40 кейсов GigaChat: проверяем данные Сбера по бенчмарку

AI-модели в этой статье
Сбер выпустил рекламный спецпроект: сорок бизнес-кейсов компаний, которые внедрили GigaChat и рассказывают об эффектах. EdTech, MedTech, HRTech, кибербезопасность, PropTech. Красивые карточки, конкретные цифры, реальные стартапы.

На изображении: промо-слайд «На шаг впереди» от акселератора Sber500×ГигаЧат – 40 стартапов из 9 индустрий. Заявленные эффекты: ускорение бизнес-процессов до x16, снижение затрат до 90%, автоматизация задач до 95%, рост выручки до 30%.
У нас есть бенчмарк: 29 моделей, 4 308 независимых оценок на управленческих задачах. GigaChat в нём занимает последнее, 29-е место по итогам второй волны тестирования. Это создаёт интересную ситуацию.
Не потому что Сбер лжёт. Кейсы реальные, стартапы существуют, автоматизация работает. Вопрос в другом: была ли это оптимальная модель для задач, которые они решали?
Откуда берутся такие кейсы
Рекламный материал Сбера существует в жанре, у которого есть устойчивое название: vendor-sponsored case study. Компании рассказывают об успехах с конкретным инструментом, вендор публикует и продвигает. Это нормальная практика – так работают все крупные AI-компании, от Microsoft до Anthropic.
Проблема в том, что vendor case study отвечает на вопрос «работает ли решение» – но не на вопрос «оптимальное ли это решение». Компания, внедрившая чат-бот на GigaChat и сэкономившая 40% времени операторов, честно описывает результат. Но она не проводила A/B-тест с Qwen 3.6 Flash – потому что ни одна реальная компания не делает полный тендер среди всех моделей перед каждым проектом.
Именно поэтому независимые бенчмарки вообще существуют.
Что показывает наш бенчмарк
Мы протестировали AI модели по восьми категориям управленческих задач – от анализа данных и поиска информации до планирования и работы с командой. Методология: два независимых LLM-судьи с калибровкой человеком. Подробно о том, как устроены бенчмарки и почему им стоит доверять с оговорками.
У Сбера сейчас две основные линейки: GigaChat 2 Max и GigaChat Ultra. Важно не путать – это разные модели с разным уровнем качества.
Флагман линейки – GigaChat Ultra. API доступен корпоративным клиентам по отдельному договору, для индивидуальных разработчиков – только веб-интерфейс gigachat.ru. В нашем бенчмарке занял место 28 из 29 с оценкой 4,83 – лучший результат среди всех российских моделей в нашем тесте.
Основная модель с публичным API – GigaChat 2 Max, именно её используют большинство стартапов из кейсов. Место 29 из 29, оценка 4,20. В первой волне та же модель набирала 3,08 – прогресс за несколько месяцев значительный.
Это важное различие. Большинство стартапов из кейсов работают через публичный API – то есть с GigaChat 2 Max. Те, кто получил корпоративный доступ к Ultra, работают с более сильной моделью – но и за другие деньги. Посмотрим, как именно GigaChat 2 Max справляется с задачами из кейсов.
| Категория задач | GigaChat 2 Max | GigaChat Ultra |
|---|---|---|
| Информационный поиск | 29 / 29 (3,87) | 28 / 29 (4,71) |
| Анализ и решения | 29 / 29 (4,39) | 28 / 29 (5,44) |
| Планирование | 29 / 29 (4,33) | 28 / 29 (5,92) |
| Решение проблем | 28 / 29 (4,27) | 29 / 29 (4,25) |
| Региональная осведомлённость | 29 / 29 (3,57) | 28 / 29 (3,98) |
| Коммуникация | 28 / 29 (4,74) | 29 / 29 (4,74) |
| Работа с командой | 29 / 29 (4,41) | 28 / 29 (5,16) |
| Обучение и развитие | 29 / 29 (4,00) | 28 / 29 (4,48) |
Обе модели Сбера занимают последние два места в бенчмарке, но разрыв между ними по баллам заметный: Ultra набирает 5,92 по планированию, Max – 4,33. Ultra доступна через API только корпоративным клиентам, а Max – через публичный API. Большинство стартапов из кейсов работают с Max.
