Анализ конкурентов с ИИ: где модель выдумывает факты
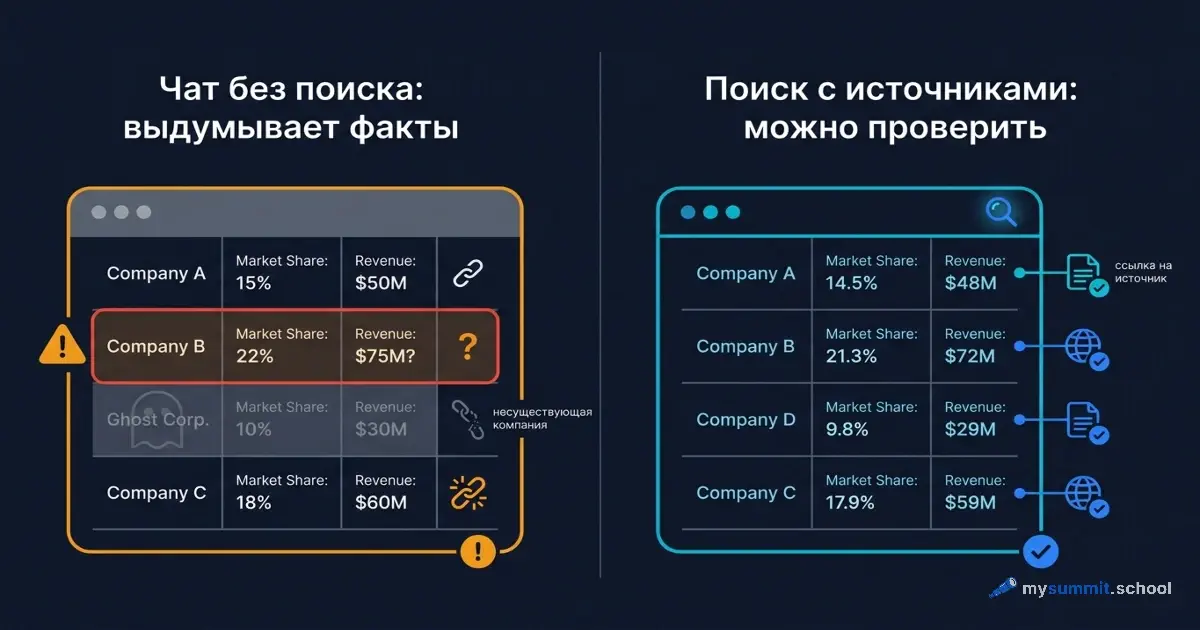
Менеджер по закупкам просит ИИ найти конкурентов, производящих оборудование для одной узкой промышленной установки. Через десять секунд получает аккуратный список: пять компаний, страны, примерные обороты, пара ссылок. Выглядит как работа аналитика за полдня. Проблема в том, что двух из этих компаний не существует, а обороты модель назначила на глаз.
Это реальный тип запроса. В наборе ответов наших студентов на вопрос «какую рабочую задачу вы хотели бы ускорить с помощью ИИ» набралась целая группа про ресёрч: найти магазины машинной пряжи в Европе, проанализировать мировой объём продаж картофеля, собрать кейсы применения ИИ в нефтегазе, провести анализ конкурентов по узкому промышленному оборудованию, систематизировать нормативную базу проекта и подтягивать по ней новости. Общую картину всех 40 запросов мы разобрали в отдельном материале – ресёрч занял там заметное место. Запросы из разных миров, но боль одна – собрать информацию о рынке, которой у тебя пока нет.
И ровно здесь ИИ опаснее всего. Когда он не знает ответа, он его не оставляет пустым. Он его сочиняет – уверенно, складно и в том же тоне, что и правду.
Оговорюсь про границы наблюдения. Сорок ответов студентов – это срез одной мотивированной аудитории, а не репрезентативный опрос рынка. Но запросы из него ценны тем, что это живые формулировки задач от людей, которые завтра пойдут их решать. Все примеры здесь анонимны и обобщены до уровня типа задачи.
Почему ресёрч – худшее место для наивного чат-бота
Стоит разобрать механизм, иначе совет «проверяйте» звучит как пустое предостережение. Языковая модель не хранит факты в виде базы данных, откуда их можно достать. Она генерирует наиболее вероятное продолжение текста. В большинстве задач это и есть то, что нужно: переписать письмо, собрать резюме встречи, структурировать ТЗ. Там исходная информация уже лежит перед моделью, и она просто приводит её в форму.
Ресёрч устроен наоборот. Вы просите модель добыть то, чего в запросе нет: название нишевого поставщика, долю рынка, оборот компании, ссылку на отчёт. Если этого нет в её памяти достаточно надёжно, она не скажет «не знаю». Она достроит правдоподобный ответ из похожих паттернов. Так появляется компания с реалистичным названием, которой нет, и ссылка на исследование, которого никто не публиковал.
