mars 2026, il utilise MLX sur Apple Silicon. Recommandé pour la plupart des utilisateurs.
LM Studio – Ollama avec interface graphique. Si la ligne de commande vous rebute, LM Studio permet de faire la même chose via une interface visuelle : choisir un modèle, le télécharger, lancer un chat. Un peu plus lourd en ressources.
Jan – variante open source axée sur la confidentialité. Fonctionne entièrement hors-ligne, n’envoie aucune télémétrie. Si la confidentialité est la motivation principale, à considérer.
llama.cpp – le moteur de base qui fait tourner les trois outils ci-dessus. Un outil en ligne de commande pour qui veut le contrôle maximal. Pour un manager sans bagage technique, plutôt à éviter.
MLX d’Apple – la bibliothèque directement fournie par Apple pour faire tourner des modèles sur Silicon. Utilisée à l’intérieur d’Ollama, mais accessible en direct aussi. Donne 20 à 30 % de vitesse en plus par rapport à llama.cpp.
L'IA locale n'est qu'un format de travail parmi d'autres. Dans le module ouvert – 9 tâches de manager avec différents outils, cloud et locaux. Essayez gratuitement.
Sans paiement requis • Notification au lancement
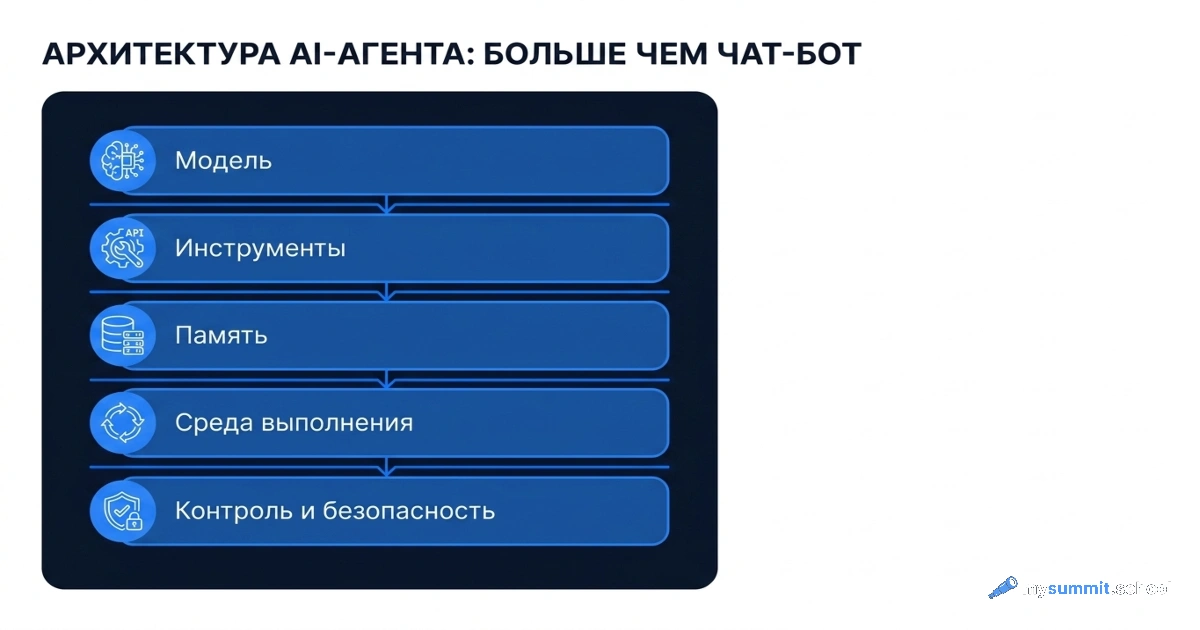
Mode agentique : un modèle local avec accès aux fichiers
Si vous avez lu nos articles sur OpenCode ou l’analyse de données agentique, une question logique se pose : peut-on faire tourner un agent en local, sans envoyer les données dans le cloud ?
Oui, et c’est sans doute le scénario le plus intéressant pour les managers qui travaillent avec des documents confidentiels.
OpenCode, que nous avons analysé en détail précédemment, prend en charge la connexion à des modèles locaux via Ollama. Le schéma est le suivant : Ollama fait tourner le modèle en local et expose une API locale sur le port 11434. OpenCode s’y connecte à la place du Claude cloud. Les données ne quittent pas la machine. L’agent lit vos fichiers, analyse, écrit les résultats – tout en local.
