GigaChat для работы: как выжать максимум из того, что есть
AI-модели в этой статье
Если вы читаете эту статью – скорее всего, GigaChat уже есть в вашем рабочем арсенале. Может, компания развернула Enterprise на закрытом контуре. Может, вы в госструктуре и зарубежные сервисы недоступны. Может, просто привыкли к интерфейсу Сбера. Причина не важна – важно, что инструмент у вас есть, и вы хотите получать от него нормальный результат.
Интернет по запросу «GigaChat» выдаёт два типа контента: рекламные обзоры от партнёров Сбера и пренебрежительные разборы от тех, кто пользуется ChatGPT. Ни то, ни другое не помогает, когда нужно прямо сейчас написать промпт и получить рабочий черновик документа.
Эта статья – практическое руководство. Что конкретно делать, чтобы GigaChat выдавал на 20–30% лучше. Чего не делать, чтобы не получить хуже. И где проходит граница, за которой промптинг не спасает и нужен другой инструмент.
Где GigaChat на своём месте
Прежде чем разбирать техники – честная карта сильных сторон. У GigaChat есть три зоны, где он работает не хуже или лучше конкурентов.
Закрытый контур: главное преимущество
GigaChat – единственный российский LLM с полноценным on-premise развёртыванием. По данным Сбера, 65% корпоративных контрактов на GigaChat Enterprise реализованы в формате on-premise или приватного облака.
СИБУР уже развернул GigaChat для диагностических ИИ-ассистентов (инженер описывает симптомы оборудования, система предлагает гипотезы ремонта) и оптимизатора закупок. Северсталь масштабировала ИИ до тысячи сотрудников ежедневно и более 60 решений за восемь лет. Подробнее о производственных кейсах – в руководстве по внедрению ИИ на производстве (скоро на сайте).
Для банков, оборонных предприятий и государственных подрядчиков это принципиально: данные не покидают периметр, модель соответствует требованиям 152-ФЗ, есть аудиторский след по требованиям ЦБ. ChatGPT, Claude и DeepSeek такого варианта не предлагают. Если ваша организация не может отправлять запросы в зарубежные облака – выбора нет, и этот раздел для вас.
Деловая переписка по ГОСТу
GigaChat обучался на корпусе российских государственных и корпоративных документов, и это ощущается при генерации формальных текстов: регистрационные номера, ссылочные строки, уровень формальности обращений, структура реквизитов. ChatGPT и DeepSeek на этих элементах чаще сбивают формат – путают порядок реквизитов, используют неформальный регистр в официальных письмах.
Оговорка: это наблюдение из практики, а не результат систематического тестирования. В нашем бенчмарке GigaChat показывает слабые результаты по категориям «коммуникация» и «региональная осведомлённость» – но бенчмарк тестирует аналитическое качество ответов, а не точность оформления документов. Если вы готовите официальные письма в ведомства – попробуйте GigaChat и сравните с привычным инструментом на конкретном шаблоне.
Юридические документы: форма – да, содержание – проверяйте
В 2025 году GigaChat уверенно опережал ChatGPT 4 на идентификации российских нормативных актов. В 2026 году разрыв закрылся: DeepSeek V4 Flash догнал и местами обходит GigaChat по точности ссылок на конкретные статьи (подробные тесты – в разделе «Граница возможностей» ниже). GigaChat по-прежнему лучше оформляет юридические документы – реквизиты, регистрационные номера, формальный стиль обращений. Но номера статей и логику выводов стоит перепроверять вне зависимости от модели.
Как промптить GigaChat: что реально работает
Если вы переносите промпты из ChatGPT в GigaChat без изменений – результаты будут хуже, чем могли бы. Модели обучались на разных корпусах и откалиброваны по-разному. Наш эксперимент с промпт-техниками на 1 717 запусках показал: правильный промпт улучшает ответы GigaChat на 20–30%.
