Локальные LLM для менеджера: что реально запустить дома

AI-модели в этой статье
Каждый, кто достаточно долго работает с ChatGPT или Claude, рано или поздно задаёт этот вопрос: а можно ли запустить что-то похожее прямо на своём ноутбуке – без подписки, без утечки данных, без зависимости от серверов?
Ответ в 2026 году – да, но с оговорками, которые важнее самого ответа.
Эта статья для тех, кто уже пользуется облачными LLM и хочет понять, что реально даёт локальный запуск, какое железо для этого нужно и где заканчиваются ожидания. Без технического глубокого погружения, но с конкретными цифрами.
Зачем вообще запускать модель локально
Прежде чем разбираться в железе, стоит ответить на более важный вопрос.
У облачных сервисов есть три реальных ограничения, которые чувствуют на практике: конфиденциальность данных (вы не всегда уверены, что клиентские переписки не индексируются), зависимость от доступности (ChatGPT падает в часы пик, Claude недоступен в России без VPN), и стоимость при высокой интенсивности использования.
Локальная модель решает эти три вещи сразу: данные не покидают ваш компьютер, работает офлайн, и после первоначальной загрузки не стоит ничего. Это её реальная ценность – а не «бесплатный GPT-5 у себя дома», что было бы неправдой.
Вопрос только в том, за какую цену – в смысле железа и качества ответов.
Что это вообще такое: модели и их размеры
Размер языковой модели принято измерять в миллиардах параметров – числах, которые модель «запомнила» в процессе обучения. Обозначается буквой B: 7B, 14B, 70B.
Для менеджера это не технический термин, а практическая подсказка: сколько оперативной памяти нужно, чтобы модель вообще запустилась.
Грубое правило: модель занимает примерно полтора гигабайта памяти на каждый миллиард параметров при использовании 4-битного сжатия. Это значит, что 7B-модель занимает около 5 ГБ, 14B – примерно 9 ГБ, 32B – около 20 ГБ, и так далее. Для ноутбука с 16 ГБ оперативки всё, что больше 14B, уже не поместится полностью в быструю память – модель начнёт «свопиться» и работать ощутимо медленнее.
Квантизация – это и есть то сжатие, о котором речь. Оригинальная модель хранит числа с высокой точностью; квантизация уменьшает эту точность, чтобы сократить размер в 2–4 раза. Небольшая потеря качества в обмен на возможность запустить вообще.
Для масштаба: облачные флагманы вроде Claude Sonnet 4.6 и GPT-5.4 свои параметры официально не раскрывают, но по отраслевым оценкам речь идёт о сотнях миллиардов или триллионах параметров в архитектуре Mixture-of-Experts. Даже если активно работает лишь часть (условные 30–50B на запрос), общий вес модели измеряется терабайтами и требует датацентра с десятками специализированных ускорителей. Локальная 8B-модель на ноутбуке – это примерно 1% от размера облачного флагмана. Отсюда и разрыв в качестве на сложных задачах: не потому что авторы локальных моделей хуже, а потому что масштаб другой на два порядка. Ниже график по количеству параметров моделей, которые мы можете запустить локально и в облаке от Epoch AI.