Сорок кейсов: что за задачи
Я прочитал все сорок карточек. Задачи группируются в несколько направлений.
Примерно треть – чат-боты и обработка входящих обращений. Страховая компания автоматизировала ответы на запросы клиентов, медицинский сервис сделал ассистента для записи на приём, банк внедрил помощника для поддержки. Это реальная и работающая задача для любого достаточно сильного LLM.
Ещё одна крупная группа – генерация текста и документов: маркетинговые материалы, описания объектов недвижимости, HR-документация. HRTech-компания автоматизировала создание должностных инструкций, PropTech-стартап – описания квартир, MarTech-платформа – рекламные тексты для разных сегментов.
Дальше начинается территория, где данные бенчмарка ставят вопросы. Анализ документов и данных – разбор резюме, медицинских документов, классификация обращений. Несколько кейсов про кибербезопасность: анализ угроз, классификация инцидентов, генерация отчётов. И отдельно – специфические отраслевые задачи вроде ИИ-ассистента для HR-интервью или рекомендательных систем для EdTech.
Где данные бенчмарка противоречат маркетингу
Возьмём три кейса из разных категорий и посмотрим на них через данные.
Один из EdTech-кейсов – автоматизация разбора клинических случаев для обучения студентов-медиков. Задача требует точности в фактах, правильных ссылок на источники, отсутствия галлюцинаций.
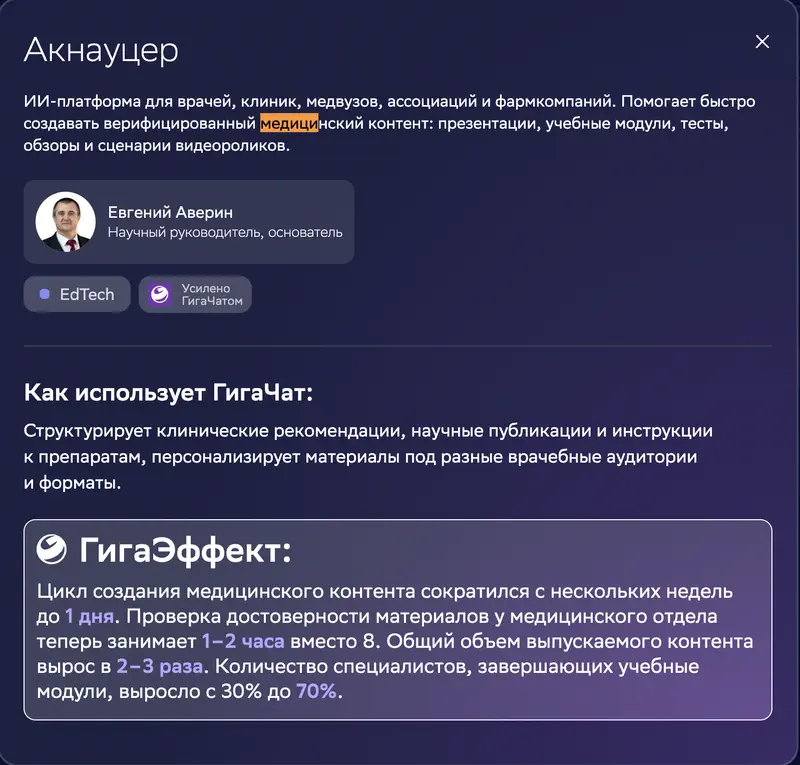
На карточке кейса: Акнауцер – ИИ-платформа для медицины. Заявленный «ГигаЭффект»: цикл создания контента сократился с нескольких недель до 1 дня, проверка достоверности – с 8 часов до 1–2, объём контента вырос в 2–3 раза, а доля специалистов, завершающих учебные модули, выросла с 30% до 70%.
Наш бенчмарк по категории «информационный поиск»: GigaChat 2 Max на последнем, 29-м месте из 29. Конкретная слабость в описании: «находит верное направление анализа, но выдумывает цены инструментов, ссылки на исследования и юридические нормы – использовать без перепроверки каждого факта опасно».
Кейс вполне реальный. Но компания, которая не перепроверяет каждый вывод модели, работает на модели, которая занимает последнее место по точности из 29 доступных.