Отдельная ловушка – «заплатки» в промптах. Типичная ситуация: промпт работал на GigaChat Pro, вы добавили оговорку «всегда ссылайся на источник», потом ещё одну – «не выдумывай факты», потом ещё – «отвечай строго по документу». Каждая заплатка решала конкретную проблему, но вместе они конфликтуют: модель пытается одновременно ссылаться на источник и не выдумывать, и в результате либо выдумывает ссылку, либо отказывается отвечать. Когда Сбер обновляет модель (а GigaChat обновляется без предупреждения), старые обходные решения начинают мешать. Перед тем как добавлять новые инструкции – проверьте, не дублируют ли они или не противоречат существующим.
Ниже – конкретные приёмы, проверенные на данных.
Императивная форма вместо вежливых вопросов
GigaChat обучался на российских государственных и корпоративных документах – там принят директивный стиль. Промпты в повелительном наклонении дают более конкретные ответы.
Проверьте на живом примере – оба промпта запускаются на одном и том же GigaChat, но первый написан как обычно пишут в ChatGPT, а второй адаптирован:
Наивный промпт даст GigaChat повод ответить «да, можно» и выдать общий обзор с упоминанием GDPR (который к российскому сервису не относится). Структурированный промпт – конкретную таблицу с номерами законов и мерами. Разница – в формулировке запроса.
Ролевое встраивание: важнее, чем в ChatGPT
В ChatGPT системная роль помогает, но текст промпта часто перевешивает. В GigaChat организационный контекст работает сильнее.
Слабо: «Проверь этот договор на соответствие 44-ФЗ.»
Сильнее: «Как главный юрист государственного заказчика, проанализируй проект договора на соответствие требованиям 44-ФЗ о контрактной системе. Заказчик – бюджетное учреждение, НМЦК до 3 млн рублей, закупка у единственного поставщика. Выдели пункты, требующие корректировки, и предложи формулировки.»
Второй вариант задаёт правовую позицию, контекст процедуры и конкретный результат – GigaChat лучше использует эту структуру, чем короткий запрос.
Трёхэтапная структура для сложных задач
Для юридических и комплаенс-запросов работает формула из трёх блоков: (1) роль и цель со ссылками на нормативку, (2) контекстные ограничения, (3) требуемый формат вывода.
Пример: «[1] Как юрисконсульт российской производственной компании, проведи правовой анализ проекта договора поставки на соответствие требованиям ГК РФ (главы 30, 25) и практике арбитражных судов. [2] Поставщик – ИП, покупатель – ООО, сумма договора 1,5 млн рублей, поставка в три этапа, предоплата 50%. [3] Результат: перечень рисков по разделам договора, рекомендуемые изменения формулировок, пункты, соответствующие практике арбитражных судов.»
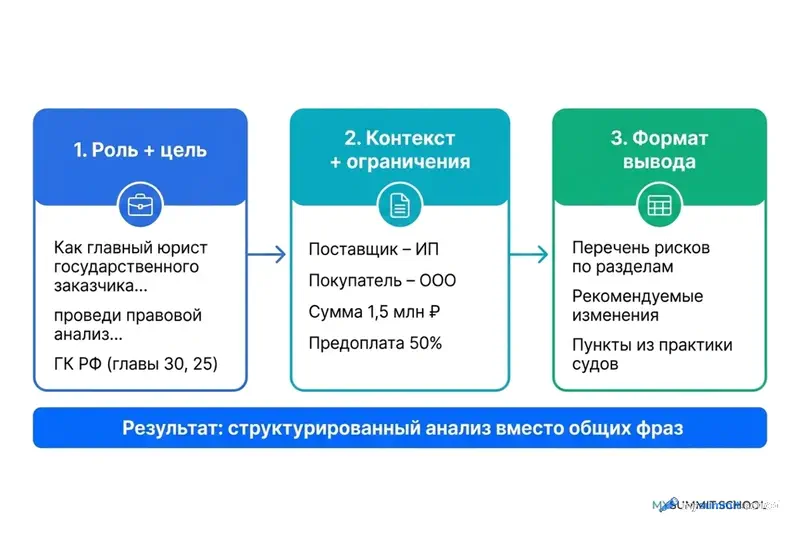
Эта структура снижает частоту поверхностных ответов – главную проблему GigaChat по данным нашего бенчмарка.
