GLM-5: от вайб-кодинга к ИИ-агентам
Zhipu AI и Университет Цинхуа выпустили модель GLM-5 на 744 миллиарда параметров – и впервые в истории open-weight модель набрала 50 баллов на Artificial Analysis Intelligence Index, встав рядом с Claude Opus 4.5 и GPT-5.2. Мы делали обзор GLM-5 ещё в марте – тогда модель ещё не раскрыла своего главного козыря. Но интереснее самой модели – эксперимент, который авторы провели перед релизом. И термин, который они ввели для описания сдвига, происходящего прямо сейчас.
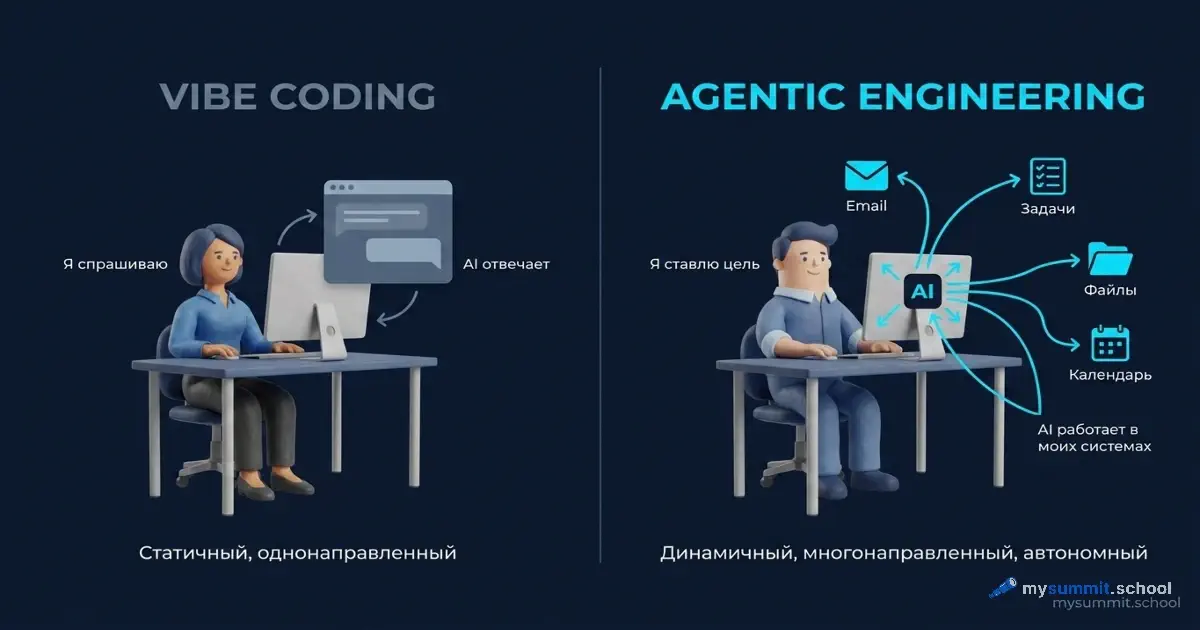
Статья построена вокруг одного тезиса из работы: мы переходим от «вайб-кодинга» – когда человек даёт ИИ задачу и получает ответ – к «агентному инжинирингу», где ИИ-агент сам планирует, исполняет, проверяет и корректирует работу на длинных горизонтах. Этот переход меняет не технологию. Он меняет роль менеджера.
Эксперимент Pony Alpha: когда модель говорит сама за себя
Перед официальным анонсом Zhipu AI сделали неожиданный ход. Они загрузили GLM-5 на платформу OpenRouter под псевдонимом «Pony Alpha» – без указания авторства, без маркетинга, без бренда. Просто ещё одна модель в каталоге.
За несколько дней Pony Alpha стала сенсацией. Разработчики и пользователи начали гадать, кто за ней стоит. По данным авторов: 25% считали, что это Claude Sonnet 5, 20% – DeepSeek, 10% – Grok. Оставшиеся распределились между другими гипотезами. Когда Zhipu AI раскрыли карты, реакция сообщества была однозначной: китайская open-weight модель конкурирует с лучшими закрытыми на равных.