La limite est prévisible : un modèle local 8B en mode agentique se débrouille avec des tâches plus simples que Claude ou GPT-5. Pour analyser un ou deux documents sur des questions précises – oui, ça passe. Pour une investigation complexe multi-fichiers avec des conclusions non triviales – l’écart sera sensible. Comme nous l’avons montré sur un exemple concret, la qualité de l’analyse agentique est déterminée d’abord par le modèle, pas par le framework.
Avec un modèle 32B et au-delà, l’écart se réduit nettement. Si vous disposez d’un Mac Studio avec 64 Go ou d’une station de travail avec deux cartes graphiques – le mode agentique local avec un modèle 32B devient un substitut valable au cloud pour la majorité des tâches.
Point d’entrée minimal : que faut-il acheter
En bref :
Pour démarrer – un Mac avec puce M3 ou M4 et 16 Go de mémoire. Si vous avez déjà ce Mac, vous avez déjà le matériel qu’il faut. Ollama s’installe en 5 minutes, et vous pouvez lancer Qwen 3.5 9B ou Gemma 4 26B A4B aujourd’hui même.
Pour travailler confortablement avec des modèles 14-32B – un Mac avec 32 Go de mémoire, ou un PC avec RTX 3060/4060 12 Go. Une RTX 3060 12 Go sur le marché de l’occasion coûte environ 200-300 EUR – c’est la voie la moins chère vers une expérience décente sous Windows.
Pour remplacer le cloud sans compromis – un Mac Studio avec 64 Go (investissement conséquent) ou une station de travail avec deux cartes graphiques (autour de 3 000 USD).
Soyons honnêtes : pour la plupart des managers, la bonne réponse n’est pas « passer aux modèles locaux », mais les utiliser en complément du cloud. Le cloud pour les tâches exigeantes, où la qualité prime. Le local pour les données confidentielles, le travail hors-ligne et les cas où il n’y a pas de raison de payer le cloud pour des opérations simples.
Ce qui reste rarement explicité
Quelques points qui se découvrent généralement après l’installation, pas avant.
La taille du modèle au téléchargement, c’est la taille finale sur disque. Un modèle 8B au format Q4 pèse environ 5 Go. Un 32B – près de 20 Go. Avec Ollama, les modèles téléchargés sont stockés dans un dossier système ; sur un petit disque, l’espace peut manquer sans prévenir.
Le premier lancement prend du temps. Ollama charge le modèle en mémoire au premier appel – cela peut prendre 30 à 60 secondes pour un gros modèle. Ensuite, il reste en mémoire et les requêtes suivantes sont rapides.
Un prompt système dans la langue de travail fonctionne mieux que son absence. La plupart des modèles sont entraînés sur des données mixtes, mais répondent dans la langue dans laquelle on leur parle. Préciser explicitement « réponds en français » en début de session aide.
Pour comparer la qualité des modèles locaux et cloud sur des tâches managériales, notre benchmark public est là – on peut y voir précisément où tel ou tel modèle perd en qualité par rapport aux meilleurs modèles cloud.
Enfin, la possibilité de faire tourner un modèle en local ne signifie pas qu’il faille toujours le faire. C’est un outil supplémentaire avec des conditions d’emploi claires. C’est précisément de cette compétence – savoir quand quel outil est adapté – que parle notre programme de formation.
Fait intéressant : la logique même du choix de l’outil – cloud ou local, 8B ou 70B, agent ou chat – est exactement le même type de compétence que la formulation rigoureuse de tâches pour une IA. Les outils changent tous les quelques mois, mais la capacité à calibrer ses attentes et à choisir l’approche selon la tâche, elle, reste.



De l'outil au système
Le socle apprend à travailler avec n'importe quelle IA – cloud, locale, agentique. La spécialisation Chef de projet ajoute des scénarios concrets pour les tâches managériales. Découvrez la structure complète du programme.

Stanislav Belyaev
Engineering Leader chez Microsoft18 ans a diriger des equipes d'ingenieurs. Fondateur de mysummit.school. 700+ diplomes chez Yandex Practicum et Stratoplan.