В индустрии это называют галлюцинацией. Термин неудачный – он намекает на сбой, на редкую ошибку. Правдоподобная генерация там, где нужна фактическая точность, – это штатный режим работы любой языковой модели, просто проявленный в наихудшем месте. Модель всегда генерирует правдоподобное. В разговоре про мотивацию команды правдоподобное и есть полезное. В анализе конкурентов правдоподобное и ложное выглядят абсолютно одинаково.
Вот что делает ресёрч коварным. Когда ИИ ошибается в арифметике, это часто заметно – цифра не сходится. Когда он выдумывает конкурента, заметить нечего. Список выглядит ровно так, как должен выглядеть результат хорошего исследования. Чтобы поймать выдумку, нужно уже знать рынок – а вы пошли к ИИ именно потому, что не знаете его.
Вернёмся к закупщику и установке замедленного коксования. Допустим, он не проверил список и понёс его дальше – в сравнение поставщиков, в служебную записку, в разговор с руководством. Выдуманная компания с правдоподобным оборотом искажает всю картину: реальный конкурент выпадает из обзора, несуществующий занимает его место. На таком узком B2B-рынке цена одной ложной строки – это неверное решение о закупке на десятки миллионов. И никто не сможет ткнуть пальцем в момент, где всё пошло не так, потому что ошибка была встроена в исходные данные. Это крайний случай более общей проблемы: по данным Workday, 37% времени, сэкономленного с помощью ИИ, в среднем снова теряется на исправление его же ошибок.
Разделить, что отдавать ИИ, а что проверять
Это не значит, что ИИ бесполезен для ресёрча. Он полезен, но не в той части, в какой кажется. Граница проходит между работой со структурой и работой с фактами.
Модели можно спокойно отдать всё, что является структурированием и постановкой вопросов:
- Каркас анализа. По каким осям вообще сравнивать конкурентов в этой нише: цена, сроки поставки, сертификация, сервис, география. Модель быстро соберёт разумный набор критериев, даже если конкретных значений не знает.
- Список вопросов для ресёрча. Что именно нужно выяснить про каждого игрока, чтобы сравнение было честным. Это переводит размытое «изучи конкурентов» в проверяемый чеклист.
- Первый набросок ландшафта. Грубая карта рынка как гипотеза, которую вы дальше проверяете. С пометкой, что это гипотеза, а не факт.
- Переупаковка того, что вы уже нашли. Когда данные собраны и проверены, модель отлично соберёт из них таблицу, резюме или служебную записку.
А вот что нужно проверять всегда, без исключений:
- Конкретные числа. Доли рынка, обороты, объёмы продаж, цены, темпы роста. Любая цифра из ответа ИИ – это гипотеза до тех пор, пока вы не нашли её в первоисточнике.
- Названные компании и люди. Существование организации, её профиль, кто ей руководит. Нишевые B2B-игроки – зона наибольшего риска: их мало, модель знает их хуже всего и охотнее всего достраивает.
- Регуляторные нормы и сроки. Это была отдельная боль в запросах – систематизировать нормативную базу проекта. Модель назовёт номер документа и его суть уверенно и нередко с устаревшими или перепутанными деталями. Цена ошибки здесь – юридическая.
- Ссылки и URL. Самый частый вид выдумки. Модель генерирует ссылку, которая выглядит настоящей, ведёт на правдоподобный домен и не открывается либо открывает совсем не то.
Разрыв между «помогает думать про рынок» и «знает факты о рынке» – та самая ловушка ожиданий. Человек видит, что ИИ бодро рассуждает про отрасль, и делает вывод, что ему можно доверить и факты. Доверять можно рассуждению о методе. Проверять нужно каждое конкретное утверждение.
Прежде чем раздавать ИИ задачи по ресёрчу, полезно самому пройти десяток типовых управленческих ситуаций и увидеть, где он реально ускоряет, а где тихо подсовывает правдоподобную выдумку. Без этого граница между сильным и слабым применением остаётся теоретической.
Посмотрите на 9 реальных задач менеджера и сами увидите, где ИИ ускоряет работу, а где уверенно выдаёт ложный факт. Бесплатно, без регистрации.
Доступ сразу после регистрации
Инструмент решает: чат без поиска против поиска с привязкой
Большая часть провалов в ресёрче – это выбор не того инструмента. Обычный чат-бот без доступа к интернету отвечает из памяти, а память у него вероятностная и без даты. Для исследования рынка это худший вариант: он звучит увереннее всех и при этом сочиняет свободнее всех.
Для задач, где важны свежие и проверяемые факты, нужны инструменты с доступом к поиску. Они работают иначе: сначала ищут в вебе, потом пишут ответ, опираясь на найденные страницы, и привязывают утверждения к ссылкам.
