Make Weak Model Great Again: промпты против слабых моделей
В марте 2026 года Минцифры опубликовало законопроект о «доверенных моделях» ИИ. Если его примут – вступление в силу планируется с сентября 2027 – госструктуры и критическая инфраструктура смогут использовать только модели из специального реестра. ChatGPT, Claude и Gemini, передающие данные за рубеж, могут быть ограничены. На устройства планируется обязательная предустановка российских нейросетей.
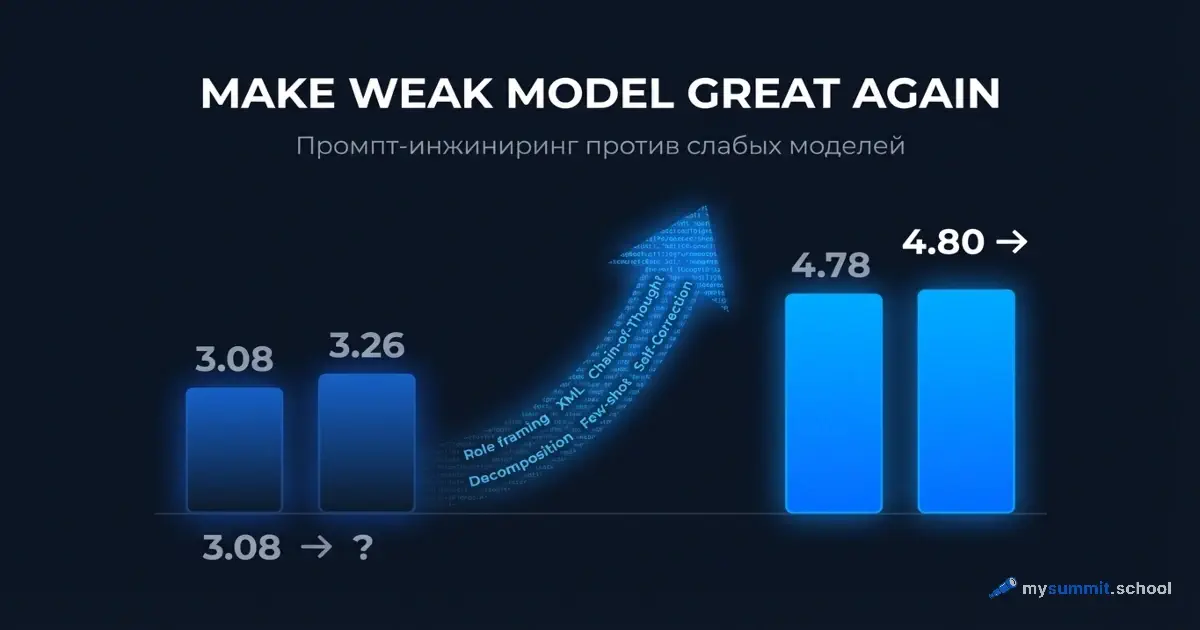
Проблема в том, что российские модели отстают. В нашем исследовании 54 моделей GigaChat набрал 3,26 из 5, GPT-5.4 – 4,80. Разрыв 32%.
Если GigaChat – всё, что у вас будет, можно ли вытянуть из него приемлемое качество с помощью грамотного промптинга?
Что мы делаем и зачем
Эксперимент «Make Weak Model Great Again» берёт четыре модели, доступные в России – GigaChat-Ultra, GigaChat-2-Max, Alice AI (YandexGPT) и Qwen3 Max – и прогоняет каждую через десять техник промптинга на шести управленческих задачах: от анализа метрик e-commerce до российского трудового права. Для сравнения те же задачи решают GPT-5.4 и Claude Sonnet 4.6 с наивными промптами – чтобы зафиксировать потолок, к которому тянутся слабые модели.
Техники разные – от простых, которые любой менеджер может освоить за минуту (ролевое задание, структурированный шаблон), до многошаговых диалогов, где модель сначала анализирует, потом критикует себя, потом дорабатывает ответ. Между ними – Chain-of-Thought («думай пошагово»), Few-Shot примеры (показываем образец хорошего ответа) и XML-структура промпта, которую обычно используют разработчики, а не менеджеры.
