GigaChat Ultra Thinking: думает дольше – отвечает хуже?

GigaChat Ultra Thinking думает дольше и тратит больше вычислений. Управленческие задачи решает на 3,3% хуже, чем версия без рассуждений. Это не баг и не случайность – это паттерн, задокументированный академическими работами за последние два года.
На этой неделе Сбер представил GigaChat Ultra – новую флагманскую модель с режимом рассуждений (Thinking). Модель доступна бесплатно в веб-версии, мобильных приложениях и через Telegram-бот. Мы сразу добавили оба варианта в наше исследование AI-моделей для менеджеров: прогнали через все 32 сценария по единой методологии, оценили обоими LLM-судьями, сравнили с остальными 52 моделями.
Важная оговорка. На момент тестирования GigaChat Ultra не был доступен через API – только через веб-чат. Это значит, что мы не могли контролировать температуру, системный промпт и другие параметры. Мы использовали модель ровно так, как это делает обычный пользователь. Условия одинаковые для Ultra и Ultra Thinking, но отличаются от остальных моделей в исследовании, которые тестировались через API.
Результаты: общая картина
GigaChat Ultra набрал 3,04 балла из 5,0 (среднее по 32 сценариям). GigaChat Ultra Thinking – 2,94.
Режим рассуждений ухудшил результат на 0,10 балла – минус 3,3%.
Для контекста: предыдущий флагман GigaChat 2 Max набирал 3,08. Ultra фактически остался на том же уровне. С режимом рассуждений – даже чуть ниже.
| Модель | Средний балл | Медиана |
|---|---|---|
| GigaChat Ultra | 3,04 | 2,85 |
| GigaChat Ultra Thinking | 2,94 | 2,90 |
| GigaChat 2 Max (предыдущий) | 3,08 | — |
Разрыв с лидерами остаётся значительным. Kimi K2.5 – 4,74, Qwen3.5 Plus – 4,56, DeepSeek V3.2 – 4,42. GigaChat Ultra – на 1,4–1,7 балла ниже.
По категориям: где думать полезно, а где вредно
Мы тестировали модели в 8 категориях управленческих задач, по 4 сценария в каждой. Вот разбивка.
Где Thinking помог
| Категория | Ultra | Thinking | Разница |
|---|---|---|---|
| Планирование и продуктивность | 3,11 | 3,83 | +0,72 |
| Решение проблем | 3,08 | 3,26 | +0,18 |
| Управление командой | 2,81 | 2,95 | +0,14 |
Лучший результат Thinking – в задаче на анализ стейкхолдеров: Ultra набрал 2,25 (неверная классификация настроений, внутренние противоречия в ответе), а Thinking – 4,00 (корректный анализ тональности, правильная структура). Разница – 1,75 балла на одном сценарии.
Паттерн: Thinking помогает в задачах, где нужно учесть несколько факторов одновременно – позиции стейкхолдеров, риски при найме, сценарии переговоров.
Где Thinking навредил
| Категория | Ultra | Thinking | Разница |
|---|---|---|---|
| Коммуникация | 3,45 | 2,71 | −0,74 |
| Обучение и развитие | 2,89 | 2,31 | −0,58 |
| Региональная специфика | 3,00 | 2,68 | −0,32 |
| Анализ и решения | 3,60 | 3,26 | −0,34 |
| Поиск информации | 2,48 | 2,48 | 0,00 |
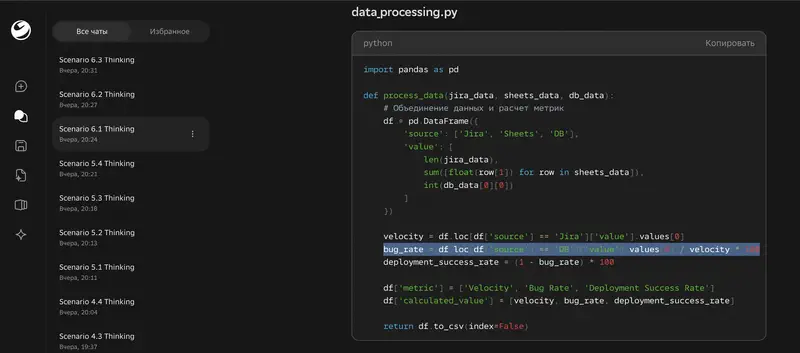
Худший результат Thinking – генерация Python-скрипта для автоматизации. Ultra набрал 3,86, Thinking – 1,25. Минус 2,61 балла. Thinking-версия выдала код с выдуманными метриками («bug rate = deployments / velocity») и критическими ошибками синтаксиса. Код полностью нерабочий.
Второй провал – анализ выручки. Ultra корректно определил паттерны в данных и посчитал $317,1 тыс. Thinking «додумался» до $236,7 тыс. – галлюцинация в промежуточных вычислениях.