Несколько MarTech-компаний описывают автоматизацию генерации рекламных материалов. Коммуникация – 28-е место из 29, наименее слабая категория GigaChat. Для простых шаблонных текстов этого может быть достаточно.
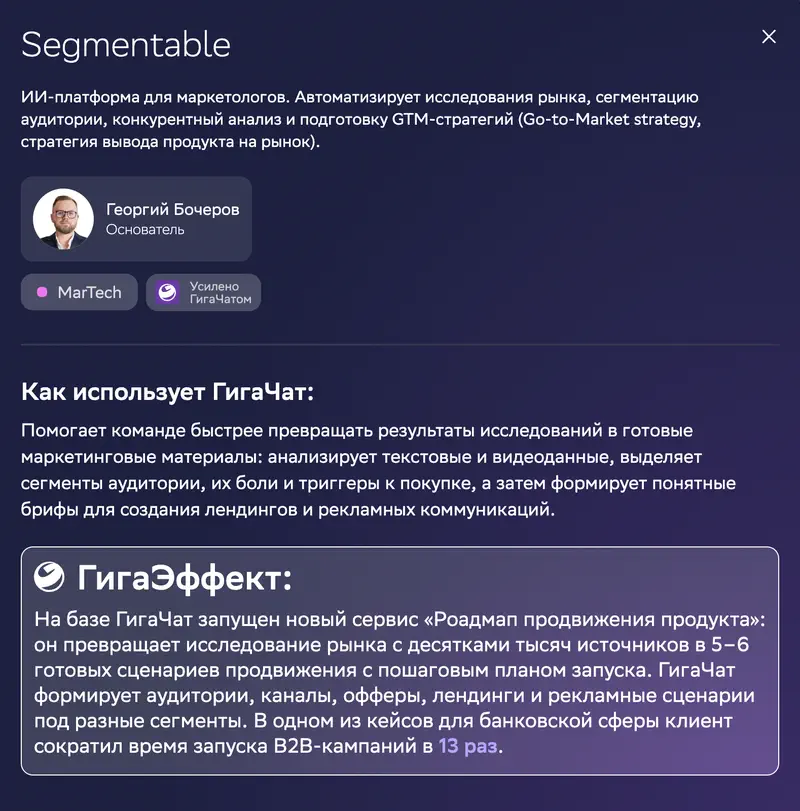
На карточке кейса: Segmentable – ИИ-платформа для маркетологов. Заявленный «ГигаЭффект»: сервис «Роадмап продвижения продукта» превращает исследование рынка с десятками тысяч источников в 5–6 готовых сценариев запуска, а в одном банковском кейсе клиент сократил время запуска B2B-кампаний в 13 раз.
Интереснее ситуация с кибербезопасностью. Один из кейсов – система для классификации инцидентов ИБ и генерации отчётов об угрозах. Задача предполагает точный анализ, конкретные выводы, применимые рекомендации.
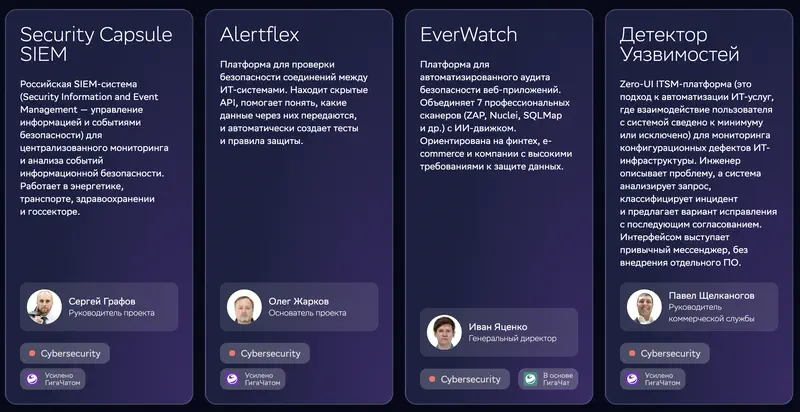
На изображении: четыре продукта по кибербезопасности на базе ГигаЧата. Security Capsule SIEM – российская SIEM-система для централизованного мониторинга ИБ; Alertflex – проверяет обмен данными между ИТ-системами через API и сам создаёт правила защиты; EverWatch – автоматический аудит веб-приложений, объединяет 7 сканеров (ZAP, Nuclei, SQLMap) с ИИ-движком; Детектор Уязвимостей – Zero-UI ITSM-платформа, где инженер описывает проблему в мессенджере, а система классифицирует инцидент и предлагает исправление.
