KazLLM и суверенный AI: гид для госслужащего Казахстана
11 февраля 2026 года на заседании правительства президент Токаев публично раскритиковал KazLLM. Модель, запущенную с большой помпой в декабре 2024-го, используют лишь 600 тысяч человек – 3% населения страны. Для сравнения: ChatGPT в Казахстане пользуются 2,6 миллиона человек. Президент был прямолинеен: KazLLM «не может конкурировать с ChatGPT».
Это заявление ставит вопрос ребром. Зачем Казахстану собственная языковая модель, если глобальные решения работают лучше? И если суверенный AI необходим – почему он проигрывает?
Ответ сложнее, чем кажется. Потому что KazLLM – это не «казахский ChatGPT». Это совершенно другой инструмент с другой задачей. И сравнивать их – всё равно что сравнивать национальную электростанцию с импортным бытовым прибором.
Зачем стране собственная языковая модель
Когда государственный чиновник обрабатывает обращения граждан через ChatGPT, происходят три вещи одновременно. Персональные данные граждан уходят на серверы OpenAI в США. Контекст казахского языка – агглютинативная морфология, code-switching между казахским и русским – интерпретируется с потерями. И государство не контролирует ни доступность сервиса, ни его стоимость, ни политику обработки данных.
Это не теоретический риск. Когда Италия заблокировала ChatGPT в 2023 году из-за нарушений GDPR, государственные процессы, зависящие от него, остановились. Когда OpenAI вводит ограничения для определённых регионов – последствия непредсказуемы. Вопрос ответственности за решения, принятые с помощью AI, выходит далеко за рамки технологий.
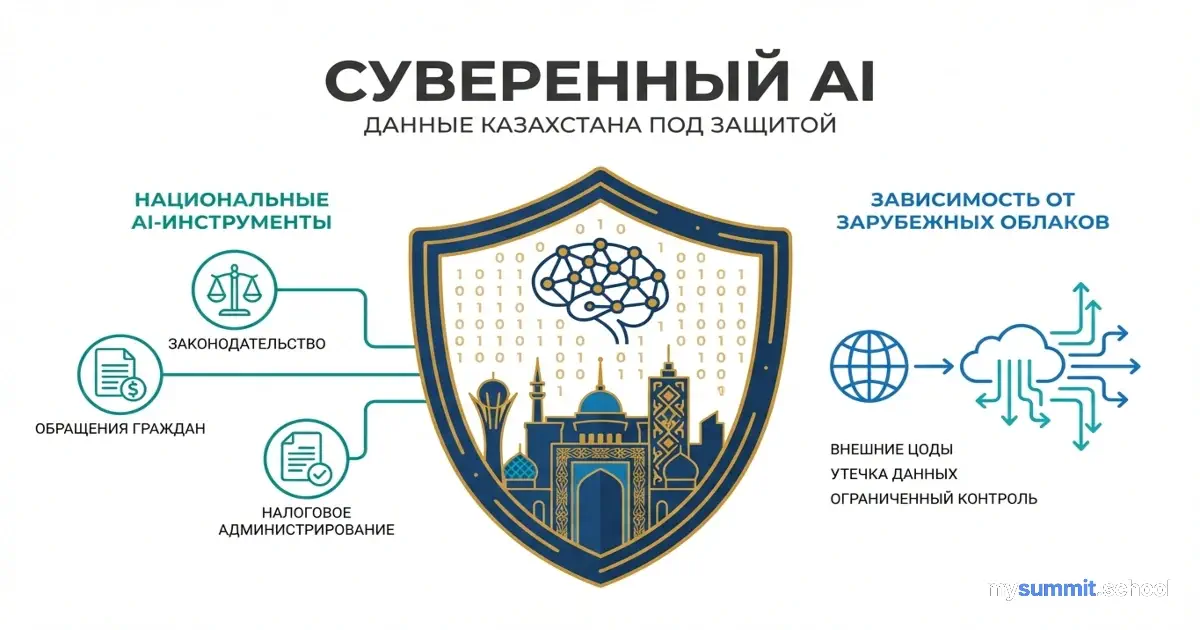
Суверенная модель решает эту проблему архитектурно. Данные не покидают национальную инфраструктуру. Модель обучена на казахском языке с учётом региональных диалектов. И государство контролирует каждый элемент стека – от вычислительных мощностей до алгоритмов.
Казахстан в этом не одинок. ОАЭ построили Falcon, Япония – Fugaku-LLM, Тайвань – TAIDE, Сингапур – SEA-LION. Каждая из этих стран пришла к тому же выводу: зависимость от чужих моделей – стратегическая уязвимость.