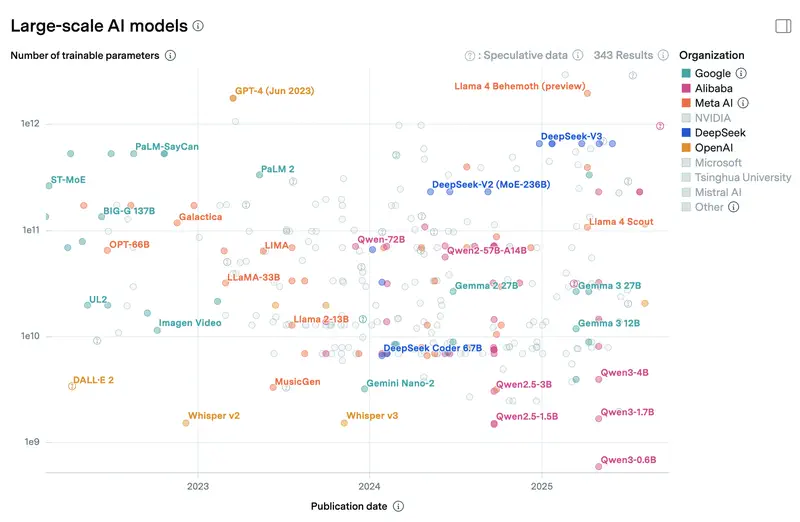
Какие модели актуальны в апреле 2026
Ландшафт открытых моделей обновляется быстрее, чем большинство корпоративных политик. Картина апреля 2026 получается неожиданной для тех, кто следил за новостями ИИ через западные издания: на передовой сейчас не только Meta и Google, а целый ряд китайских лабораторий и один сюрприз от OpenAI.
DeepSeek V3.2 – безоговорочный лидер среди открытых моделей. 671B MoE с 37B активными параметрами на запрос, вышла в декабре 2025, контекстное окно – 163 тысячи токенов. Мы разбирали DeepSeek подробно: на управленческих задачах она стабильно попадает в верхний кластер. Для локального запуска полноразмерная V3.2 не подходит – на личном железе её не развернуть. Но дистилляты на её базе (7B, 14B) работают с 8 ГБ VRAM и значительно сильнее обычных локальных моделей того же размера в аналитике и логических задачах.
Qwen-семейство от Alibaba – второе ключевое направление среди локально запускаемых моделей. Qwen 3.5 вышел в феврале–марте 2026 и охватывает диапазон от 0,8B до флагманского 397B MoE, который не предназначен для локального запуска. Для домашнего использования ключевые размеры – 27B dense (~16 ГБ VRAM Q4, запускается на 8 ГБ GPU), 9B и 4B. 2 апреля вышел Qwen 3.6-Plus в MoE-архитектуре с контекстом 1 миллион токенов. В нашем обзоре Qwen семейство получило высокие оценки именно за работу с русским языком без явных потерь качества по сравнению с английским – для менеджеров, которые работают на двух языках, это практически важный параметр.
Китайские лаборатории в целом стали полноценной альтернативой западным флагманам. Среди наиболее заметных открытых моделей этого круга:
- Xiaomi MiMo-V2-Pro (март 2026) – модель для рассуждений, контекст 1 миллион токенов.
- MiniMax M2.5 и M2.7 (февраль–март 2026) – крупные MoE-модели с контекстом 196 тысяч токенов.
- Z.ai GLM 5.1 (7 апреля 2026) – свежайший релиз в этом списке, контекст 202 тысячи токенов.
- MoonshotAI Kimi K2.5 (январь 2026) – контекст 262 тысячи токенов.
- StepFun Step 3.5 Flash (январь 2026) – компактнее остальных, но широко используется в пайплайнах.
Ни одну из этих моделей нельзя запустить на ноутбуке – они работают через API или self-hosted на серьёзном железе (64+ ГБ памяти, многокартные конфигурации). Но они показывают, где реально находится открытый ИИ-рынок.
gpt-oss-120b от OpenAI (август 2025) – редкий случай, когда OpenAI выпустила открытые веса. 120B MoE-модель с устойчивым использованием спустя восемь месяцев после релиза. Для локального запуска требует уровня Mac Studio с 64+ ГБ или рабочей станции с двумя видеокартами.
Gemma 4 26B A4B от Google – это та версия Gemma, которая реально используется на практике. Не 31B и не 12B, а именно 26B в MoE-архитектуре с 4 миллиардами активных параметров на запрос – отсюда и «A4B» в названии. Контекст 262 тысячи токенов, запускается через Ollama на ноутбуке с 16 ГБ памяти быстрее, чем dense-аналоги того же класса. 4B-версия запускается на телефоне через Google AI Edge Gallery.