Если вы работаете через API: добавьте в параметры вызова стоп-последовательность (stop) с закрывающим тегом вашего формата – например, </ответ> или </результат>. Модель прекратит генерацию ровно в нужном месте, не добавляя «послесловий» и не сбивая парсинг. Это бесплатный приём – он не меняет промпт и не тратит дополнительные токены.
Приём встречных аргументов
На задачах в регуляторных серых зонах GigaChat склонен к уверенным, но не всегда точным ответам. Работающий приём: перед итоговым выводом запросить аргументы с обеих сторон.
«Перечисли три аргумента в пользу того, что данная деятельность подпадает под лицензирование, и три аргумента против. Затем дай итоговую оценку с указанием, какие факты были бы решающими.»
Это вынуждает модель рассмотреть альтернативные трактовки до формулировки позиции – галлюцинации на нормативных вопросах становятся реже.
За этим приёмом стоит более общий принцип: когда вы ограничиваете модель, всегда указывайте обе стороны компромисса.
Слабо: «Отвечай конкретно. Не давай расплывчатых формулировок. Каждое утверждение подкрепляй ссылкой на нормативный акт.»
Сильнее: «Отвечай конкретно, но если в каком-то пункте ты не уверен в точности ссылки – скажи прямо. Неточная ссылка на статью закона опаснее, чем честное “требует проверки по первоисточнику”.»
Первый вариант подталкивает GigaChat к уверенным, но непроверенным утверждениям – модель заполнит каждый пункт ссылкой, даже если «помнит» её неточно. Второй вариант даёт модели пространство для корректного поведения в обоих направлениях. Наш эксперимент подтвердил это на данных: агрессивный тон в промпте полностью подавил у GigaChat признание неуверенности – модель перестала оговариваться, но точнее не стала. Фактическая точность при этом упала с 71% до 70%.
Лимит контекста: 25 000 токенов
Контекстное окно GigaChat 2 Max – 32 000 токенов, у конкурентов от 128 000 и выше. Для надёжной работы держите запросы в пределах 25 000 – выше качество деградирует. Практический приём: «ФЗ-44» вместо «Федеральный закон от 05.04.2013 № 44-ФЗ „О контрактной системе в сфере закупок товаров, работ, услуг для обеспечения государственных и муниципальных нужд"» – разница в токенах существенная при работе с объёмными документами.
Подробнее о промптинге в целом – в статье о базовых принципах структуры промптов и о распространённых мифах.
Промпт-техники – это минимум, который работает без дополнительных затрат. Но чтобы применять их осмысленно, нужно понимать, когда GigaChat выдаёт нормальный результат, а когда уверенно ошибается – и вы этого не замечаете. Именно эту границу мы сейчас проверим на реальных задачах.
Промпт-техники из этой статьи выжимают 20–30% из GigaChat. Навык проверки ответа одинаков для любой модели – GigaChat, DeepSeek или Claude. В открытом модуле курса вы отрабатываете его на 9 управленческих задачах и учитесь отличать хороший результат от галлюцинации. Бесплатно.
Доступ сразу после регистрации
Граница возможностей: что не исправить промптами
Промпты реорганизуют то, что модель уже знает – они не создают знания, которых нет в весах. Наш эксперимент «Make Weak Model Great Again» показал это на данных: если GigaChat не «видел» нужный нормативный акт при обучении, никакой промпт «ты опытный юрист по ТК РФ» не заставит его процитировать кодекс правильно.
Чтобы понять, где проходит эта граница, мы прогнали GigaChat и DeepSeek V4 Flash через две реальные задачи.