Что такое KazLLM на самом деле
KazLLM – официально ISSAI KAZ-LLM – разработан Институтом умных систем и искусственного интеллекта (ISSAI) при Назарбаев Университете совместно с QazCode (подразделение VEON/Beeline Kazakhstan). Международную поддержку обеспечивали Барселонский суперкомпьютерный центр и GSMA Foundry. В марте 2025 года модель получила GSMA Foundry Excellence Award и была представлена на Mobile World Congress в Барселоне.
Удивительно, но при таком международном признании – 600 тысяч пользователей против 2,6 миллиона у ChatGPT. Награда впечатляет, а цифры говорят о другом.
Технически модель построена на архитектуре Meta Llama 3.1 – проверенном open-source фреймворке. Команда не строила архитектуру с нуля, а адаптировала существующую, переобучив нейронные веса для приоритета казахского языка. Доступны две версии: компактная 8-миллиардная для быстрых задач и полная 70-миллиардная для сложного анализа. Обе модели открыто опубликованы на Hugging Face – их можно скачать, протестировать и развернуть на собственной инфраструктуре.
Ключевое преимущество – данные. Специальная команда «Token Factory» при ISSAI на протяжении девяти месяцев собирала и курировала обучающий корпус из более чем 150 миллиардов токенов. Источники – казахские веб-ресурсы, государственные архивы, академическая литература. Модель обучена на четырёх языках – казахском, русском, английском и турецком – с поддержкой code-switching, когда человек переключается между языками в одном предложении. Именно это отличает KazLLM от глобальных моделей: глубокое понимание мультиязычной реальности региона.
Почему тогда сравнение с ChatGPT некорректно? Председатель правления Казахтелекома Багдат Мусин сформулировал это через аналогию: фундаментальная языковая модель – это национальная электростанция. Она вырабатывает «интеллектуальную энергию». А ChatGPT и подобные сервисы – это бытовые приборы: полезные, удобные, но работающие от чужой розетки.
Сам ISSAI опубликовал подробный разбор ситуации после критики Токаева. Масштаб ресурсов говорит сам за себя: для создания Llama Meta задействовала более 16 000 узлов NVIDIA DGX H100 и свыше 400 исследователей. Команда ISSAI работала на 8 узлах DGX H100, предоставленных частной телеком-компанией.
При этом институт признаёт: «ИИ – это гонка. Новые модели появляются примерно каждые шесть месяцев, и KazLLM необходимо развивать дальше». Однако после передачи модели в Astana Hub в декабре 2024 года ISSAI «не просили продолжать её разработку». Модель осталась без обновлений, пока конкуренты выпускали новые версии каждый квартал.
Alem LLM и суперкомпьютер Alem.Cloud
Параллельно с KazLLM государство развернуло инфраструктурный проект другого масштаба. Alem.Cloud – национальный суперкомпьютер и самый мощный вычислительный кластер в Центральной Азии. Его характеристики: 2 экзафлопа производительности (FP8), 512 GPU NVIDIA H200.
Получение этих чипов само по себе было геополитическим маневром – потребовались переговоры с США для получения экспортных лицензий на фоне глобальных ограничений на поставки продвинутых GPU.
Alem LLM – вторая суверенная модель, работающая на этой инфраструктуре. Как и KazLLM, она мультиязычна (казахский, русский, английский, турецкий) и предназначена для государственных сервисов. Ключевое отличие – глубокая интеграция с национальным вычислительным ресурсом: данные обрабатываются на территории Казахстана, на государственном оборудовании.
На этой инфраструктуре строится Национальная платформа искусственного интеллекта – защищённая среда, где государственные разработчики и партнёрские вузы получают доступ к вычислительным мощностям, очищенным датасетам и предобученным моделям. На форуме в Давосе в январе 2026 года были анонсированы партнёрства с NVIDIA, OpenAI и Scale AI – по направлениям суперкомпьютинга, образовательной инфраструктуры и подготовки данных с помощью RLHF.
AI-агенты для госуправления: планы vs реальность
Абстрактные модели приобретают ценность, когда превращаются в конкретные инструменты. Казахстан анонсировал развёртывание более десяти специализированных AI-агентов для государственных процессов. Но важно различать планы и реальность.
Что уже работает:
- AI Therapist – единственный агент с подтверждённым пилотом. Запущен в 30 клиниках Акмолинской области. Анализирует разговоры врача и пациента в реальном времени, выдаёт предварительные диагнозы с точностью до 80% и сокращает время на документацию до 40%. Планируется масштабирование на все медучреждения страны.