NVIDIA Nemotron 3 Super – контекст 262 тысячи токенов, доступна бесплатно на OpenRouter. Популярный выбор для экспериментов с агентами и пайплайнами, где важно не тратить деньги на каждый запрос.
Mistral Nemo – компактная модель для CPU-инференса. Скромнее по масштабу, чем лидеры, но для класса «работает без видеокарты» это реальная рабочая лошадка.
Отдельно стоит упомянуть модели, которые активно обсуждаются в технических публикациях, но реже встречаются в массовом использовании: Llama 4 Scout, Llama 3.3 70B, Phi-4, Mistral Small 3.1. В self-hosted установках они встречаются часто – там выбор определяется интеграциями и привычкой, а не популярностью.
Какое железо нужно и что вы получите
Здесь начинается зона, где ожидания и реальность расходятся сильнее всего.
Минимальный вариант: любой современный ноутбук с 16 ГБ RAM
Ноутбук с 16 ГБ оперативки и без видеокарты запустит модели до 8–10B через llama.cpp или Ollama, используя обычный процессор. Это работает – но медленно.
Скорость генерации на CPU составит от 3 до 8 токенов в секунду. ChatGPT отдаёт текст со скоростью около 40–80 токенов в секунду (это то, что вы воспринимаете как «печатает быстро»). 8 токенов в секунду – это примерно один-два слова каждые две секунды. Для длинных ответов ощущается как замедленная съёмка. Пользоваться можно, комфортно не всегда.
Для простых задач – резюмирование короткого текста, ответ на конкретный вопрос – вполне терпимо. Для итеративного диалога быстро надоедает.
Хороший вариант: M-серия Apple или RTX 3060 12 ГБ
Это тот порог, после которого локальный LLM начинает ощущаться как настоящий инструмент, а не демонстрация технологии.
Mac с чипами M3, M4 или M5 и 16–32 ГБ унифицированной памяти – это, пожалуй, лучшая платформа для локальных LLM на сегодня. Причина: унифицированная архитектура, где CPU и GPU делят одну память, позволяет запускать модели быстро без дополнительной видеокарты. Фреймворк MLX от Apple оптимизирован для этих чипов и работает на 20–30% быстрее, чем стандартный llama.cpp на том же железе.
Qwen 3.5 9B на M3 Pro выдаёт около 25–35 токенов в секунду. Gemma 4 26B A4B (MoE с активными 4B) на M4 Max – 30–45 токенов в секунду при гораздо большей эффективной ёмкости модели. Mac с 32 ГБ уверенно держит 15–30 токенов в секунду на 13B-классе, с 64 ГБ – 25–50 токенов на 27–32B моделях. Это уже ощущается как нормальная скорость чата. С марта 2026 года Ollama официально перешёл на MLX как основной бэкенд на Apple Silicon – то есть просто установив Ollama на современный Mac, вы уже получаете оптимизированную производительность.
RTX 3060 12 ГБ – для Windows-пользователей это самый доступный способ попасть в ту же лигу. Карта б/у стоит около 15–20 тысяч рублей, а 12 ГБ видеопамяти достаточно для комфортного запуска 7B- и 14B-моделей. Gemma 4 26B A4B также умещается в 12 ГБ за счёт MoE-архитектуры. Qwen 3.5 27B dense не поместится целиком в 12 ГБ, а вот Qwen 3.5 9B выдаёт на RTX 3060 около 20–40 токенов в секунду. По скорости – примерно как хороший Mac.
Важный нюанс про термин. Инференс – это процесс, когда обученная модель отвечает на ваш запрос (в отличие от обучения, когда модель настраивают на данных). GPU-инференс означает, что модель работает на видеокарте, а не на процессоре. Видеокарта параллельно перемножает матрицы в десятки раз быстрее процессора, и для языковых моделей это даёт разницу между «секундная задержка» и «минута ожидания».
