Как оценивают качество нейросетей в 2026: бенчмарки LLM для менеджера

Представьте, что вы выбираете служебный автомобиль для команды. Один дилер говорит: «Наша машина самая быстрая». Другой: «У нас лучший расход топлива». Третий: «Мы лидируем по безопасности». Все они правы – но каждый меряет своё. Без понимания того, что именно и как измеряется, вы не можете сравнить предложения объективно.
С языковыми моделями по состоянию на февраль 2026 года ситуация ещё сложнее. GPT-5.3, Claude 4.6, Gemini 3, Perplexity, DeepSeek V4 – каждая из компаний заявляет о лидерстве. Но как менеджеру понять, чем конкретно один инструмент лучше другого для бизнес-задачи?
Именно здесь начинаются бенчмарки – стандартизированные тесты. К 2026 году старые тесты (вроде MMLU) стали менее полезными, так как все топ-модели научились проходить их почти идеально. Разберём, на какие показатели действительно стоит смотреть сегодня.
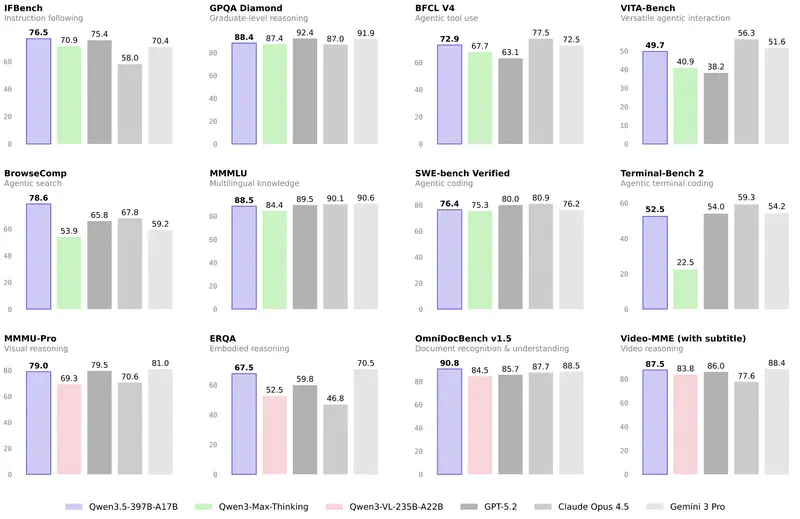
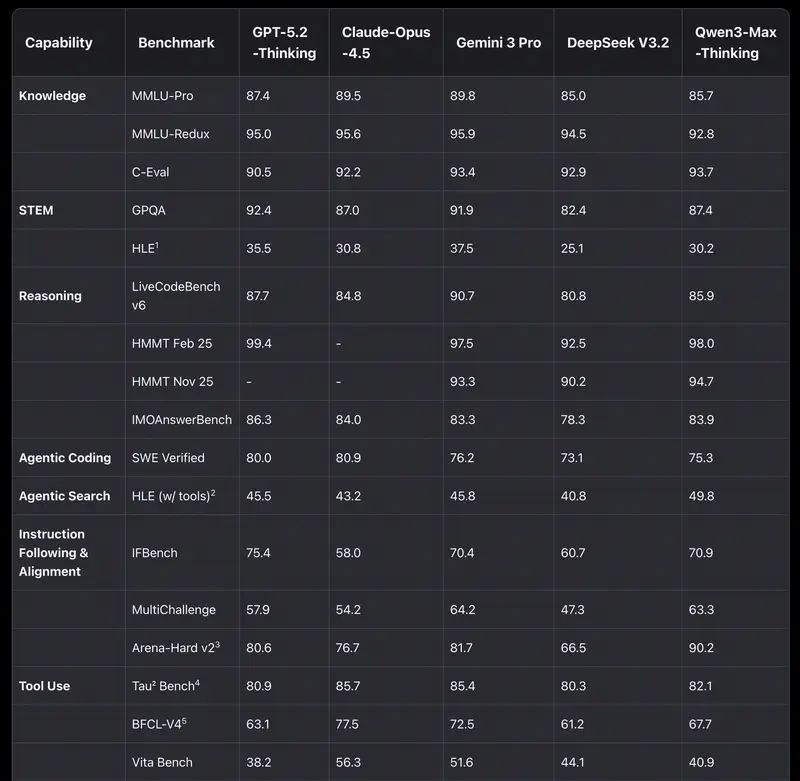