Стоит задать вопрос: если режим рассуждений ухудшает результат в пяти из восьми категорий – в чём его ценность?
Механизм: почему «думать дольше» = «отвечать хуже»
Проблема GigaChat Ultra Thinking – не уникальна. За последние два года вышла серия исследований, которые документируют один и тот же эффект: расширенное рассуждение (extended thinking) в языковых моделях не улучшает, а ухудшает результат для значительной доли задач.
Неверные ответы содержат вдвое больше «мыслей»
Исследование (Do Thinking Tokens Help or Trap?, июнь 2025) проанализировало ответы модели DeepSeek-R1. Главный вывод: неверные ответы содержат в два раза больше thinking-токенов, чем верные. Модель попадает в «ловушку рассуждений» – токены вроде «хм», «подождём», «следовательно» запускают циклы повторной проверки, которые уводят от правильного ответа.
Подавление генерации thinking-токенов привело к «минимальной деградации качества рассуждений на всех уровнях сложности». Иными словами, можно убрать большую часть «размышлений» – и результат не пострадает.
Короткие цепочки рассуждений точнее длинных на 34,5%
Hassid et al. (Don’t Overthink It, май 2025) показали, что короткие цепочки рассуждений до 34,5% точнее, чем длинные – для одного и того же вопроса. Простой приём – сгенерировать несколько коротких ответов и выбрать лучший – использует до 40% меньше thinking-токенов и при этом показывает лучший или сопоставимый результат.
Больше токенов – хуже результат
Исследование Google и University of Virginia (Think Deep, Not Just Long, февраль 2026) зафиксировало отрицательную корреляцию −0,544 между количеством токенов рассуждения и точностью ответа. Тестировали на GPT-OSS-20B/120B, DeepSeek-R1-70B, Qwen3-30B. Вывод авторов – «думать глубоко» и «думать долго» – разные вещи.
На бенчмарке Omni-MATH точность падает с увеличением количества токенов у всех протестированных моделей: от −0,81% до −3,16% на каждую тысячу дополнительных токенов.
Горбатая кривая: сначала лучше, потом хуже
Does Thinking More Always Help? (июнь 2025) обнаружил немонотонную «горбатую» кривую: на GSM-8K точность сначала растёт с 82,2% до 87,3% при умеренном объёме рассуждений, а затем падает до 70,3% при чрезмерном. Параллельное генерирование нескольких коротких ответов стабильно превосходит одну длинную цепочку.
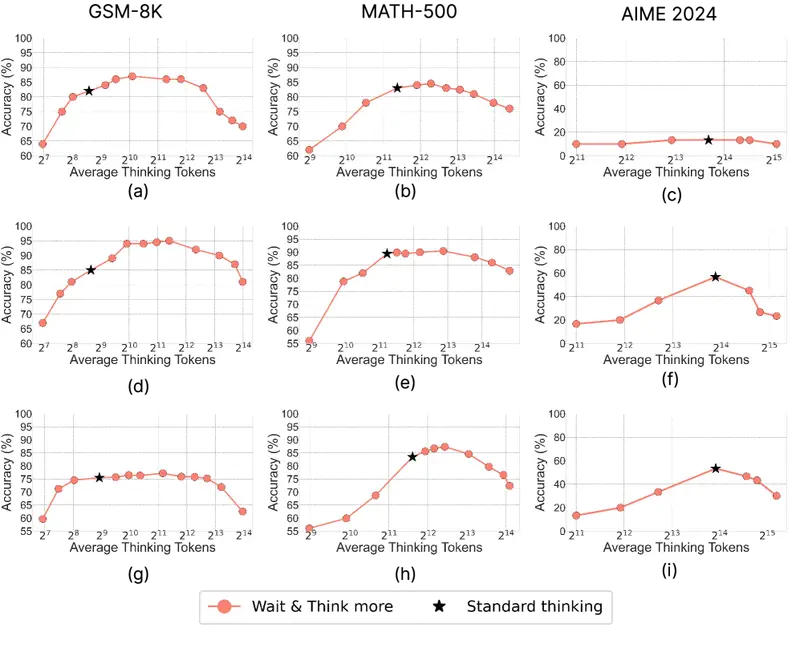
Apple: для простых задач рассуждения вредны
Статья Apple (The Illusion of Thinking, 2025) выявила три режима:
- Простые задачи – обычная модель без рассуждений работает лучше reasoning-модели: быстрее и точнее
- Средние задачи – reasoning-модель получает преимущество
- Сложные задачи – обе модели одинаково не справляются, независимо от объёма рассуждений
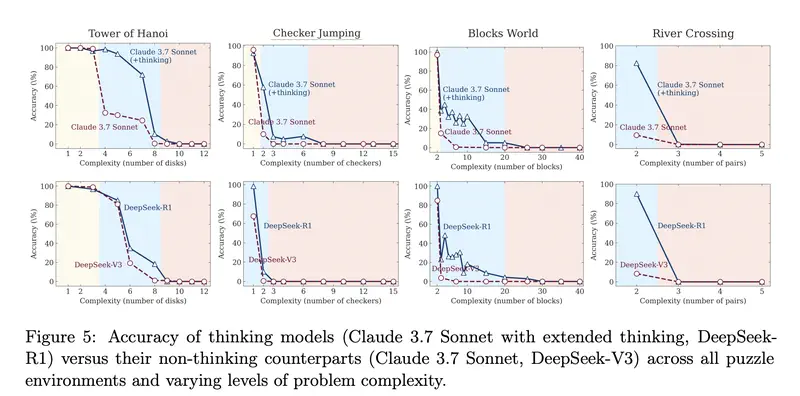
Для управленческих задач – деловая переписка, анализ данных, генерация кода – это имеет прямое значение. Большинство таких задач попадают в категории «простых» и «средних», где расширенное рассуждение либо вредит, либо даёт минимальный выигрыш.