Для GPU-инференса нужна именно видеопамять (VRAM), а не обычная оперативка. 12 ГБ VRAM RTX 3060 – это 12 ГБ именно для модели. Если модель не влезает в VRAM, часть выгружается в RAM и скорость падает в несколько раз.
Чтобы понять, что именно получаете за разный размер модели, сравните три запуска на одной задаче: Gemma 4 26B A4B (самая популярная Gemma на OpenRouter, реально запускается на ноутбуке за счёт MoE), gpt-oss-120b (открытые веса от OpenAI, требует Mac Studio или двух видеокарт) и DeepSeek V3.2 (облачный флагман открытой экосистемы, ~37B активных в MoE):
На практике Gemma 4 26B A4B даст структурированный ответ с разделением случаев – лучше, чем типичная 8B-модель, но системный вывод обычно предсказуемый. gpt-oss-120b предложит более нюансированную стратегию и задаст релевантные уточняющие вопросы, хотя глубина зависит от конкретного запроса. DeepSeek V3.2 уровня облачного флагмана выдаст структуру с приоритизацией, реалистичными сроками и нетривиальным наблюдением про оставшихся четырёх. Это и есть та разница, за которую платят в облаке.
Продвинутый вариант: 70B и выше
70B-класс в 4-битном сжатии занимает около 48 ГБ памяти (нужно 40 ГБ+ для полного качества). Нужна Mac Studio с 64 ГБ, сервер с несколькими видеокартами или рабочая станция с RTX 4090 24 ГБ в паре с дополнительной памятью. RTX 4090 справляется с Gemma 4 26B A4B и dense-моделями до 31B, выдаёт 50–85+ токенов в секунду. gpt-oss-120b в этот класс не попадает – 120B MoE требует 64+ ГБ единой памяти или двух карт.
Скорость при этом – 8–15 токенов в секунду. Качество приближается к GPT-5 Mini. Но стоимость входа – от 150–200 тысяч рублей за железо. Это уже не «попробовать дома», а осознанная инвестиция с конкретным обоснованием.
20 токенов в секунду – это быстро или медленно?
Это вопрос, который редко объясняют явно.
Один токен – примерно 3/4 слова в английском, чуть меньше в русском из-за длины слов. Двадцать токенов в секунду – это примерно 15 слов в секунду, или около 900 слов в минуту. Для сравнения: средний человек читает 200–300 слов в минуту.
Двадцать токенов в секунду – это быстро. Вы будете читать медленнее, чем модель пишет. Приятный опыт.
Восемь токенов в секунду – это в среднем 6 слов в секунду. Всё ещё читаемо, но чувствуется пауза в длинных предложениях. Годится для задач без спешки.
Три токена в секунду – это практически построчный вывод. Долгий ответ занимает заметное время. Можно работать, но постоянного диалога не получится.
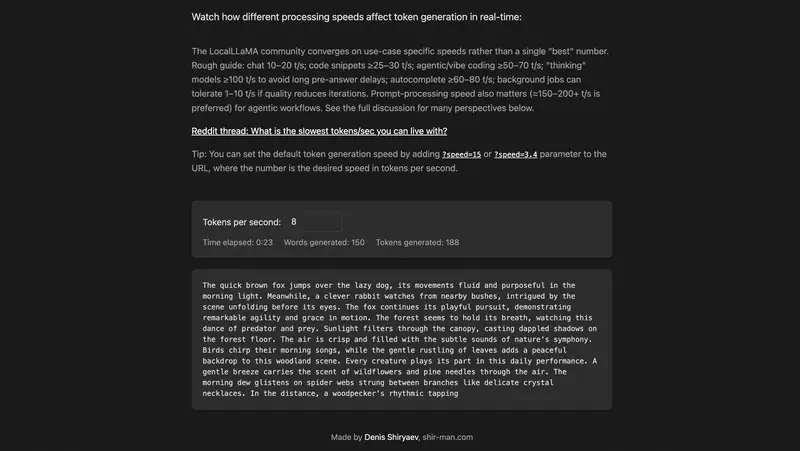
Каждая из цифр выше – кликабельная ссылка на симулятор shir-man.com/tokens-per-second, где текст появляется в реальном времени с заданной скоростью. Минута на эксперимент даёт понимание разницы лучше любого описания.