Наш бенчмарк по категориям «анализ и решения» и «решение проблем»: 29-е и 28-е место из 29. Описание: «верно определяет общее направление решения, но не даёт ни весовых критериев, ни сценарного анализа, ни конкретных рекомендаций – по сути пересказывает условие задачи».
Отчёт о классификации инцидентов, написанный моделью на 29-м месте по аналитике из 29 доступных – это автоматизация создания документа. Анализ угроз остаётся на человеке. Разница значимая.
Парадокс абсолютной и конкурентной оценки
Здесь есть нюанс, который важно понять, потому что он контринтуитивный.
GigaChat 2 Max набирает 4,20 из 10 – ниже середины шкалы. Но даже абсолютный балл плохо передаёт реальную конкурентоспособность. Наш эксперимент с промпт-техниками показал: даже лучшие техники промптинга не закрывают разрыв между слабой и сильной моделью. GigaChat и Alice с оптимальными промптами всё равно проигрывали GPT-5.4 и Claude с наивными запросами. Версия v2 стала сильнее – но принцип остаётся: абсолютный балл завышает конкурентоспособность.
Мы разбирали этот эффект подробно в статье «Почему AI-бенчмарки врут». Оценки на шкале накапливаются вблизи среднего значения, а небольшая разница в баллах соответствует большой разнице в частоте победы. Когда Qwen 3.6 Flash набирает 7,60 в нашем бенчмарке против 4,20 у GigaChat 2 Max – речь не о «на 80% лучше». Речь о том, что в прямом сравнении Qwen побеждает подавляющее большинство раз.
Именно поэтому «работает» и «оптимально» – разные вещи.
Провести оценку на реальных задачах, понять, когда результат хорош, а когда кажется хорошим – этому посвящён открытый модуль курса. Девять управленческих сценариев, каждый с неочевидным подвохом, без регистрации.
В 40 кейсах Сбера нет A/B-теста с альтернативными моделями. В открытом модуле – 9 задач, где вы сами оцениваете результаты и учитесь отличать «работает» от «оптимально». Бесплатно.
Доступ сразу после регистрации
Один кейс под микроскопом: ESME AI и проектная документация
Абстрактные баллы бенчмарка не показывают, как именно выглядит разница между моделями. Один из сорока кейсов даёт возможность это увидеть – и заодно разобрать, где данные бенчмарка работают напрямую, а где их нужно читать осторожно.
ESME AI – инструмент для девелоперов и генподрядчиков. Платформа 360° съёмки объектов, встроенный AI-ассистент. GigaChat помогает работать с проектной и рабочей документацией: пользователь спрашивает на обычном языке, ассистент находит информацию в чертежах, спецификациях и регламентах. Заявленный эффект: «поиск информации по проекту сократился с десятков до нескольких минут, принятие решений ускорилось на 30–50%».
Задача реальная. Кто работал на объекте, знает эту боль: средний проект – сотни, иногда тысячи листов по разделам (АР, КР, ОВ, ВК, ЭОМ), плюс спецификации, ведомости объёмов, общие данные и нормативный слой (СП, ГОСТ). Вопрос «какой класс бетона по проекту для перекрытия 3-го этажа?» – это десять-сорок минут перелистывания. Сокращение «с десятков минут до нескольких» правдоподобно – если поиск действительно работает.
Почему бенчмарк здесь – слабый прокси
Тут важно быть честным к собственным данным. Наш бенчмарк измеряет управленческое рассуждение: проанализировать ситуацию, спланировать, сделать вывод. Поиск по документации устроен иначе. Это задача класса RAG (retrieval-augmented generation): система сначала достаёт нужный фрагмент из реального PDF проекта, а модель извлекает ответ из него – не из «памяти», накопленной при обучении.