Что анонсировано, но пока в разработке:
- AlemGPT / eGov AI – AI-ассистент для портала госуслуг. Министерство цифрового развития тестирует прототип. К концу 2026 года планируется запуск 50 AI-агентов для обслуживания ~7 миллионов пользователей.
- Tax Helper – виртуальный налоговый консультант. Анонсирован как часть цифровизации налоговой системы, но пока без данных о запуске.
- QQazaq Law – юридический ассистент для проверки муниципальных актов на соответствие законодательству. Упоминается в стратегических документах, но подтверждений реального развёртывания нет.
- e-Otinish AI – система обработки петиций и обращений граждан. Описана в концептуальных материалах, данных о запуске не найдено.
Это заставляет задуматься. Разрыв между анонсами и реальным внедрением – ещё одна грань той проблемы, о которой говорил Токаев. Инфраструктура строится, но путь от модели до работающего продукта в руках госслужащего оказывается длиннее, чем планировалось.
Агенты бесполезны без качественных данных. Платформа Smart Data Ukimet решает эту задачу – к середине 2025 года она объединяла 124 государственные информационные системы, поддерживала 80 аналитических кейсов и обслуживала более 8 500 госслужащих. Для руководителя департамента это означает переход от реактивного к предиктивному управлению – прогнозирование инфраструктурных сбоев и распределение ресурсов на основе алгоритмических инсайтов вместо реактивного тушения пожаров.
Мультимодальные инструменты: за пределами текста
Экосистема суверенного AI Казахстана выходит за рамки текстовых моделей. ISSAI разработал линейку мультимодальных инструментов – все доступны как демо на сайте института:
Oylan – мультимодальная модель (язык + аудио + видео). Потенциально применима для мониторинга СМИ, анализа видеозаписей и транскрибирования государственных архивов. Модель закрыта – в отличие от KazLLM, Oylan не опубликован на Hugging Face, а его архитектура, по словам поддержки ISSAI, «конфиденциальна».
Любопытная деталь: пользователи в Telegram-сообществе обнаружили, что Oylan идентифицирует себя как Qwen от Alibaba Cloud. Поддержка ISSAI назвала это «широко известным явлением в LLM» – но вопрос о реальной базе модели остался без прямого ответа. По косвенным признакам – мультимодальность (текст + изображения + видео) и совпадение версий – базой, вероятнее всего, служит Qwen2.5-VL или более поздний вариант из семейства Qwen.
Это подтверждается и академической публикацией: в исследовательской статье команды ISSAI модель Qolda описана как построенная на Qwen3-4B, интегрированной в архитектуру InternVL3.5 – семейство Qwen явно является базовым для мультимодальных проектов института. При тестировании были обнаружены и фактические ошибки – модель путала авторство произведений Абая и использовала устаревшие геополитические данные.
MangiSoz – движок распознавания и синтеза речи с переводом. Задуман как инструмент для дипломатической переписки и межведомственной коммуникации в многоязычных регионах. И снова знакомая история: при тестировании модель перевода раскрыла свою идентичность – Google Gemma. Это не просто косвенный признак: на официальном сайте ISSAI (май 2025) прямо указано, что институт «изучает потенциальное сотрудничество с Google по дообучению модели Gemma для казахского языка». Таким образом, в основе MangiSoz лежит open-source модель от Google, дообученная для казахского языка.
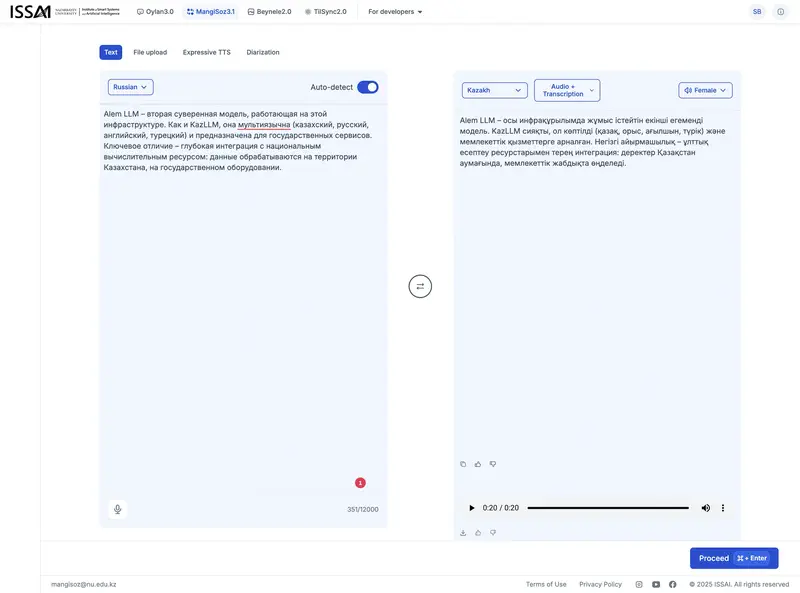
Для примера мы перевели фрагмент этой статьи с русского на казахский и озвучили результат – мужским и женским голосом:
Мужской голос MangiSoz
Женский голос MangiSoz
Демо MangiSoz с переводом между несколькими языками:
В сообществе видно реальный спрос на MangiSoz: пользователи запрашивают API-доступ и возможность развёртывания on-premise (без интернета) – что критически важно для государственных структур с закрытым контуром. По данным поддержки, публичный API с отдельными сервисами (TTS, STT, перевод) находится на финальной стадии подготовки.