Для справки: GPT-5 выдаёт 40–80 токенов в секунду в зависимости от загрузки серверов. При низкой нагрузке – быстрее, в час пик – медленнее. Хорошая локальная установка вполне сопоставима по скорости восприятия.
Есть важная оговорка, о которой редко говорят: у рассуждающих моделей (reasoning-моделей) видимая скорость печати – это только половина истории. Перед тем как начать отвечать, такая модель может несколько минут «думать» внутри себя – генерировать скрытую цепочку рассуждений, которую вы не видите. Локальная рассуждающая модель на ноутбуке может потратить 5–10 минут на внутренний анализ, а потом ещё минуту печатать ответ со скоростью 20 токенов в секунду. На экране это выглядит так: вы задали вопрос, курсор мигает, ничего не происходит – модель работает. Это нормально для reasoning-режима, но к этому надо быть готовым. В облаке то же самое происходит за 10–30 секунд благодаря мощности датацентра. Для итеративного диалога разница критична; для фоновой задачи («подумай над этим, пока я пью кофе») – не очень.
Качество: честное сравнение
Вот где надо быть аккуратным с ожиданиями.
Локальная 8B-модель не равна GPT-5 или Claude Sonnet. Это важно понять до, а не после скачивания. В нашем рейтинге 54 моделей на управленческих задачах GPT-5.4 набрал 4,8 из 5, Claude Sonnet 4.5 – 4,78, Gemini 2.5 Pro – 4,46. Типичная локальная 8B-модель попала бы в диапазон 2,8–3,3 – туда, где в том же рейтинге находятся GigaChat-Ultra (3,26) и Llama 4 Maverick (2,95). Не потому что плохие – просто другой класс задач.
Конкретные модели, которые реально запустить локально, в нашем бенчмарке выглядят так: Gemma 3 12B набрал 3,58 (кластер 3), Qwen3 32B – 3,67, Gemma 3 27B – 3,75. Это уже интереснее: примерно уровень Alice AI от Яндекса (3,86) или чуть ниже. Phi-4, 3,8B-модель от Microsoft, которую активно рекомендуют за «умность» в синтетических тестах, набрал всего 2,27 – последнее место среди 54 моделей. Это напоминание о том, что синтетические бенчмарки и управленческие задачи – разные вещи. Сверяйтесь с нашим бенчмарком, прежде чем выбирать модель.
Для 70B и выше картина меняется. Модели этого класса в бенчмарке не тестировались напрямую, но по параметрам они близки к кластеру 3 – ориентировочно в зоне 3,5–3,8, то есть уровень Qwen3 32B или чуть выше. Это уже серьёзный инструмент для большинства ежедневных задач. Разрыв с Claude Sonnet или GPT-5 сохраняется в задачах, требующих глубокого контекстного понимания или многоходовых выводов – но для резюмирования документов, подготовки черновиков и структурированных запросов он значительно меньше.
Чтобы увидеть разрыв своими глазами – вот бюджетный GPT-5.4 Nano против флагманского GPT-5.4 на типичной управленческой задаче. GPT-5.4 Nano стоит на порядок дешевле и по скорости ответа сопоставим с приличной локальной 70B-моделью. Сравните, что теряется при выборе более слабой модели:
Разница видна не в красоте формулировок, а в глубине разбора: мини-модель обычно принимает три причины как равные и даёт общие рекомендации, флагман – разделяет симптомы от корневой причины и задаёт вопросы по существу. Локальная 70B ведёт себя ближе к мини-модели, локальная 8B – существенно хуже.