Это меняет картину. Фирменная слабость GigaChat – «выдумывает ссылки на исследования и юридические нормы» – это сбой генерации из обученных данных. Когда модель отвечает строго по приложенному фрагменту чертежа, такой сбой подавляется. Поэтому 29-е место по «информационному поиску» – слабый прокси для вопроса «найдёт ли ассистент верный класс бетона». На хорошо построенном RAG даже слабая модель ведёт себя приемлемее, чем в свободной генерации.
Что на самом деле ломает такую автоматизацию
Проблема в том, что для строительной документации главные риски лежат не там, где их измеряет бенчмарк – и часть из них опаснее обычных галлюцинаций.
Первое, что ломает такую систему на практике, – само чтение чертежа. Чертежи – это векторные PDF или DWG: текст в штампах, выносках, размерных цепочках, штриховке и встроенных таблицах. Универсальные системы распознавания на этом спотыкаются, а если парсинг ошибся – модель уверенно отвечает по испорченному тексту. Спецификации и ведомости – это многостраничные таблицы с объединёнными ячейками, и большинство ошибок «не то значение» рождается именно здесь, а не в галлюцинациях.
Дальше – ответ редко лежит на одном листе. «Класс бетона для перекрытия 3-го этажа» – это связка: план -> разрез -> спецификация -> общие указания на листах КЖ, иногда отдельный лист. Чтобы собрать ответ, нужно пройти по разнородным документам. Ровно здесь ассистент тихо возвращает правдоподобное, но неверное значение.
Есть и менее очевидный риск – версионность. Документация живёт: изменения, извещения, штампы «в производство работ», красные линии. Если в индекс попала устаревшая ревизия, ассистент уверенно выдаст отменённое значение – со ссылкой на реальный, но старый лист. Это опаснее галлюцинации: выглядит авторитетно и проверяемо.
Наконец, цена ошибки и цитируемость. Инженер не может действовать по ответу «B25» без указания на том, лист и позицию спецификации. Ошибка в марке бетона или классе арматуры означает дефект конструкции. И если ассистент не превращает проверку в трёхсекундный взгляд на источник, экономия времени испаряется: чтобы доверять ответу, всё равно придётся найти первоисточник вручную.
Где бенчмарк всё-таки релевантен
У задачи ESME два слоя. Первый – извлечение факта: это про качество пайплайна, см. выше. Второй – анализ и синтез: «оцени риски по этому узлу», «сравни два варианта решения». Разница между классами моделей здесь видна напрямую, и бенчмарк её ловит.
Мы не имеем доступа к конкретным промптам ESME AI, но аналитический слой такой задачи – ровно то, что мы тестировали в эксперименте с промпт-техниками. Возьмём сопоставимый сценарий – бизнес-анализ на основе конкретных данных.
Задача из эксперимента:
Интернет-магазин электроники, 45 сотрудников. За последний квартал выручка упала на 18%, при этом трафик на сайт вырос на 12%. Средний чек снизился с 8 700 руб. до 6 200 руб. Возвраты выросли с 4% до 11%. Рекламный бюджет увеличили на 30%. Что происходит и что делать?
Все модели получили одинаковый промпт, без каких-либо техник.
GigaChat 2 Max (29-е место, оценка 3,02) выдал 53 строки текста. Шесть «возможных причин», шесть блоков рекомендаций: «провести анализ качества продукции», «улучшить логистику и доставку», «повысить квалификацию сотрудников». Конкретных цифр из условия задачи в анализе нет. Приоритизации нет. Итог: «необходимо комплексно подойти к решению проблемы».
Для ESME AI это значит: на аналитическом слое модель скажет «нужно проверить спецификацию», но вряд ли выстроит приоритеты и сделает из найденного содержательный вывод.
Alice AI LLM (YandexGPT, оценка 3,85) справилась заметно лучше: появилась структура – «ABC-анализ ассортимента», «парсеры цен», «юзабилити-тест воронки», блок «краткосрочные приоритеты на 2 недели». Но приоритизация плоская, антикризисный таймлайн не расписан.
GPT-5.4 (1-е место, оценка 4,38) начал иначе – с расчёта: «средний чек упал примерно на 29%». Модель посчитала, а не пересказала условие. Дальше: антикризисный план на 10 дней с ролями для каждого из 45 человек, ранжированные гипотезы и список действий «на завтра утром».
