Списывание через ИИ: чему учит опыт китайских вузов
В 2022 году китайские студенты покупали доступ к зеркалам ChatGPT на сомнительных площадках – официального доступа к зарубежным ИИ-сервисам в Китае не было. В 2026 году знание ИИ по новому плану Минобразования закрепили как обязательный компонент квалификационного экзамена для учителей. Между этими двумя точками – четыре года и полный разворот в том, как самая большая система образования в мире смотрит на списывание.
Свежий отчёт о состоянии ИИ в китайском образовании (2024–2026) показывает страну, которая попробовала запрет, увидела, что он не работает, и выстроила куда более прагматичную систему. Именно эта система интереснее всего преподавателю в СНГ, который прямо сейчас держит в руках курсовую, написанную явно не студентом.
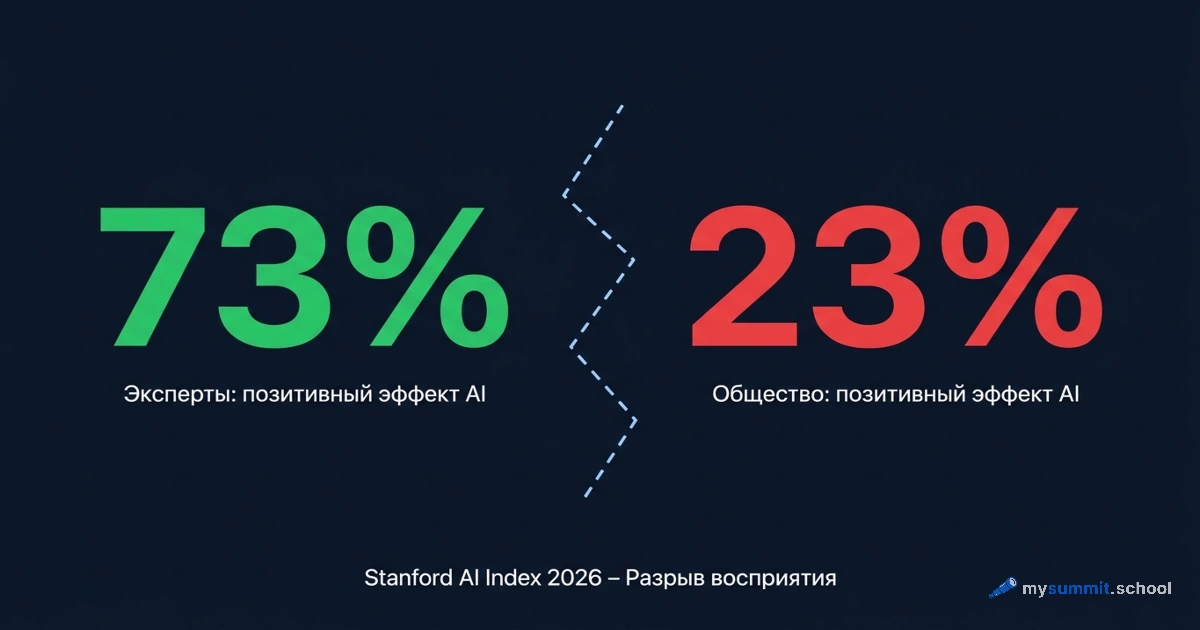
Сразу оговорю рамку. Это не официальный документ Минобразования КНР, а собранная с помощью ИИ сводка по открытым источникам, причём с китайской оптикой, – относиться к ней стоит со здоровой долей скепсиса. Первоисточники, где они названы (Nature, Heliyon, опросы MyCOS), я привожу отдельно. Цифры там бодрые: 88,52% студентов-инженеров сообщают о росте эффективности учёбы (опрос в Nature Scientific Reports), а 2,97 млн учителей прошли подготовку по ИИ-грамотности (в самой сводке та же цифра местами раздута до невозможных «297 млн» – учителей в КНР около 18 млн, так что лишний повод перепроверять). Но тот же отчёт честно фиксирует и обратную сторону: 30% студентов используют ИИ в первую очередь для написания работ, 63% школьников сталкивались со спам-звонками из-за утечек учебных данных, а почти 18% признались, что ИИ ослабил их способность думать самостоятельно. По данным Stanford AI Index 2026, похожий разрыв фиксируется глобально: 80% студентов используют ИИ, а только 6% преподавателей понимают, какие правила при этом должны действовать. Здесь нас интересует то, что работает на практике, – и особенно та часть, где Китай разбирается со списыванием.