Цитата из статьи: «Анонимный релиз позволил нам преодолеть геополитические предубеждения. Сообщество приняло модель, потому что она работала».
Для менеджера здесь важен не факт китайского происхождения, а следствие: рынок моделей стал конкурентным настолько, что бренд перестал быть гарантией качества. Модель, которую вы не рассматривали, может оказаться лучше той, за которую вы платите. Это аргумент не за конкретного поставщика, а за умение оценивать результат по существу – а не по логотипу.
Вайб-кодинг и агентный инжиниринг: о чём речь
Авторы GLM-5 вводят разделение, которое точно описывает текущий переход в использовании ИИ.
Вайб-кодинг – это когда человек пишет промпт, модель отвечает. Один вопрос – один ответ. Или несколько раундов в чате, но инициатива всегда у человека. Вы копируете текст из одной вкладки в другую, правите результат, запускаете заново. Так работает большинство менеджеров с ChatGPT сегодня.
Агентный инжиниринг – это когда ИИ-агент получает цель и самостоятельно планирует шаги, выполняет их, проверяет результат и корректирует курс. Человек не пишет каждый промпт – он ставит задачу и оценивает итог.
Из статьи: «В вайб-кодинге человек заставляет ИИ писать код. В агентном инжиниринге агенты пишут код сами. Они планируют, реализуют и итерируют».
Разница – не в сложности инструмента. Разница – в длине горизонта задачи. Вайб-кодинг работает для задач, которые решаются за один ход: «напиши письмо», «сделай таблицу», «перепиши текст». Агентный инжиниринг нужен там, где задача растягивается на десятки шагов: «проанализируй все письма от клиента за квартал, сверь с задачами в трекере, найди расхождения, подготовь сводку для встречи».
Именно для таких длинных задач созданы протоколы вроде MCP (Model Context Protocol) – стандарт подключения агента к внешним системам: почте, таск-трекеру, файловой системе, базе данных. Мы разбирали этот подход в статье про агентный анализ данных. MCP-Atlas, один из бенчмарков в статье GLM-5, как раз проверяет, насколько модель умеет пользоваться реальными MCP-серверами.
Бенчмарк, который понятен без перевода
Среди десятка бенчмарков в статье есть один, который стоит разобрать подробнее – Vending-Bench 2.
Суть: ИИ-агенту дают управлять виртуальным вендинговым бизнесом на протяжении целого симулированного года. Агент принимает решения о закупках, ценообразовании, ассортименте, реагирует на сезонность и конкурентов. Оценка – финальный баланс на банковском счёте.
Результаты:
| Модель | Итоговый баланс |
|---|---|
| GPT-5.2 (xhigh) | $5 478 |
| Claude Opus 4.5 | $4 967 |
| GLM-5 | $4 432 |
| DeepSeek-V3.2 | $3 591 |
| Kimi K2.5 | $1 034 |
GLM-5 заработала больше DeepSeek на 23% и стала лучшей среди open-weight моделей. Но обратите внимание на разрыв между лидерами и Kimi K2.5: пятикратный. Это не значит, что Kimi – плохая модель. Это значит, что длинные автономные сценарии – другая дисциплина, где сила модели в коротких диалогах не гарантирует успеха.
Хотя бенчмарки – инструмент неидеальный, Vending-Bench ценнее для менеджера, чем любой тест на написание кода. Он проверяет именно то, что нужно в реальной работе: способность агента принимать связные решения на длинном горизонте, адаптироваться к меняющимся условиям и не терять контекст.
Переход от чат-промптов к ИИ-агентам – это навык, который стоит освоить. В открытом модуле курса – 9 практических задач менеджера, которые покажут, где вы уже умеете работать с ИИ и где скрытые ошибки стоят вам времени. Бесплатно.