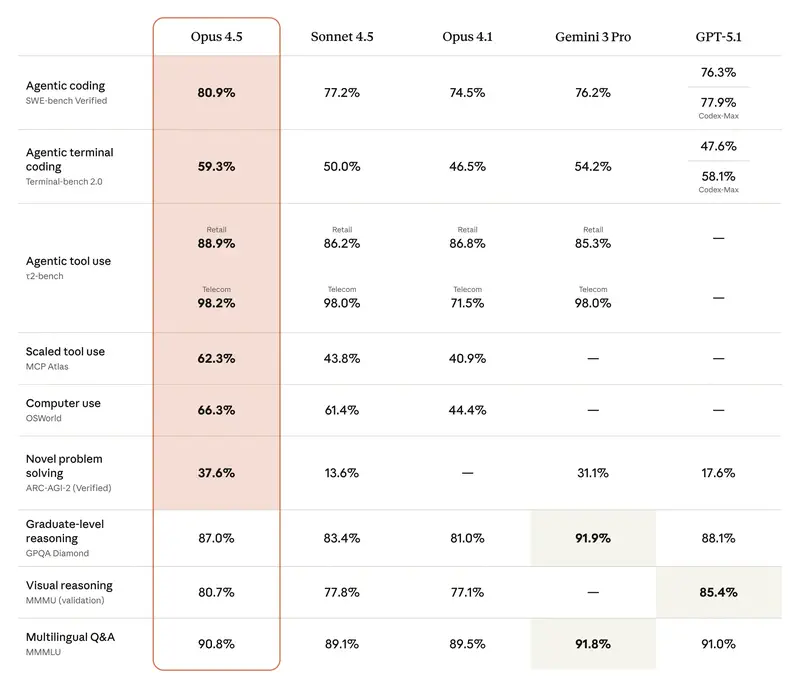
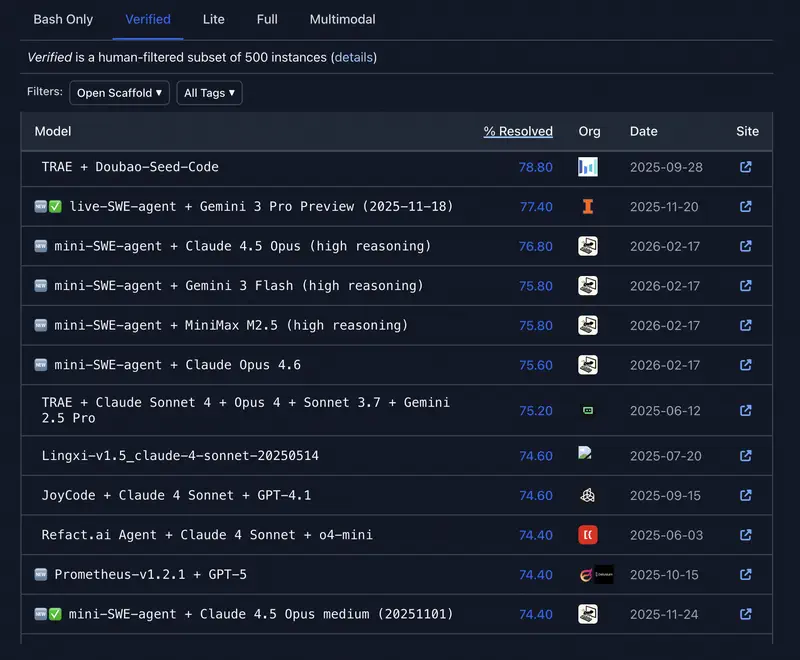
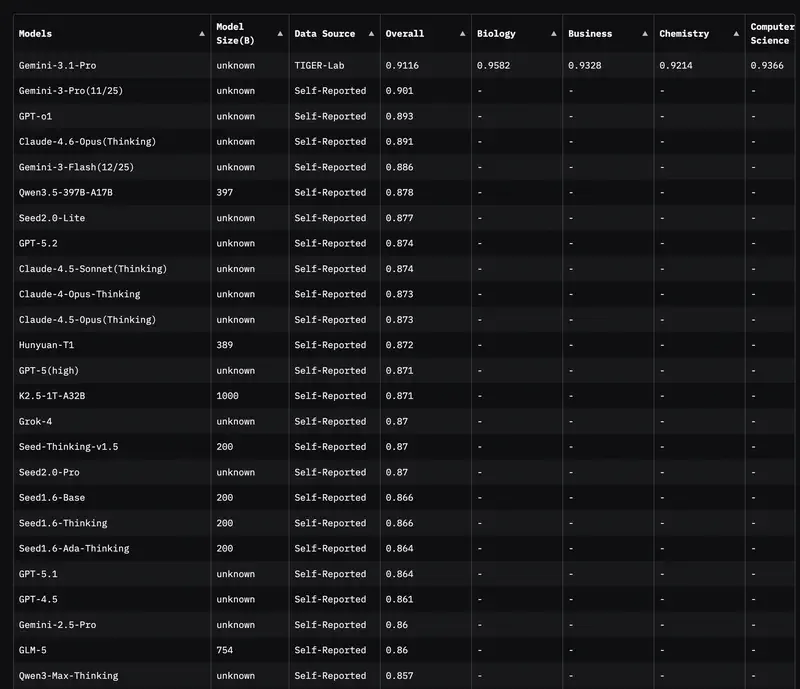
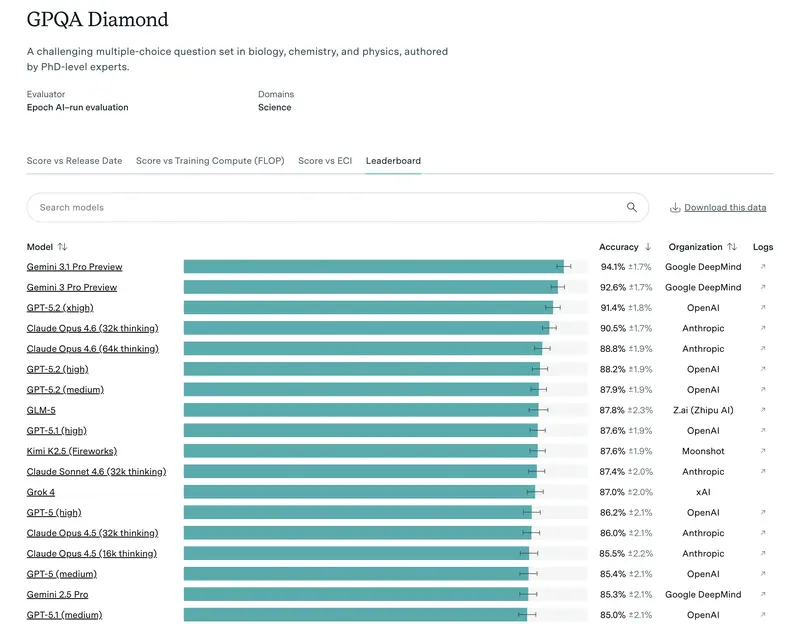
Интуиция против данных. У руководителей часто есть «любимая» модель. Но интуиция обманывает в пограничных случаях. Когда нужно обосновать бюджет или подобрать модель под автоматизацию целого департамента – нужны объективные критерии.
Основные виды оценок 2026
Современная оценка LLM – это не одна цифра, а понимание того, в какой «лиге» играет модель.