Главный урок: запрет не работает, и Китай это проверил на себе
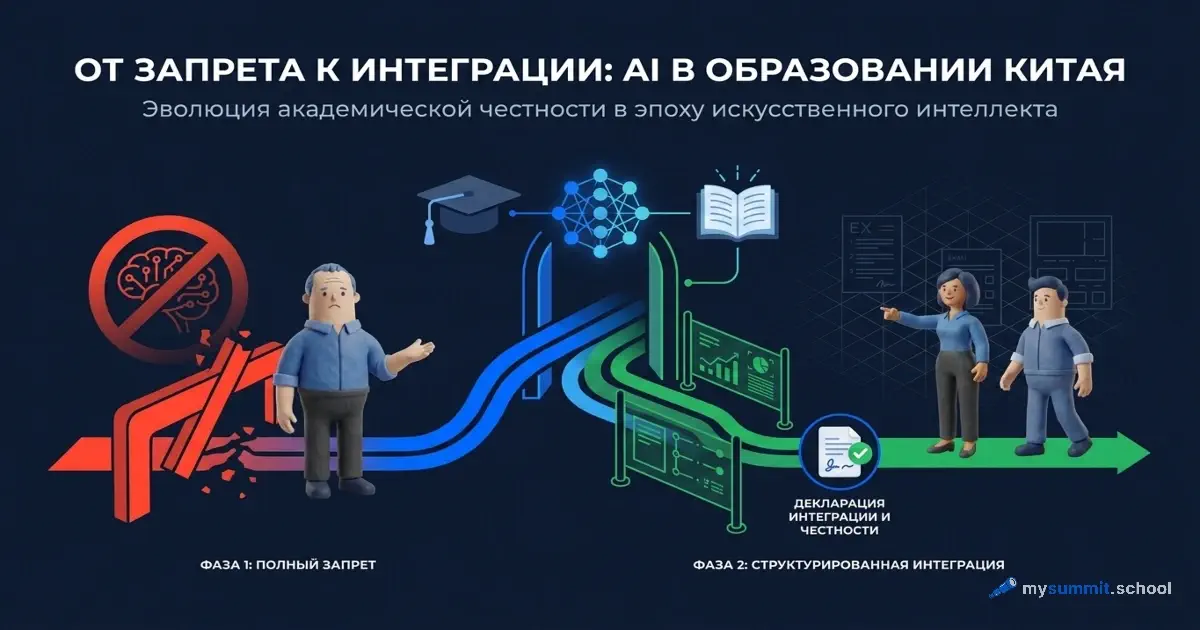
Начнём с вывода, который отчёт делает почти прямым текстом. Когда ChatGPT появился в конце 2022 года, китайские вузы пошли по интуитивному пути – запретить. Доступ блокировали, использование осуждали. Один студент-юрист вспоминает, как «покупал доступ к зеркалу ChatGPT через тёмную онлайн-площадку, чтобы обойти общенациональный запрет». Знакомая логика: инструмент опасен для честности – значит, перекрыть.
Запрет продержался недолго и развалился сам. К 2024–2025 годам опрос института MyCOS показал, что почти 60% преподавателей и студентов китайских вузов пользуются генеративным ИИ ежедневно или еженедельно, и лишь 1% не трогают его вообще. Когда инструментом пользуются почти все, запрет превращается в фикцию: он не останавливает списывание, а просто загоняет его в тень и наказывает тех, кто честно признался.