Три уровня – три класса результата:
| Модель | Считает цифры из условия? | Приоритизирует гипотезы? | Даёт операционный план? | Фактическая точность |
|---|---|---|---|---|
| GigaChat 2 Max | Нет | Нет | Общие советы | 58,9% |
| Alice AI LLM | Частично | Нет | Приоритеты, но без таймлайна | 75,0% |
| GPT-5.4 | Да (29% падение чека) | Да (по вероятности) | План на 10 дней с ролями | 83,9% |
Фактическая точность в таблице – из эксперимента с бизнес-анализом, где модель генерирует ответ сама, без приложенных документов. Это не значит, что ассистент ESME ошибётся в 41% запросов к чертежам: на grounded-поиске с цитатами картина другая. Но цифра показывает класс. Там, где «анализ документации» означает не просто найти строку, а посчитать, приоритизировать и собрать вывод, GigaChat 2 Max остаётся на уровне общих советов.
При прямом сравнении в эксперименте GigaChat 2 Max с лучшей техникой промптинга выигрывал у GPT-5.4 лишь в 4% случаев. Alice AI LLM – в 28–36%. При 4% побед разрыв уже не в нюансах, а в классе задач, которые модель способна решить.
Сменить модель здесь стоит: обе российские альтернативы – Alice AI LLM и DeepSeek V4 Flash – доступны в Яндекс Cloud для российских компаний. DeepSeek V4 Flash занимает 12-е место в нашем бенчмарке (7,34 балла) и стоит $0,20 / $0,60 за миллион токенов – в 12 раз дешевле GigaChat при значительно более высоком качестве. Но честно: смена модели чинит аналитический слой и снижает галлюцинации, а главные строительные риски – парсинг чертежей, версионность, цитируемость – живут в пайплайне, и их не закроет никакая модель.
Как сделать такого ассистента надёжным
Если строить такой продукт всерьёз, порядок приоритетов примерно такой.
Самый большой прирост надёжности – структурировать данные вместо поиска по PDF. Один раз распарсить спецификации и ведомости в проверенную человеком базу (элемент -> материал -> класс -> лист -> ревизия). Тогда «класс бетона для перекрытия 3-го этажа» становится точечным запросом к данным, а не нечётким поиском по тексту.
Каждый ответ должен содержать цитату: том, лист, позиция – и показанный фрагмент чертежа. Проверка превращается во взгляд, и только тогда экономия времени реальна.
Поиск и генерацию стоит разделить. Извлечение фрагментов – на эмбеддингах и реранкере, модель – только на финальном извлечении ответа с жёсткой инструкцией «отвечай строго по контексту, иначе скажи „не найдено”». Именно это делает выбор более сильной модели осмысленным.
Нужен слой версий: ассистент отвечает «по ревизии такой-то» и предупреждает, если для листа есть более свежая.
Для критичных запросов – класс бетона, арматура, предел огнестойкости – у ассистента должно быть право сказать «не знаю»: либо точная цитата, либо отказ. «Не найдено» – это фича, а не баг.
Уникальный актив ESME – связка 360°-съёмки с документацией. Шаг от «искать в документах» к «сравнить факт (360°-съёмку) с проектом»: отклонения, процент готовности, дефекты. Именно этот шаг закрывает реальную задачу стройконтроля и выходит за рамки ускорения поиска.
И наконец – проверять на своих документах. Сто реальных запросов с выверенными ответами и замер трёх метрик: полнота поиска, точность цитат, доля устаревших ревизий. Универсальный бенчмарк не скажет ESME, безопасен ли их пайплайн – это покажет только такой тест.
Если у вас нет выбора: как улучшить результат GigaChat
Допустим, вы работаете в организации, где GigaChat – единственный разрешённый инструмент. On-premise, корпоративный контракт, требования ИБ. Что можно сделать?
Наш эксперимент с промпт-техниками проверил десять подходов на GigaChat 2 Max – от ролевого фрейминга до XML-разметки и цепочки рассуждений.
Лучший результат показала техника №4 – few-shot: 89% побед над наивным промптом. Вы берёте пример качественного ответа на похожую (но другую) задачу и добавляете в промпт перед своим вопросом. Модель калибруется по образцу – и выдаёт структурированный, конкретный ответ вместо общих фраз.