Доступ сразу после регистрации
Почему агенты теряют контекст – и что с этим делать
Один из самых практичных разделов статьи GLM-5 – про деградацию качества при длинных сессиях. Проблема знакома каждому, кто пробовал давать ChatGPT сложную задачу в длинном чате: после 10–15 итераций модель начинает «забывать» ранние инструкции, повторяться и галлюцинировать.
Авторы приводят конкретные числа. На бенчмарке BrowseComp (поиск информации в интернете с десятками шагов):
- Без управления контекстом: 55,3% точности
- С сохранением последних 5 раундов взаимодействия: 62,0%
- С полной иерархической системой (сворачивание старых результатов + перезапуск при превышении 32 000 токенов): 75,9%
Рост с 55% до 76% – это не тюнинг модели. Это инженерия процесса. Модель та же, меняется способ управления её вниманием.
Для менеджера вывод прямой: если ваш агент начал «тупить» на длинной задаче – проблема, вероятно, не в модели. Проблема в том, что контекстное окно переполнено, и агент буквально не видит ваших ранних инструкций. Решение – не «перейти на более умную модель», а структурировать работу агента: разбивать задачи на этапы, сохранять промежуточные результаты, периодически «обнулять» контекст с кратким резюме сделанного.
Ты – менеджер проектов. Я дам тебе переписку с клиентом за последние 3 месяца и список задач из трекера. Шаг 1: Прочитай переписку и выпиши все обещания, которые мы дали клиенту (с датами). Шаг 2: Сопоставь каждое обещание с задачей в трекере. Укажи статус: выполнено / в работе / нет задачи. Шаг 3: Для каждого расхождения предложи формулировку для письма клиенту. Важно: после каждого шага выведи промежуточный результат. Не переходи к следующему шагу, пока я не подтвержу.
Промпт выше работает в любом чат-интерфейсе, но обратите внимание на структуру: пошаговое исполнение с промежуточными остановками. Это ручной аналог того, что GLM-5 делает автоматически через иерархическое управление контекстом. Разбить задачу на этапы с контрольными точками – простейший способ не потерять качество на длинном горизонте.
Агентные бенчмарки: что стоит отслеживать
Статья GLM-5 интересна ещё и как каталог новых бенчмарков, которые проверяют не «знания» модели, а её способность работать автономно. Вот ключевые:
MCP-Atlas – модель подключается к реальным MCP-серверам и решает задачи, используя инструменты. GLM-5 набрала 67,8 балла, Claude Opus 4.5 – 63,8, Kimi K2.5 – 52,0. Это прямой тест на то, насколько модель умеет пользоваться внешними системами – почтой, базами данных, API.
BrowseComp – многошаговый поиск информации в интернете. GLM-5: 75,9, Claude Opus 4.5: 74,9, DeepSeek: 67,6. Агент должен не просто найти ответ, а спланировать стратегию поиска, оценить источники и синтезировать результат.
tau-2-Bench – диалоговые агенты в сценариях поддержки клиентов. Claude Opus 4.5: 91,6, GLM-5: 89,7. Здесь модели близки, но сам бенчмарк показателен: агент ведёт полноценный диалог, принимает решения и выполняет действия от имени компании.
SWE-rebench – исправление реальных багов из свежих GitHub-issues (январь 2026). Claude Opus 4.6: 52,9%, GPT-5.2: 51,7%, GLM-5: 42,1%. Это самый сложный тест: агент работает с незнакомым кодом, в незнакомом репозитории, и должен не только найти проблему, но и написать исправление, которое пройдёт тесты.
Общая картина: GLM-5 стабильно входит в тройку на агентных бенчмарках. На некоторых обходит Claude. На кодовых – пока отстаёт. Для open-weight модели это беспрецедентный результат.
Но важнее отдельных цифр – сам факт: индустрия перестала мерить модели только по знаниям и точности ответов. Новые бенчмарки проверяют именно то, что нужно менеджеру: способность агента планировать, пользоваться инструментами, работать автономно и не терять нить на длинных задачах.