Вот первый и самый неудобный урок для преподавателя. Политика «ИИ в работах запрещён» в 2026 году создаёт ровно ту ситуацию, которой вы боитесь: студент всё равно использует модель, но теперь скрывает это, а вы тратите силы на игру в детектив вместо обучения. Это не специфика студентов – то же происходит и в командах: 57% сотрудников скрывают использование ИИ, когда культура организации это не принимает. Китай прошёл эту стадию и от неё отказался. Стоит ли проходить её заново.
Что Китай построил вместо запрета: четыре опоры
Отказавшись от запрета, китайские вузы не скатились в анархию «пользуйтесь чем хотите». Они выстроили систему из четырёх частей, и каждую из них можно разобрать и примерить на свою практику. Сразу честно: примеры ниже – это практики ведущих вузов вроде Фудани и Цинхуа, а не усреднённой китайской школы. Но сами механизмы не требуют их ресурсов и переносятся на любой курс.
Первый элемент – чёткие границы вместо размытого «нельзя». Университет Фудань ввёл подход, который называют «красные линии и зелёные коридоры» (红线与绿道). Красные линии – то, где ИИ запрещён прямо: дизайн исследования и анализ данных, сбор первичных данных, создание ключевых иллюстраций, написание и защита диплома, работа с закрытой информацией. Зелёные коридоры – то, где он разрешён открыто: поиск литературы, помощь с кодом, статистический анализ – с одобрения преподавателя. Студент заранее знает, где граница, а не угадывает её постфактум.
Второй – количественные лимиты. Здесь китайцы сделали ход, до которого в дискуссиях обычно не доходят. Тяньцзиньский университет науки и технологий ограничил долю сгенерированного ИИ контента в дипломе планкой в 40%. Восточно-китайский педагогический университет – 20% в заданиях. Измерить «долю ИИ» точно невозможно, и инструмент несовершенен. Но как норма, задающая ожидание, лимит работает: он легализует помощь модели и одновременно сигналит, что работа целиком из-под ИИ – это уже нарушение.
Третий – обязательное декларирование. Студенты Фудани и Цинхуа подписывают декларацию: использовали ли они ИИ и в каких именно частях работы. Это самый дешёвый и при этом самый недооценённый механизм. Он не ловит нарушителя технически – он меняет рамку. Использование ИИ перестаёт быть тайным грехом и становится тем, о чём положено честно сообщить. А скрытое использование при подписанной декларации – это уже прямой подлог, и относиться к нему можно соответственно.
Четвёртый и главный – переделка заданий. Об этом ниже отдельно, потому что это та опора, которую китайские эксперты называют единственно надёжной.
Прежде чем перейти к практике, честно обозначу разрыв. Прочитать про четыре опоры легко. Сложно – применить их к своему предмету так, чтобы они работали, а не превратились в ещё одну бумажку. Разница между «слышал про декларирование» и «выстроил задание, которое нельзя сдать одним промптом» – это понимание того, что ИИ на самом деле умеет, а где спотыкается. А это понимание берётся только из практики с самим инструментом.
Прежде чем перестраивать задания под ИИ, пройдите 9 реальных задач и сами увидите, где модель сильна, а где уверенно ошибается. Бесплатно, без регистрации.
Доступ сразу после регистрации
Почему детекторы – не спасение, и Китай это признаёт
Соблазн любого преподавателя – найти технический детектор, который скажет «это написал ИИ», и закрыть вопрос. Китай по этому пути пошёл всерьёз и потратил на него ресурсы, которых у отдельной школы или вуза в СНГ просто нет.
В Университете почты и телекоммуникаций Пекина команда профессора Э Хайхун по заказу Министерства науки и технологий построила систему детекции академических нарушений: она сверяет работы с базой из 4 млн научных статей и 60 млн изображений, выискивая в том числе сфабрикованные данные и поддельные иллюстрации. На экзамене гаокао-2026 пошли ещё дальше: платформы Doubao, Tencent Yuanbao и Baidu Wenxin по договорённости отключили функцию ответа по фотографии вопроса на время экзамена. То есть списывание предотвращают в реальном времени, а не ловят постфактум.