Тест 1: управленческий кризис
На что обратить внимание: GigaChat через API выдаёт структурированный, но общий план – все действия назначены на «руководителя проекта», метрики вроде «положительные отзывы», без приоритизации по дням. DeepSeek V4 Flash разделит симптомы от корневых причин, распределит ответственность между конкретными ролями и предупредит, чего делать не стоит.
GigaChat Ultra через веб-интерфейс даёт результат заметно лучше – распределяет роли, добавляет eNPS и протоколы. Но Ultra доступен только в вебе, не через API. А в reasoning-режиме Ultra допустил фактическую ошибку: предложил «организовать передачу знаний от ушедших разработчиков» – хотя в условии задачи они ушли к конкуренту месяц назад. Подробнее о том, почему reasoning-режим вредит, – ниже.
Тест 2: российская нормативка (152-ФЗ)
Это задача, где GigaChat должен быть на своей территории. Проверьте три вещи: (1) какая модель правильно разделяет специальные категории (ст. 10) и биометрию (ст. 11), (2) какая замечает, что портал выходит за рамки трудовых отношений и уведомление Роскомнадзора обязательно, (3) какая не путает номера статей.
В наших тестах GigaChat на API-модели перепутал ст. 9 (согласие) со ст. 10 (специальные категории). DeepSeek V4 Flash правильно назвал все применимые статьи, разделил категории данных и указал суммы штрафов по КоАП. GigaChat Ultra в простом режиме справился лучше – правильно назвал ст. 10 и ст. 11 – но Ultra доступен только в веб-интерфейсе, не через API.
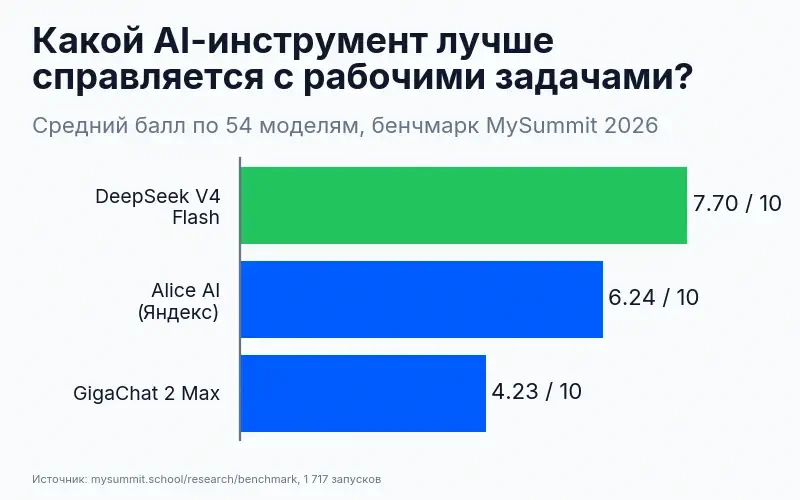
Честный вывод: преимущество GigaChat на юридических задачах было реальным в 2025 году при сравнении с ChatGPT 4. В 2026 году DeepSeek V4 Flash закрыл этот разрыв. GigaChat по-прежнему лучше по форме документов (реквизиты, регистрационные номера, формальный стиль), но по содержанию – точности ссылок и логике выводов – разница исчезла.
Ловушка reasoning-режима
Отдельное предупреждение: не используйте reasoning-режим GigaChat для задач, требующих точных ссылок.
Мы проверили одну и ту же юридическую задачу на GigaChat Ultra в двух режимах. В простом режиме модель правильно назвала ст. 10 и ст. 11. В reasoning-режиме сослалась на ст. 8 (общедоступные источники – не имеет отношения к задаче) и пропустила ст. 11 вовсе. Рассуждения выглядели логично, но привели к ошибочным ссылкам.