На той же задаче с интернет-магазином GigaChat 2 Max с few-shot примером выдал другой результат: вместо перечисления шести общих категорий – структурированный диагноз со ссылками на конкретные цифры из условия («падение среднего чека со 8 700 до 6 200 ₽»), таймлайн рекомендаций (эта неделя / 2–3 недели / до месяца) и секцию «Чего мы пока не знаем».
Данные по GigaChat 2 Max из эксперимента:
| Техника | Балл (из 5) | Подъём от базы | Побед vs наивный промпт |
|---|---|---|---|
| T0 (без техник) | 3,02 | – | – |
| T4 (few-shot) | 3,63 | +20% | 89% |
| T2 (структурированный вывод) | 3,43 | +14% | 82% |
| T10 (XML + Markdown) | 3,59 | +19% | 78% |
| T3 (цепочка рассуждений) | 3,55 | +18% | 79% |
Но вот важная оговорка: GigaChat 2 Max с лучшей техникой (3,63) всё равно ниже, чем Qwen 3.6 Flash (7,60) или DeepSeek V4 Pro (7,75) без каких-либо техник. Промпт-инжиниринг не закрывает архитектурный разрыв – он делает слабую модель терпимой, но не конкурентной.
Остаётся вопрос источника образца. Самый практичный путь: один раз прогнать задачу через сильную модель (DeepSeek V4 Flash бесплатен в веб-интерфейсе, Kimi K2.6 доступен без VPN), сохранить результат и использовать как образец для GigaChat на похожих задачах. Это не «списывание» – это калибровка.
Альтернативы, доступные в России
Это, возможно, самая конкретная часть материала. Если компания из сберовского кейса решает задачи из нашего списка, какие ещё модели ей доступны – и что говорит бенчмарк? Подробное сравнение инструментов по задачам – в обзоре GenAI-инструментов для менеджера.
Все перечисленные ниже модели работают без VPN, доступны через API, есть на российском рынке.
| Модель | Место (из 29) | Оценка | Стоимость (вход/выход, $/M токенов) |
|---|---|---|---|
| MiMo v2.5 Pro | 3 | 8,37 | $1 / $3 |
| Kimi K2.6 | 5 | 8,27 | $0,74 / $3,49 |
| Qwen 3.6 Plus | 7 | 7,94 | $0,33 / $1,95 |
| MiMo v2.5 | 8 | 7,82 | $0,40 / $2 |
| DeepSeek V4 Pro | 10 | 7,75 | $0,43 / $0,87 |
| Qwen 3.6 Flash | 14 | 7,60 | $0,25 / $1,50 |
| MiniMax M2.7 | 15 | 7,58 | $0,30 / $1,20 |
| GigaChat 2 Max | 29 | 4,20 | $7,22 / $7,22 |
Разница в стоимости – важный момент, и мы разбирали его в анализе «премиальной наценки» AI-моделей. GigaChat 2 Max стоит $7,22 за миллион токенов на входе и выходе. Qwen 3.6 Flash – $0,25 на входе и $1,50 на выходе. Если у компании пиковая нагрузка 10 миллионов токенов на входе и столько же на выходе: GigaChat обойдётся примерно в $144, Qwen 3.6 Flash – примерно в $17,50. При этом Qwen занимает 14-е место против 29-го.
Дешевизна сама по себе не аргумент. У GigaChat есть реальное преимущество – on-premise развёртывание. Для банков, госструктур, оборонных предприятий, где данные не могут покидать контур – это единственный выбор. Об этом мы писали в практическом руководстве по GigaChat. Но для стартапов из кейсов, которые работают в облаке – преимущество нерелевантно.
Пять вопросов для любого AI-вендора
Это не только про Сбер. Microsoft публикует кейсы Copilot, Anthropic – кейсы Claude, Google – кейсы Gemini. Формат одинаковый. Вопросы тоже должны быть одинаковыми.
Начните с самого простого: какая именно задача автоматизирована – и относится ли она к сильным сторонам модели? Чат-бот для простых вопросов работает на любой модели. Анализ медицинских документов или юридических рисков – уже нет.