И вот вывод, который отчёт фиксирует прямо: китайские эксперты сходятся на том, что технической детекции недостаточно. Детектор ловит грубое копирование, но обходится перефразированием, плохо работает с короткими текстами и регулярно даёт ложные срабатывания – а ложное обвинение честного студента дороже пропущенного списывания. Поэтому даже страна, способная построить базу на 60 млн изображений, не считает детекцию основным рубежом обороны.
Для преподавателя в СНГ это снимает ложную надежду. Не ищите волшебный детектор – его нет даже у тех, кто вложил в него миллионы. Энергию, которую вы потратили бы на ловлю ИИ-текста после сдачи, разумнее вложить туда, где у Китая получилось: в само задание.
Что брать в работу прямо в понедельник
Перейдём от анализа к практике. Вот что из китайского опыта переносится на уровень отдельного преподавателя без бюджета, без приказа сверху и без специального ПО.
Первый шаг – правило декларирования. Это самый дешёвый ход с самым высоким эффектом. Добавьте в требования к любой работе одну строку: «Укажите, использовали ли вы ИИ и в каких частях работы». Речь не о слежке, а о смене нормы – ровно то, что сделали в Фудани и Цинхуа. Студент, который честно написал «использовал ИИ для поиска источников и проверки грамматики», ведёт себя правильно. Студент, который не написал ничего, а работа явно сгенерирована, нарушил конкретное обязательство – не размытое «не злоупотреблять».
Второй – провести границу для своего предмета. Министерский документ для этого не нужен. Сформулируйте для своего курса: где ИИ – помощник (черновик, разбор примера, проверка кода), а где – нарушение (итоговый анализ, выводы, защита). Студенты ценят ясность границы куда выше, чем её строгость: размытое «не злоупотребляйте ИИ» порождает больше нарушений, чем честное «вот здесь можно, вот здесь нет».
Третий и наиболее надёжный – перестроить хотя бы одно задание под то, чего у модели нет. Идея проста: задание, которое решается одним промптом, и должно решаться одним промптом – значит, оно проверяет не того студента. Опирайте работу на то, к чему у модели нет доступа:
- данные и материалы с вашей конкретной пары, которых нет в интернете;
- локальный контекст: ваш город, ваше предприятие, конкретный кейс из вашей практики;
- личный опыт и рефлексию студента, привязанную к процессу, а не к результату;
- устную защиту, где надо объяснить ход рассуждений, а не предъявить готовый текст.
Собрать такое задание с нуля бывает долго, поэтому проще начать с готового каркаса. Наш генератор учебных кейсов собирает кейс под ваш предмет за пару минут – дальше его остаётся привязать к своим данным, локальному контексту и защите вслух, то есть к тому, чего у модели нет.
И четвёртый – сместить проверку с продукта на процесс. Отчёт прямо называет это направлением реформы оценивания в Китае: оценивать не финальный текст, который ИИ напишет за минуту, а критическое мышление, творчество и совместное решение задач – то, что модель пока не подделывает. Промежуточные черновики, обсуждение в группе, защита решения вслух – всё это смещает центр тяжести с того, что легко сгенерировать, на то, что приходится продумать.
Заметьте: ни один из этих шагов не требует поймать студента за руку. Все они меняют саму ситуацию так, что списывание либо теряет смысл, либо становится видимым без детектора.
Чтобы перестроить задание под ИИ, надо самому понимать, где он надёжен, а где врёт. 9 управленческих и учебных кейсов в открытом модуле – проверьте бесплатно, без регистрации.
Доступ сразу после регистрации
Не только про списывание: где ИИ в образовании реально сработал
Было бы нечестно свести весь китайский опыт к обороне от списывания. Отчёт фиксирует и применения, которые стоит знать, – с поправкой на тот же скепсис к цифрам. Схожие паттерны – и пользы, и деградации мышления – зафиксированы не только в Китае: исследование Университета Иллинойса показало, что правильно откалиброванный ИИ-наставник даёт обратный эффект по сравнению с бесконтрольным использованием.