Это подтверждает исследование Wei et al. (Google Brain, 2022) и наши данные из эксперимента MWMGA: Chain-of-Thought у небольших моделей провоцирует уверенные, но неправильные рассуждения. Модель генерирует пять шагов, которые выглядят логично, и приходит к ошибочному выводу. По этой же причине не просите GigaChat «улучшить свой ответ» – исследования (Zhang et al., ACL 2024) показали: малые модели не способны обнаружить собственные ошибки и вместо критики просто переформулируют тот же ответ.
Практическое правило: задайте правильную структуру с первого запроса (трёхэтапная формула выше). Не итерируйте, не включайте reasoning – лучше не станет.
Эти тесты показывают конкретную вещь: разница между хорошим и плохим результатом – не в выборе модели, а в умении проверить ответ. GigaChat назвал ст. 9 вместо ст. 10, и если вы не знаете, что специальные категории – это ст. 10, вы примете ошибку за правду. Курс учит именно этому: отличать надёжный ответ от уверенной галлюцинации.
GigaChat перепутал ст. 9 и ст. 10. Вы бы заметили? В открытом модуле курса – 9 задач, где вы учитесь проверять AI-ответы на реальных управленческих ситуациях. Бесплатно.
Доступ сразу после регистрации
Когда переключаться на другой инструмент
Наш эксперимент MWMGA показал: правильный выбор модели под задачу даёт больший прирост результата, чем совершенствование промптов для неподходящей модели. Лояльность к инструменту – дорогостоящая привычка.
Даже если GigaChat – ваш основной инструмент, есть задачи, которые стоит переадресовать:
| Задача | GigaChat справится? | Альтернатива |
|---|---|---|
| Деловая переписка по ГОСТу | Попробуйте – по нашим наблюдениям, лучше по форме | Сравните с DeepSeek на вашем шаблоне |
| Черновик юридического документа | Форма – да, содержание – проверяйте | DeepSeek V4 Flash для перекрёстной проверки ссылок |
| Анализ, планирование, сложные рассуждения | Слабо – 4,23/10 в бенчмарке | DeepSeek / Claude / ChatGPT |
| Длинные документы (>25K токенов) | Нет – качество деградирует | Claude / Gemini (контекст 128K+) |
| Генерация кода | Слабо – на 25–35% хуже | DeepSeek |
| Международное регулирование | Нет – точность падает до 65% | ChatGPT / Claude |
| Креативные задачи | Слабо – на 40% ниже по новизне | ChatGPT |
DeepSeek V4 Flash доступен в России без VPN, стоит около 25 рублей за миллион токенов и показывает 7,7/10 в нашем бенчмарке – против 4,23 у GigaChat. Alice AI от Яндекса – 6,24, тоже заметно выше. Сравнение российских альтернатив – в обзоре YandexGPT и полном сравнении инструментов.
Если у вас закрытый контур и переключение невозможно – это не приговор, а рабочие условия. Вот как выглядит эффективный процесс: юрист из банка получает проект договора, прогоняет его через GigaChat с трёхэтапной формулой (роль + ограничения + формат), получает структурированный черновик анализа за три минуты вместо часа. Затем проверяет номера статей по первоисточнику – это занимает ещё десять минут. Итого: задача на полтора часа закрыта за пятнадцать минут, при этом юрист точно знает, какие части ответа надёжны, а какие требуют ручной проверки.
Ключевой навык здесь – умение отличить надёжную часть ответа от галлюцинации. Промпты организуют то, что модель уже знает, – они не создают знания.
Сколько это стоит на практике
Честная картина из нашего реального использования: мы купили пакет на 6 млн токенов за 3 450 рублей. За месяц сделали около 900 запросов – и фактически использовали меньше пятой части пакета. Реальная стоимость токена вышла в 5,6 раза выше номинала.
Это особенность пакетной модели: если у вас нет стабильного высокого объёма, вы переплачиваете. Токены теперь переносятся 90 дней (изменение 2026 года), что немного смягчает ситуацию.