Конкретные сценарии, где локальная 8B справляется хорошо:
- Резюмирование документов и транскриптов встреч
- Генерация черновиков писем и отчётов по шаблону
- Простые вопросы-ответы по загруженному документу
- Форматирование и структурирование текста
Сценарии, где лучше вернуться к облаку:
- Сложный анализ с неочевидными выводами
- Работа с конкурирующими гипотезами
- Задачи, где важна точность фактических данных
- Длинные многошаговые инструкции с условиями
Разбираетесь, какой ИИ и когда использовать – это именно то, что делают 9 практических задач открытого модуля. Попробуйте бесплатно, без регистрации.
Доступ сразу после регистрации
Смартфон как локальная платформа
Отдельная тема, которая ещё год назад была экспериментом, а сейчас стала вполне рабочим сценарием.
Gemma 4 4B от Google (вышла 2 апреля 2026) – один из ключевых мобильных вариантов. Запускается через Google AI Edge Gallery для iOS и Android, скачивается один раз и работает полностью офлайн. На iPhone 16 Pro с чипом A18 Pro и 8 ГБ (1100 EUR) памяти или Samsung Galaxy S24/S25 Ultra (900 EUR) – около 15–20 токенов в секунду. Phi-4 3,8B от Microsoft даёт похожую скорость на тех же устройствах. Llama 3.2 3B и Qwen 3.5 4B также запускаются через PocketPal или MLC LLM.
Qwen 3.5 в версиях 0,8B и 4B также запускается на телефонах через PocketPal. Скорость на флагманских телефонах (iPhone 17 Pro, Pixel 9 Pro, Samsung S24/S25) – 5–20 токенов в секунду. На среднем сегменте с 6 ГБ RAM результат скромнее; для комфортного запуска нужно минимум 8 ГБ памяти устройства.
Практическая ценность телефонного запуска ограничена несколькими сценариями: анализ конфиденциального документа там, где нет интернета, быстрый черновик без доступа к облаку, демонстрация концепции. Для регулярной работы экран и интерфейс телефона – не лучшая среда. Но как возможность – вполне реальная.
Инструменты: что устанавливать
Ollama – самый простой способ начать. Устанавливается как обычная программа, модели скачиваются одной командой (ollama pull qwen3.5:9b), работает через браузер или любое приложение с OpenAI-совместимым API. С марта 2026 использует MLX на Apple Silicon. Рекомендуется большинству.
LM Studio – графический интерфейс поверх llama.cpp и MLX. Если командная строка вызывает дискомфорт, LM Studio позволяет делать то же самое через визуальный интерфейс: выбрать модель, скачать, запустить чат. Чуть тяжелее по ресурсам.
Jan – open-source вариант с упором на приватность. Работает полностью офлайн, не отправляет никакую телеметрию. Если конфиденциальность – основной мотив, стоит рассмотреть.
llama.cpp – базовый движок, на котором работают все три инструмента выше. Консольный инструмент для тех, кто хочет максимальный контроль. Для менеджера без технического бэкграунда – скорее нет.
MLX от Apple – библиотека непосредственно от Apple для запуска моделей на Silicon. Используется внутри Ollama, но можно и напрямую. Даёт 20–30% прирост скорости по сравнению с llama.cpp.
Локальный ИИ – это один из форматов работы. В открытом модуле – 9 задач менеджера с разными инструментами, облачными и локальными. Попробуйте бесплатно.
Доступ сразу после регистрации
Агентный режим: локальная модель с доступом к файлам
Если вы читали про OpenCode или агентный анализ данных, возникает логичный вопрос: а можно ли запустить агента локально, без отправки данных в облако?
Да, и это, пожалуй, наиболее интересный сценарий для менеджеров, работающих с конфиденциальными документами.