- Perplexity – поисковый движок поверх языковой модели. Каждый тезис помечен сноской на источник, которую можно открыть.
- Режимы с веб-поиском в ChatGPT и Claude – те же привычные модели, но с доступом к актуальной выдаче. Включаются отдельным переключателем или включаются автоматически, когда модель понимает, что нужен свежий факт.
- Функции deep research – режим, в котором модель тратит несколько минут, обходит десятки источников и собирает отчёт со ссылками. Полезно для первичной карты рынка, но и здесь ссылки нужно открывать.
Привязка к источникам не отменяет проверку, она её упрощает. Модель с поиском тоже иногда приписывает источнику то, чего в нём нет, – берёт реальную ссылку и пересказывает её неточно. Но разница принципиальная: у вас есть что открыть и с чем сверить. У наивного чата открывать нечего, потому что источника просто не было.
Для российского контекста есть нюанс. Часть западных инструментов работает с ограничениями по оплате и доступу, российские модели вроде GigaChat и YandexGPT добавляют поиск по-своему. Конкретные возможности и то, как разные модели ведут себя на проверяемых задачах, мы держим на странице бенчмарка – там видно, кто как справляется с фактами, а не с красивыми формулировками.
Промпт, который заставляет ИИ показывать источники и сомнения
Дам копируемый промпт под самую частую задачу из ответов – первичный обзор конкурентов. В нём две встроенные защиты: требование источника к каждому факту и требование явно помечать всё, в чём модель не уверена. Это превращает уверенную выдумку в честную гипотезу, которую видно глазами.
Запускайте его в инструменте с веб-поиском, иначе ссылки будут декоративными.
Обратите внимание на блок с белыми пятнами в конце. Большинство людей хотят от ИИ полный ответ и расстраиваются, когда он чего-то не знает. Но честное «вот это я не нашёл» полезнее красивого вымысла – оно показывает, куда направить собственное время, и не подсовывает ложь под видом результата.
Когда первый проход даст таблицу, не несите её дальше сразу. Прогоните результат через второй промпт – проверку на выдумки. Лучше всего открыть его в новом окне или другой модели, чтобы проверяющий не защищал то, что сам же написал.
Два этих шага вместе закрывают именно ту боль, которая звучала в запросах: собрать информацию о рынке, не утонув в выдумках. Первый собирает каркас с источниками, второй его атакует. То, что выживет после второго прохода, можно нести дальше. Принять первый ответ без проверки и вынести его сразу в работу – это то, что HBR называет thinkslop: результат выглядит профессионально, но за ним нет ничьей реальной мысли.
Попробуйте ИИ на задачах, где он любит выдумывать факты, и научитесь ловить это сразу. 9 управленческих ситуаций, бесплатно и без регистрации.
Доступ сразу после регистрации
Что стоит зафиксировать
Ресёрч с ИИ – это не «спросил и получил ответ». Это «спросил, получил гипотезу и проверил факты». Разница между двумя этими режимами и есть навык, который отделяет ускорение работы от тихого накопления ошибок в исходных данных.
Спрос на рыночный ресёрч у руководителей реальный и здравый. Люди тянутся к ИИ ровно там, где собрать информацию вручную долго и муторно. Слабое место – калибровка доверия: те же люди, которые точно формулируют, что нужно найти, готовы поверить выдуманному списку конкурентов, потому что он выглядит как настоящий.
Защита складывается из трёх простых движений. Брать инструмент с поиском, а не чат по памяти. Требовать источник к каждому факту и пометку ко всему непроверенному. Открывать ссылки и сверять цифры самому, особенно по нишевым игрокам и регуляторным нормам. Ни одно из этих движений не требует понимать, как устроена нейросеть. Требуется одна привычка – относиться к ответу ИИ как к черновику стажёра, а не как к справке из реестра.
И последнее. Самый дорогой провал в ресёрче выглядит не как явная ошибка, а как аккуратный, складный, правдоподобный отчёт, в котором одна строка – выдумка. Поймать её можно только проверкой. Вопрос к вам – какую цифру из последнего AI-отчёта вы понесли дальше, ни разу не открыв источник?
Научитесь отличать факт от правдоподобной выдумки ИИ
Фундамент курса строит ту самую ментальную модель: где ИИ ускоряет ресёрч, а где сочиняет, как заставить его показывать источники и как проверять результат. На реальных управленческих задачах, а не на абстрактных примерах.

Часто задаваемые вопросы
Можно ли доверять анализу конкурентов, который сделал ChatGPT?
Какой инструмент лучше для рыночного ресёрча с ИИ?
Почему ИИ выдумывает факты в исследованиях рынка?
Как заставить ИИ давать источники при анализе рынка?

mysummit.school
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.