Но две техники делают этот эксперимент по-настоящему необычным: CAPS EMPHASIS и агрессивный тон. В интернете полно советов «напиши КАПСОМ – и модель послушается» или «поругайся на неё, она выдаст лучше». Кто-то ссылается на исследование Microsoft 2024 года, кто-то – просто на личный опыт. Научного основания под этим почти нет, тем более для российских моделей. Мы включили обе техники, чтобы раз и навсегда проверить: это работает – или это городская легенда промпт-инжиниринга?
Почему ответ не очевиден заранее
Казалось бы, лучший промпт -> лучший результат. Но с небольшими моделями всё сложнее, и существующие исследования это подтверждают.
Wei et al. (Google Brain, 2022) показали, что Chain-of-Thought – техника, которая заставляет модель «думать пошагово» – отлично работает на больших моделях. Но у маленьких она провоцирует «уверенные, но неправильные» рассуждения. Модель выдаёт пять шагов, которые выглядят логично – и приходит к ошибочному выводу. Хуже, чем если бы она ответила сразу. Попадает ли GigaChat в эту ловушку – мы не знаем.
Zhang et al. (ACL 2024) установили ещё более неприятную вещь: малые модели физически не способны обнаружить собственные ошибки. Когда вы просите «найди слабые места в своём ответе и улучши его», модель не критикует себя – она «самоподтверждает». Немного переформулирует, не меняя сути. Если наши данные это подтвердят на российских моделях – это конкретный вывод: не тратить время на «улучши свой ответ» с GigaChat.
А есть ещё архитектурный потолок. Промпты реорганизуют то, что модель уже знает. Они не могут создать знания, которых нет в весах модели. Если GigaChat не «читал» Трудовой кодекс РФ во время обучения – никакой промпт «ты опытный юрист по ТК РФ» не заставит его процитировать кодекс правильно. Лучшее, чего можно добиться – чтобы модель сказала «я не знаю» вместо уверенной галлюцинации.
Кстати, в нашем бенчмарке обнаружился контринтуитивный результат: GigaChat и Alice – модели, обученные на русском – показали более низкие результаты, чем GPT-5.4 на задачах, связанных с российской реальностью. Трудовое право, региональные рынки, отечественная бизнес-специфика – по всем этим темам иностранная модель оказалась сильнее нативной. Вероятно, GPT-5.4 просто «прочитал» больше материалов о ТК РФ за счёт масштаба. Это один из ключевых вопросов эксперимента: где проходит граница, после которой никакой промпт не компенсирует разрыв в знаниях?
Промпт-техники из этого исследования лягут в основу учебных материалов. Попробуйте 9 практических задач менеджера в открытом модуле – бесплатно, без регистрации.
Доступ сразу после регистрации
Что получит менеджер по итогам
Мы намеренно делаем это прикладным исследованием, а не академическим. Научные работы по малым языковым моделям обычно фокусируются на автоматизированной оптимизации – fine-tuning, DSPy, алгоритмическое улучшение промптов. Нас интересует другое: что может сделать обычный менеджер, у которого есть GigaChat и пять минут на формулировку запроса?
Для каждой техники мы оцениваем не только качество результата, но и усилие – сколько времени нужно потратить на переформулировку промпта. Потому что техника, которая улучшает ответ на 15%, но требует 20 минут подготовки, менеджеру не нужна.
По итогам выйдут три вещи. Первая – карта «техника -> модель -> задача»: если у вас GigaChat на задаче анализа документов, какой подход использовать? Если Alice на написании письма? Вторая – готовые шаблоны на русском языке под конкретные управленческие задачи. И третья – честная граница: в каких сценариях промптинг не помогает и лучше переключиться на другую модель.
Всё это войдёт в учебный курс – в раздел, где теория промпт-инжиниринга встречается с данными. Не «что такое промпт», а «что реально работает, на каком инструменте, для какой задачи».
Qwen3 Max, Alice, GigaChat – доступны без VPN. Проверьте свой подход к промптингу на реальных задачах менеджера в бесплатном модуле курса.
Доступ сразу после регистрации
Когда ждать результатов
Эксперимент в фазе запуска. Полный отчёт выйдет здесь, в блоге – с разбором каждой техники, конкретными шаблонами и честным выводом о том, где потолок. Если вы ежедневно работаете с GigaChat или Alice – ответ на ваш вопрос готовится.
Инструмент есть. Теперь – навык
Фундамент курса разбирает промпт-инжиниринг на реальных управленческих задачах: структуру, ролевые задания, декомпозицию, CoT. Специализация для менеджеров углубляет применение в планировании, аналитике и работе с командой.