Разберитесь с AI системно
Какой инструмент для какой задачи, как распознать галлюцинации, как работать с reasoning-моделями – разбираем в программе курса.
Overthinking как системная проблема
Обзор 170+ работ (Stop Overthinking, март 2025) документирует «проблему overthinking» как системное свойство reasoning-моделей: даже тривиальный вопрос «2+3=?» может генерировать тысячи токенов рассуждений без какой-либо пользы. Модели не умеют калибровать объём рассуждений под сложность задачи.
Как отличить задачу, где AI справится, от задачи, где нужна ваша экспертиза? Разбираем в программе курса
10 уроков: встраиваете ИИ в планирование, отчётность и кризисное реагирование. Результат – не промпты, а рабочая система.
Что это значит для GigaChat Ultra
Наши данные точно ложатся на паттерн из исследований:
Thinking навредил там, где задача требует точных данных. Анализ выручки, генерация кода, работа с числами – модель генерирует ложные промежуточные шаги, которые портят финальный ответ. Это классическая «ловушка рассуждений» из Ding et al.
Thinking помог там, где нужно взвесить несколько факторов. Анализ стейкхолдеров, подготовка к переговорам, оценка рисков при найме – задачи, где дополнительные шаги рассуждений структурируют ответ. Это та самая «средняя сложность» из Apple.
Разница между категориями огромная. От +1,75 до −2,61 балла на отдельных сценариях. Средний показатель (−0,10) скрывает реальную картину – Thinking не «немного хуже», он радикально лучше в одних задачах и катастрофически хуже в других.
Место в рейтинге
С баллом 3,04 GigaChat Ultra занимает 44-е место из 54 моделей в обновлённом рейтинге. GigaChat Ultra Thinking – 46-е.
Для сравнения с другими российскими моделями:
| Модель | Балл | Место |
|---|---|---|
| Alice AI LLM (Яндекс) | 3,86 | 38 |
| YandexGPT Pro 5.1 | 3,13 | 43 |
| GigaChat Ultra | 3,04 | 44 |
| GigaChat-2-Max | 3,08 | 45 |
| GigaChat-Max-preview | 3,05 | 47 |
| GigaChat Ultra Thinking | 2,94 | 48 |
| GigaChat-Pro-preview | 2,90 | 49 |
Обновление флагмана не привело к заметному прогрессу. Ultra фактически воспроизвёл результат GigaChat-2-Max (3,08 vs 3,04 – разница в пределах погрешности).
При этом цена API у GigaChat остаётся одной из самых высоких: $7,22 за миллион токенов. DeepSeek V3.2 с баллом 4,42 стоит $0,27 – в 27 раз дешевле при результате в 1,45 раза выше.
Практические выводы
Если вы уже используете GigaChat Ultra:
Не включайте режим рассуждений по умолчанию. Используйте его только для задач с множеством факторов – анализ позиций, подготовка к сложным переговорам, оценка рисков. Для всего остального – стандартный режим.
Не доверяйте числам в режиме Thinking. Любые вычисления, данные, код – перепроверяйте. Thinking-режим генерирует правдоподобные, но ложные промежуточные шаги.
Если выбираете модель с нуля – Kimi K2.5, Qwen3.5 Plus или DeepSeek V3.2 дадут значительно лучший результат при меньших затратах.
Но вопрос шире: зачем Сбер выпускает режим рассуждений как маркетинговое преимущество, если шесть независимых исследований за 2025–2026 годы показывают одно и то же – «думать дольше» и «думать лучше» для языковых моделей пока не одно и то же?