Сводная таблица актуальных категорий
| Категория | Ключевой бенчмарк | Что он значит для менеджера |
|---|---|---|
| Экспертные знания | GPQA Diamond | Насколько модель компетентна в вопросах уровня доктора наук (PhD). Важно для аудита и стратегии. |
| Автономная работа | SWE-bench Verified | Способность модели самостоятельно решать задачи в коде и репозиториях. Показатель «агентности». |
| Длинный контекст | RULER / Needle In A Haystack | Не «теряет» ли модель информацию в документе на 1000+ страниц. |
| Глубокая логика | FrontierMath / AIME | Способность к многошаговым рассуждениям без логических провалов. |
| Народный рейтинг | Chatbot Arena (LMSYS) | Как модель оценивают живые люди в анонимном слепом тесте. |
1. Академическая «начитанность» (MMLU и GPQA Diamond)
Раньше все смотрели на MMLU (тесты по 57 дисциплинам). Но в 2026 году этот тест стал «базовым гигиеническим минимумом». Если модель набирает меньше 85–90%, она просто не относится к топовым.
Сегодня золотой стандарт – GPQA Diamond. Это вопросы, которые настолько сложны, что даже эксперты-люди с доступом в интернет ошибаются в них в 60% случаев. Если модель показывает здесь 75%+, это означает, что вы можете доверять ей проверку сложнейших юридических или финансовых документов.
2. Агентская эффективность (SWE-bench и GAIA)
Для менеджера это самый важный показатель в 2026 году. Он измеряет не «красоту речи», а способность выполнить работу.
- SWE-bench Verified – показывает, сколько реальных багов в софте модель смогла найти и исправить сама.
- GAIA – тестирует модель на выполнение задач, требующих использования браузера, поиска файлов и работы с инструментами.
3. Пользовательские оценки: Chatbot Arena
Самый авторитетный «народный» рейтинг. На платформе lmarena.ai люди вслепую сравнивают ответы моделей.
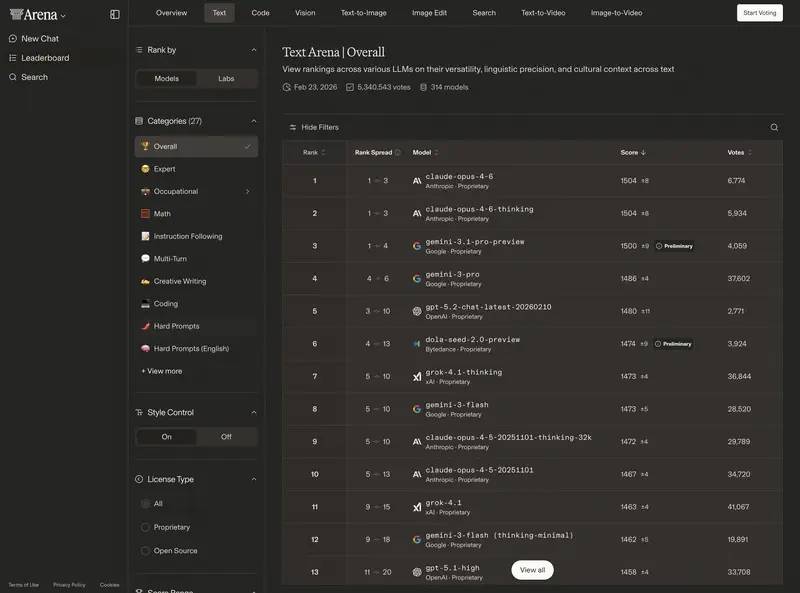
ELO-рейтинг 2026 (ориентиры):
- 1400–1500+: модели «сверхразума» (GPT-5.3, Claude 4.6 Opus, Gemini 3 Ultra).
- 1300–1400: отличные рабочие лошадки (GPT-5-mini, Sonnet 4.6, DeepSeek V4).
- Ниже 1200: устаревшие или специализированные модели.
Разница в 30–50 пунктов ELO практически незаметна в ежедневной переписке. Разница в 100+ пунктов означает качественный скачок в интеллекте и понимании инструкций.
4. Длинный контекст: RULER и проблема «потерянной середины»
Модели 2026 года заявляют о контекстных окнах в 1–2 миллиона токенов. Но размер окна ≠ качество работы с ним. Бенчмарк RULER и тест Needle In A Haystack проверяют, способна ли модель найти и корректно использовать информацию, спрятанную в разных частях длинного документа.