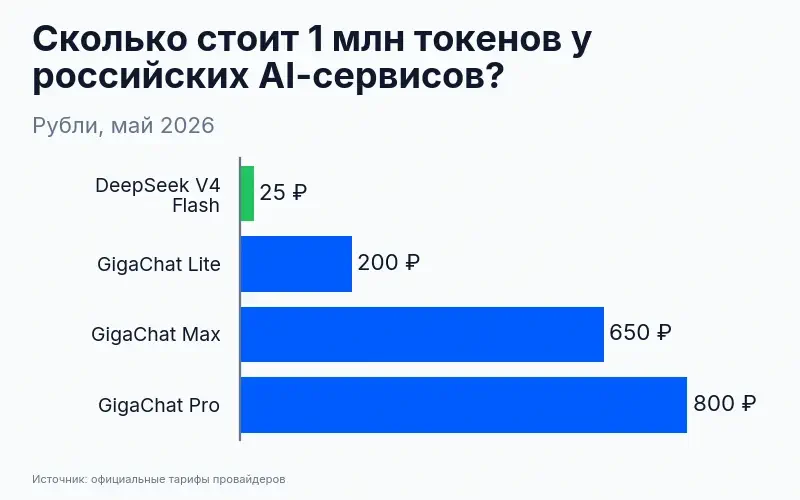
По тарифам: Lite (~200 рублей за миллион токенов) закрывает около 90% рутинных задач – черновики, суммаризация, простые письма. Pro (~800 рублей) – оптимальный вариант для регуляторной работы. Max (~650 рублей) позиционируется как флагман, но наш бенчмарк показал 4,23/10 – переплачивать за Max на задачах, где GigaChat в принципе не силён, смысла нет.
Для сравнения: DeepSeek V4 Flash – 25 рублей за миллион токенов при 7,7/10. Подробнее – в обзоре DeepSeek и сравнении AI-инструментов.
Если вы пользуетесь GigaChat через веб-интерфейс, а не через API – подписка GigaChat Plus стоит 399 рублей в месяц и включает доступ к Ultra. Для большинства задач из этой статьи этого достаточно. Пакетная модель через API оправдана при предсказуемом высоком объёме – юридический отдел из десяти человек, ежедневно анализирующий договоры. Для эпизодического использования платить за пакет наперёд нерационально.
Памятка: правила работы с GigaChat

Делайте:
- Пишите в повелительном наклонении: «подготовь», «укажи», «сформируй»
- Задавайте роль с контекстом: «Как главный юрист государственного заказчика…»
- Используйте трёхэтапную формулу: роль + ограничения + формат
- Требуйте таблицы и структуру в формате ответа
- Запрашивайте аргументы «за» и «против» перед выводом
- Указывайте обе стороны компромисса: не только «отвечай конкретно», но и «если не уверен – скажи прямо»
- Держите запрос в пределах 25 000 токенов
- Проверяйте промпт на конфликтующие инструкции перед добавлением новых
Не делайте:
- Не включайте reasoning-режим для задач со ссылками на нормативку
- Не просите «улучшить» или «найти слабые места в своём ответе»
- Не полагайтесь на номера статей без перепроверки
- Не используйте GigaChat для документов длиннее 25K токенов
- Не переплачивайте за Max на задачах анализа и планирования
- Не давите на модель агрессивным тоном – она станет увереннее, но не точнее
Перепроверяйте всегда, когда GigaChat называет конкретные статьи, цифры или факты. Модель звучит уверенно вне зависимости от того, правильный ответ или нет.
Промпт написан. А ответ – правильный?
Главный навык работы с AI – проверка результата. В фундаментальном модуле курса вы разбираете критическое мышление с AI на реальных управленческих задачах: как отличить глубокий анализ от поверхностного, когда доверять ссылкам и когда перепроверять. Начните с бесплатного диагностического модуля: 9 уроков, без регистрации.
















Stanislav Belyaev
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.