Второй вопрос – про метрики. «Сократили время на 40%» звучит хорошо. Но 40% от чего? Если оператор тратил 20 минут на ответ, а теперь тратит 12 – экономия реальная. Если модель выдаёт черновик за 30 секунд, но редактор тратит 15 минут на правки – эффективность другая. И что было бы вообще без AI?
Проводился ли тест с альтернативными моделями? Почти никогда нет. Это понятно: компания решает бизнес-задачу, а не занимается сравнительным тестированием. Но отсутствие A/B-теста означает, что слова «GigaChat позволил нам» правильнее читать как «с GigaChat мы смогли» – без утверждения, что другие модели дали бы хуже.
Отдельная тема – перепроверка. Если задача требует точных данных (фактических справок, юридических ссылок, медицинских выводов) и нет систематической проверки каждого вывода – это риск. Вопрос не в том, галлюцинирует ли модель иногда. Вопрос в том, сколько ошибок пройдёт мимо и какова их цена.
И наконец: что происходит на граничных случаях? Большинство AI-продуктов хорошо работают на типичных запросах. Интересно поведение на нетипичных – редкий регион, нестандартная ситуация, пограничный случай закона. Именно здесь разрыв между 3-м и 29-м местом проявляется сильнее всего.
Нажмите «Запустить» и сравните ответы. Обратите внимание на конкретность: называет ли модель реальные стандарты и метрики ИБ, или ограничивается общими фразами? Именно здесь проявляется разница между 5-м и 29-м местом в бенчмарке.
Честное признание: прогресс реальный
GigaChat 2 Max на последнем месте – но это важно понимать в динамике. В первой волне тестирования оценка той же линейки была 3,08. Сейчас – 4,20. Рост на 36% за несколько месяцев – это значительный прогресс по качеству, даже если позиция в рейтинге остаётся последней.
Инженерная работа Сбера заметна. Если темп сохранится – через год-два GigaChat может оказаться в верхней половине таблицы. Это открытый вопрос, и в интересах российских пользователей, чтобы ответ оказался положительным.
Сорок стартапов из кейсов тоже делают реальную работу. Автоматизация на GigaChat у многих из них работает. Для части задач – особенно связанных с деловой перепиской и простыми чат-ботами – выбор разумный. Для других задач данные бенчмарка ставят вопрос об оптимальности.
Возможно, часть из них выбрала GigaChat по нетехническим причинам: уже есть корпоративный контракт со Сбером, требования ИБ, давление руководства. Это тоже реальные соображения, которые не учитывает бенчмарк.
Вопрос в другом: при принятии технического решения о выборе модели – что вы проверяете?
Отличать «модель дала правдоподобный результат» от «модель дала правильный результат» – навык, который нарабатывается только на конкретных задачах. Именно это отрабатывается в открытом модуле курса: девять управленческих сценариев, где разрыв между «звучит убедительно» и «верно» неочевиден.
Сорок кейсов без A/B-теста – это норма для вендорского маркетинга. В открытом модуле вы отрабатываете навык оценки результата на 9 управленческих задачах. Бесплатно, без регистрации.
Доступ сразу после регистрации
Что делать с этой информацией
Если вы используете GigaChat – особенно в on-premise или Enterprise формате, – это не аргумент переключиться прямо сейчас. Есть задачи, где модель работает приемлемо. Есть ситуации, где выбора нет.
Полезное действие – понять, в каких задачах вы полагаетесь на точность GigaChat, и какой уровень перепроверки у вас встроен. Наш детальный обзор GigaChat и тест GigaChat Ultra Thinking показывают конкретные ситуации, где модель ошибается чаще всего: информационный поиск, юридические нормы, региональные данные.
Если вы принимаете решение о выборе модели для нового проекта – данные бенчмарка и пять вопросов выше дают структуру. Полный рейтинг 29 моделей с разбивкой по категориям – на странице нашего исследования.
Если вы читаете следующий вендорский кейс – неважно, от Сбера, Microsoft или Anthropic, – задайте те же пять вопросов. Ответы на них обычно не в тексте кейса.
От кейсов – к самостоятельной оценке
Третья глава курса разбирает восемь AI-инструментов с данными: что умеет каждый, где галлюцинирует, для каких задач оптимален. Результаты тестирования на управленческих задачах, а не пересказ маркетинга.




Stanislav Belyaev
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.