Оба теста к 2026 году стали скорее базовым минимумом. Топовые модели научились находить отдельные факты в длинном тексте. Но исследования 2025 года показали, что большое контекстное окно не гарантирует надёжного рассуждения – модель может найти нужный фрагмент изолированно, но ошибается, когда его нужно интегрировать со сложным окружающим контекстом. Поэтому новые тесты (RULERv2, Sequential-NIAH, MMNeedle) проверяют уже не простой поиск, а многошаговую агрегацию информации из разных частей документа.
Главная ловушка называется Lost in the Middle – модели уверенно работают с началом и концом документа, но «галлюцинируют» или пропускают факты из середины. Это критично, если вы загружаете в модель контракт на 200 страниц или годовой отчёт.
Практический совет: Загрузив длинный документ, задайте модели вопрос именно по информации из середины текста. Если ответ неточный или выдуманный – модель не справляется с вашим объёмом данных. Подробнее о том, как размер промпта влияет на качество ответа, читайте в статье «Промпты 2026: почему AI теряет 30% данных в середине».
Оценка моделей «глубокого мышления» (Reasoning)
С появлением моделей серии o3 (OpenAI), R2 (DeepSeek) и Opus Thinking (Anthropic) возникла новая проблема оценки. Эти модели могут «думать» над ответом от 10 секунд до 5 минут.
Как менеджеру оценивать их качество?
- Точность на выходе – если задача стратегическая (например, расчёт рисков слияния), время ожидания не имеет значения – важна только безошибочность.
- Прозрачность (CoT) – хорошая модель рассуждения должна показывать пошаговый процесс (Chain-of-Thought). Это позволяет вам провести аудит её логики.
Практический совет: как выбрать модель
Выбор LLM для бизнеса в 2026 году строится по трёхшаговому алгоритму.
Шаг 1 – Определите роль
Что будет делать ИИ 80% времени?
| Роль | Главная метрика |
|---|---|
| Стратег / Аналитик | GPQA Diamond, FrontierMath |
| Цифровой сотрудник (Агент) | SWE-bench, GAIA |
| Коммуникатор (Письма, чаты) | Chatbot Arena ELO (Overall) |
| Аудитор документов | Long Context Benchmarks (RULER) |
Шаг 2 – Сверьтесь с бенчмарками
Найдите 2–3 лидера в выбранной категории. Не смотрите на рекламные графики вендоров (они всегда выбирают тесты, где они первые) – используйте независимые ресурсы:
- LMSYS Chatbot Arena – для общей оценки «человечности» и качества диалога.
- Vectara Hallucination Leaderboard 2026 – если вам критически важна фактическая точность.
- MERA (Multimodal Evaluation for Russian-language Architectures) – для проверки качества работы именно на русском языке.
- LiveCodeBench / SWE-bench Verified – если вы подбираете ИИ-программиста или агента.
Шаг 3 – «Тест-драйв» на своих данных
Возьмите 5 самых сложных реальных кейсов из вашей работы за последнюю неделю. Прогоните их через выбранные модели. Оценивайте не «красивость», а точность выводов и полноту выполнения инструкций.
Ловушка «Обучения на экзамене». В 2026 году распространена практика «дата-контаминации» – когда модели обучают специально под вопросы популярных бенчмарков. Поэтому ваши собственные секретные данные – лучший и единственный честный бенчмарк.
Офлайн-задание: зайдите на Chatbot Arena, выберите категорию «Hard Prompts» и посмотрите топ-3 модели. Это и есть ваши главные кандидаты для решения самых сложных рабочих задач в этом квартале.
Полезные ссылки
- LMSYS Chatbot Arena
- GPQA Diamond
- SWE-bench Verified
- GAIA Benchmark
- Vectara Hallucination Leaderboard
- MERA – оценка на русском языке
- RULER (длинный контекст)
- Промпты 2026: почему AI теряет 30% данных в середине
Эта статья – часть серии «Обзор GenAI инструментов 2026». Все инструменты рассматриваются с практическими упражнениями в курсе mysummit.school.