OpenCode, который мы подробно разбирали ранее, поддерживает подключение локальных моделей через Ollama. Схема такая: Ollama запускает модель локально и открывает локальный API на порту 11434. OpenCode подключается к нему вместо облачного Claude. Данные не покидают компьютер. Агент читает ваши файлы, анализирует, пишет результаты – всё локально.
Ограничение предсказуемое: локальная 8B-модель в агентном режиме справляется с более простыми задачами, чем Claude или GPT-5. Для анализа одного-двух документов по конкретным вопросам – вполне. Для сложного многофайлового исследования с нетривиальными выводами – разрыв будет заметен. Как мы показывали на конкретном примере, качество агентного анализа определяется в первую очередь моделью, а не фреймворком.
При 32B-модели и выше разрыв становится значительно меньше. Если у вас Mac Studio с 64 ГБ или рабочая станция с двумя видеокартами – агентный локальный режим с 32B-моделью становится полноценной заменой облаку для большинства задач.
Минимальная точка входа: что купить
Если коротко:
Для старта – Mac с чипом M3 или M4 и 16 ГБ памяти. Если у вас уже есть такой Mac, у вас уже есть нужное железо. Ollama устанавливается за 5 минут, и вы можете запустить Qwen 3.5 9B или Gemma 4 26B A4B сегодня.
Для комфортной работы с моделями 14–32B – Mac с 32 ГБ памяти или ПК с RTX 3060/4060 12 ГБ. RTX 3060 12 ГБ на вторичном рынке стоит около 15–20 тысяч рублей – это самый дешёвый путь к нормальному опыту на Windows.
Для замены облака без компромиссов – Mac Studio с 64 ГБ (это уже существенные вложения) или рабочая станция с двумя видеокартами (3000 USD)
Стоит сказать честно: для большинства менеджеров оптимальный ответ – не «перейти на локальные модели», а использовать их как дополнение к облаку. Облако для сложных задач, где важно качество. Локально – для конфиденциальных данных, работы офлайн и случаев, когда нет смысла платить за облако за простые операции.
Что осталось неочевидным
Есть несколько вещей, которые обычно выясняются после установки, а не до.
Размер модели при скачивании – это финальный размер на диске. 8B-модель в формате Q4 весит около 5 ГБ. 32B – около 20 ГБ. При использовании Ollama скачанные модели хранятся в системной папке; иногда на маленьком диске неожиданно заканчивается место.
Первый запуск занимает время. Ollama загружает модель в память при первом обращении – это может занять 30–60 секунд для большой модели. После этого она остаётся в памяти, и последующие запросы быстрые.
Системный промпт на русском работает лучше, чем его отсутствие. Большинство моделей обучены на смешанных данных, но отвечают на том языке, на котором с ними говорят. Явное указание «отвечай на русском» в начале сессии помогает.
Для сравнения качества локальных и облачных моделей на управленческих задачах есть наш публичный бенчмарк – там можно посмотреть, где именно конкретные модели теряют в качестве относительно топовых облачных.
Наконец, возможность запустить модель локально не означает, что так нужно делать всегда. Это дополнительный инструмент с понятными условиями применения. Именно об этом навыке – понимать, когда какой инструмент уместен, – речь в нашей учебной программе.
Интересно, что сама логика выбора инструмента – облако или локально, 8B или 70B, агент или чат – это ровно тот же тип навыка, что и грамотное формулирование задач для ИИ. Инструменты меняются каждые несколько месяцев, а умение калибровать ожидания и выбирать подход под задачу – остаётся.


Локальная модель запущена. Что с ней делать?
Локальный LLM – это приватность и автономность. Но навык формулировать задачи один и тот же: облако, локалка, агент. В курсе 9 бесплатных уроков для менеджеров – научитесь ставить задачи ИИ так, чтобы результат не зависел от конкретной модели.

Stanislav Belyaev
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.