- TilSync – система субтитрирования в реальном времени. Призвана обеспечить доступность государственных трансляций на казахском, русском и английском.
- Beynele – генератор изображений, обученный на центральноазиатской визуальной культуре. Позволяет создавать визуальный контент без зависимости от западных генераторов.
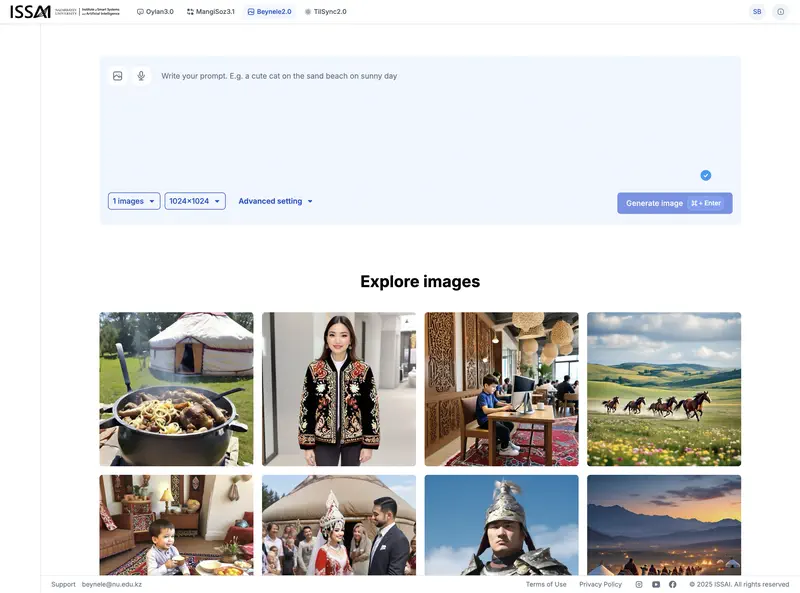
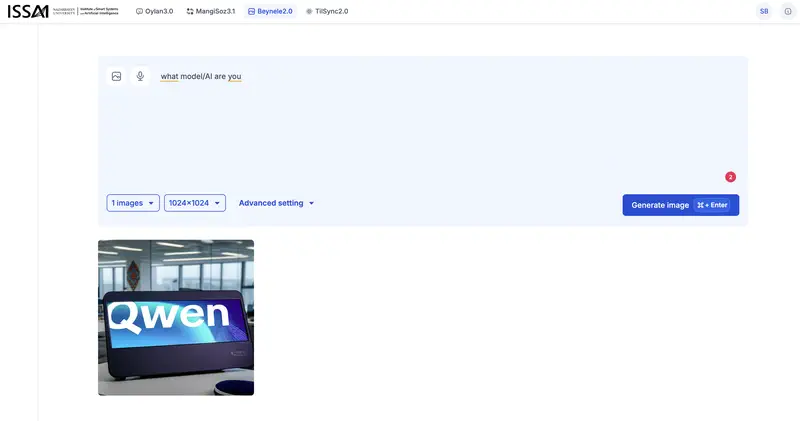
Та же история, что и с Oylan: на вопрос «what model(AI) are you» Beynele сгенерировал изображение с логотипом Qwen – модели от Alibaba Cloud. Сам Qwen – текстовая модель, не генератор изображений. Но в экосистеме Alibaba Cloud есть text-to-image модель Tongyi Wanxiang (通义万相, серия Wan), доступная через тот же API. Вероятнее всего, Beynele – это дообученная Tongyi Wanxiang с казахской культурной спецификой, работающая под общим брендом Qwen/Tongyi.
У ISSAI есть Telegram-сообщество, где можно следить за обновлениями и задавать вопросы разработчикам.