Самое сильное из доказанного – выравнивание разрыва между сельскими и городскими школами. Контролируемый эксперимент в 12 китайских школах (4 городские, 8 сельских), опубликованный в журнале Heliyon, показал, что ИИ-поддержка дала сельским школам прирост результатов на 15,69% против 10,27% в городских. Механизм понятен: там, где не хватает сильных учителей и материалов, персональный ИИ-помощник частично компенсирует дефицит. Это перекликается с более ранней китайской программой дистанционного образования 2004 года, которая, по оценке исследования VoxDev, сократила городско-сельский разрыв в образовании на 21%. Для регионов СНГ с той же проблемой неравного доступа это, пожалуй, самый обнадёживающий сигнал из всего отчёта.
Второе, самое заметное в школьной рутине, – автоматическая проверка работ. Системы автоматической оценки сочинений на базе больших моделей (например, на движке iFlytek Spark) к 2025 году применялись примерно в 30 000 школ: они разбирают текст по нескольким измерениям – тема, структура, язык – и снимают с учителя рутину первичной сверки. Цифры тут стоит делить надвое, но направление честное: машина берёт на себя рутину, а итоговое суждение оставляет человеку. Это ровно тот случай, где ИИ экономит время, не подменяя педагога.
Третье – персонализация. Рандомизированный эксперимент в Университете Цинхуа показал, что студенты с ИИ-наставником ощущали больше контроля над учёбой и выполняли задания эффективнее, причём это ощущение контроля предсказывало и реальный рост результатов на тесте. Но тут же отчёт ставит важную оговорку: при 88,52% (по данным отчёта), заявивших о росте эффективности, почти половина не почувствовала роста собственно успеваемости. Эффективность и обученность – разные вещи. Студент делает задание быстрее, но «немедленное чувство выполненного» может маскировать поверхностное обучение. И это не оговорка, а методологическое противоречие: если «эффективность» растёт, а успеваемость нет, значит, метрика ловит скорость сдачи, а не глубину обучения. ИИ, ускоряющий выполнение, – не то же самое, что ИИ, углубляющий понимание.
И четвёртое, тревожное, – «аутсорсинг мышления» (思维外包). В Цинхуа заметили студентов, которые принимали сгенерированный код и схемы, не вникая в них. Почти 18% китайских студентов-инженеров сами признали, что ИИ ослабил их способность мыслить самостоятельно. Это та же проблема, которую HBR в июне 2026 года назвал thinkslop: результат выглядит профессионально, но за ним нет когнитивной работы автора. Если ИИ берёт на себя думанье, а не рутину, образование проигрывает, даже когда метрики эффективности растут.
Что из этого следует
Главный вывод китайского опыта обманчиво прост. Запрет студенты обходят, детектор ошибается, а энергия преподавателя уходит в песок. Устойчивее работает другое: явные границы, честное декларирование использования и – главное – задания, которые проверяют то, чего у модели нет: ваш контекст, личный опыт студента, способность объяснить ход мысли.
Ни один из этих шагов не про технологии. Все они про педагогику и про одно ключевое умение самого преподавателя – понимать, что ИИ реально делает хорошо, а где уверенно ошибается. Без этого понимания вы не отличите работу студента от работы модели, не проведёте осмысленную красную линию и не построите задание, устойчивое к одному промпту. Китайский отчёт упирается в это снова и снова: технология – не главное, главное – человеческое суждение поверх неё.
С этого и стоит начать: самому сесть за десяток реальных задач с ИИ и увидеть его сильные и слабые места своими глазами – ровно то, что Китай теперь закрепляет требованием к каждому учителю через квалификационный экзамен.
От анализа китайского опыта – к своей практике
Прежде чем перестраивать задания и проводить красные линии, надо самому понимать, где ИИ надёжен, а где врёт. Курс строит именно этот фундамент: реальные задачи, разбор ошибок модели, проверка ответов на фактах. Специализация «Образование» – в разработке, фундамент доступен сейчас.


Часто задаваемые вопросы
Как Китай борется со списыванием через ИИ?
Работают ли детекторы ИИ-текста?
Что преподавателю в СНГ взять из китайского опыта прямо сейчас?
Запрет ИИ в учебных работах – рабочая стратегия?

mysummit.school
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.