Агентные бенчмарки оценивают то же, что и реальная работа: планирование, инструменты, длинный горизонт. В открытом модуле – 9 задач менеджера, которые покажут вашу реальную готовность к работе с ИИ. Бесплатно.
Доступ сразу после регистрации
Что это значит для вашей работы
Pony Alpha доказал неприятную вещь: пользователи не отличают китайскую open-weight модель от Claude, пока не знают авторство. Наш анализ 53 моделей показал то же самое с другой стороны – разница в качестве между топом и серединой минимальна при разнице в цене в сотни раз. Если вы до сих пор выбираете модель по бренду, вы переплачиваете. Для российских пользователей это ещё актуальнее: open-weight модели (GLM, DeepSeek, Qwen) работают без VPN и без санкционных ограничений.
Но вот что действительно удивляет в данных GLM-5: пятикратный разрыв между GPT-5.2 ($5 478) и Kimi K2.5 ($1 034) на Vending-Bench. Та же модель, которая отлично пишет письма и проводит анализ, проваливает планирование на горизонте в десятки шагов. Почему? Потому что длинная автономная работа – это другая дисциплина. Прежде чем доверять агенту задачу на 30 шагов, протестируйте его на коротких фрагментах. Разбейте процесс на этапы с контрольными точками.
И третий вывод – самый практичный. Рост точности с 55% до 76% за счёт правильной работы с контекстным окном. Это структура: промежуточные резюме, разбивка на этапы, периодическая «перезагрузка» чата с сохранением ключевых решений. Навык, который переносится между моделями и инструментами. Модель сменится через полгода – навык останется.
Я использую [название модели] для [тип задачи]. Последние 2 недели замечаю, что на длинных сессиях (больше 10 сообщений) качество падает: модель начинает повторяться, забывает ранние инструкции, добавляет информацию, которую я не просил. Помоги мне разработать протокол работы: 1. Как разбить мою типичную задачу на этапы, чтобы каждый этап умещался в 5–7 сообщений? 2. Какую информацию сохранять между этапами, а какую можно отбросить? 3. Как формулировать «стартовое сообщение» для нового этапа, чтобы модель быстро восстановила контекст? Моя типичная задача: [опишите]
От эксперимента к системе
Статья GLM-5 фиксирует момент перехода. Вайб-кодинг – режим, в котором большинство менеджеров работает с ИИ сегодня – достиг потолка. Копирование между вкладками, ручная передача контекста, разовые промпты без связи друг с другом. Это работает для простых задач и перестаёт работать, когда задача требует десятков связных шагов.
Агентный инжиниринг – следующий режим: агент читает ваши файлы, ходит в ваши системы, работает автономно и отчитывается о результате. Переход к нему требует нового навыка: умения формализовать свою работу так, чтобы агент мог её исполнить.
Стоит ли ожидать, что большинство менеджеров совершит этот переход в ближайший год? Скорее нет. Большинство пока даже промпты не структурирует – и это нормально. Но данные из статьи GLM-5 показывают, куда движется рынок: модели уже умеют работать автономно, бенчмарки уже измеряют именно это, и разрыв между теми, кто научился ставить задачи агентам, и теми, кто копирует текст из ChatGPT – будет только расти.
GLM-5 сегодня обгоняет Claude на MCP-Atlas и проигрывает на SWE-rebench. Через полгода расстановка изменится. Навык формализации, управления контекстом и калибровки доверия к агенту – переживёт любую смену моделей.
Инструменты выбраны. Следующий шаг – система
Курс учит работать с ИИ системно: от критической оценки ответов модели до автоматизации менеджерских рутин. Фундамент даёт навык, который переживёт смену моделей – умение формализовать свою работу так, чтобы агент мог её исполнить.



Часто задаваемые вопросы
Что такое GLM-5 и кто его разработал?
Чем агентный инжиниринг отличается от вайб-кодинга?
Что такое эксперимент Pony Alpha?
Что такое Vending-Bench и зачем он менеджерам?

Stanislav Belyaev
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.