Важная оговорка: все четыре инструмента находятся на стадии исследовательских демо. Независимых обзоров или сравнений с аналогами (Google Translate, Whisper, Midjourney) на момент написания статьи не обнаружено. В Telegram-сообществе пользователи сообщают о технических проблемах – нулевые токены на новых аккаунтах, нестабильная работа API. Поддержка реагирует, но это характерные признаки ранней стадии продукта. Для госслужащего, планирующего внедрение, это означает: протестировать стоит, но рассчитывать на промышленную эксплуатацию пока рано.
Закон об искусственном интеллекте: рамки для всех
18 января 2026 года вступил в силу Закон Республики Казахстан об искусственном интеллекте (N 230-VIII) – первый комплексный закон об AI в Центральной Азии. Подписан 17 ноября 2025 года, он разработан при координации 13 государственных органов с участием социологов, философов и юристов.
Ключевые положения закона:
- Система классификации AI-систем по уровню риска (аналогично EU AI Act).
- Требования к прозрачности использования AI в государственных решениях.
- AI-сгенерированные произведения защищаются авторским правом только при наличии творческого вклада человека (промптинг, редактирование). Предусмотрено право на отказ от использования данных для обучения.
- Явные запреты на использование AI для психологической манипуляции граждан.
Для госслужащих это означает: любое ведомственное внедрение AI должно проходить регулярный аудит на соответствие этическим стандартам и правам граждан.
Проблема номер один: разрыв компетенций
Инфраструктура есть. Модели есть. Закон есть. AI-агенты развёрнуты. Но критика Токаева указывает на главную проблему – разрыв между технологией и её использованием.
600 тысяч пользователей KazLLM против 2,6 миллиона пользователей ChatGPT – это не приговор качеству модели. Это индикатор того, что люди не знают, зачем и как использовать суверенные инструменты. Модель, которая не понимается и не применяется, бесполезна – какой бы мощной она ни была. Это не казахстанская специфика – аналогичный разрыв зафиксирован по всему миру.
Программа AI Qyzmet – обязательная сертификация госслужащих в области AI – призвана закрыть этот разрыв. Программа AI Sana нацелена на обучение 650 000 студентов. Центр Alem.ai в Астане к 2029 году планирует выпускать 10 000 AI-специалистов ежегодно.
Но масштаб вызова огромен. Образовательные программы только начинают развёртываться, а госслужащие уже сегодня работают с ChatGPT – используя его для задач, в которых суверенные инструменты были бы безопаснее и точнее. Исследования подтверждают: без системного обучения технология не приживается.
Это заставляет задуматься: государство инвестирует миллиарды в технологию, которая простаивает, потому что пользователи не обучены с ней работать.
Что это значит для госслужащего
Мы протестировали Oylan, MangiSoz и Beynele – и увидели знакомую картину. Модели работают, но с оговорками. Oylan путал авторство произведений Абая и называл Байдена действующим президентом США в конце 2025 года. MangiSoz выдаёт приемлемый перевод, но за фасадом – Google Gemma. Как показывают исследования Anthropic, AI-системы ошибаются не последовательно, а хаотично – и это касается любой модели, суверенной или глобальной.
Суверенный AI – уже не будущее. Платформа, модели и агенты существуют. Вопрос не в том, будет ли ваше ведомство использовать AI, а в том, будете ли вы управлять этим процессом – или он будет происходить стихийно, через личные ChatGPT-аккаунты сотрудников. При этом глобальные модели не исчезнут: ChatGPT, Claude, Gemini остаются мощными инструментами для задач, не связанных с персональными данными граждан.
Исследования показывают, что AI не сокращает работу, а интенсифицирует её – создавая новые требования к навыкам. Когда AI Qyzmet станет обязательным, госслужащие с практическими навыками окажутся в позиции лидеров.
Главный вызов суверенного AI Казахстана – не технологический. Государство построило инфраструктуру мирового уровня и пока не смогло убедить собственных чиновников ею пользоваться. 16 000 узлов DGX H100 у Meta, 8 узлов у ISSAI, ноль обновлений после передачи модели – и президент, который спрашивает, почему это не работает как ChatGPT. Может быть, вопрос стоит ставить иначе: не «почему KazLLM хуже ChatGPT», а «кто именно должен был заниматься её развитием после декабря 2024 года»?
Суверенный AI внедряют. Кто умеет с ним работать – будет впереди
Курс по генеративному AI для госслужащих и менеджеров: ChatGPT, Claude, промптинг, критическая оценка – практика без регистрации.
Источники
Все ссылки и данные актуальны по состоянию на февраль 2026 года. Экосистема суверенного AI Казахстана активно развивается – рекомендуем проверять актуальность информации.