5 сигналов срыва спринта за 2–3 спринта раньше: готовые промпты для ChatGPT и Gemini

Статус-митинг по пятницам. PM открывает слайд: «Мы на две недели отстаём от плана». Руководитель спрашивает: «Когда стало понятно?» PM честно отвечает: «Неделю назад, когда собрал данные для отчёта».
Проблема системная. Статус-отчёты описывают прошлое. К моменту, когда отклонение попадает в слайд, команда уже живёт с ним несколько дней, заинтересованные стороны уже слышат тревожные сигналы в коридорах, а окно для дешёвого реагирования закрылось.
Данные, которые могли бы предупредить о проблеме, всё это время лежали в Jira и GitHub. Просто никто не смотрел на них под нужным углом.
Эта статья – для PM, работающих с Jira, Asana и GitHub. Если вы управляете строительными проектами и ваши данные в 1С:ERP, ЦУС или Spider Project – версия для строительства выйдет отдельно: субподрядчики, поставки, КС-формы и календарный план вместо спринтов и коммитов.
Пять сигналов, которые видны до статуса
Адаптированный для agile Earned Value Management обнаруживает проскальзывание за 2–3 спринта до того, как команды сообщают о нём сами – это устойчивый вывод из практики применения EVM в итеративной разработке. Troy Magennis из Focused Objective продемонстрировал, что Monte Carlo-симуляции на основе пропускной способности команды на 40–60% точнее, чем оценки «на глаз».
Но для этих методов нужен аналитик, время и дисциплина. Агентный ИИ делает ту же работу за 5 минут – если знать, что спросить.
Ниже – пять конкретных сигналов. Каждый – с промптом, который работает на реальной выгрузке из Jira или Asana.
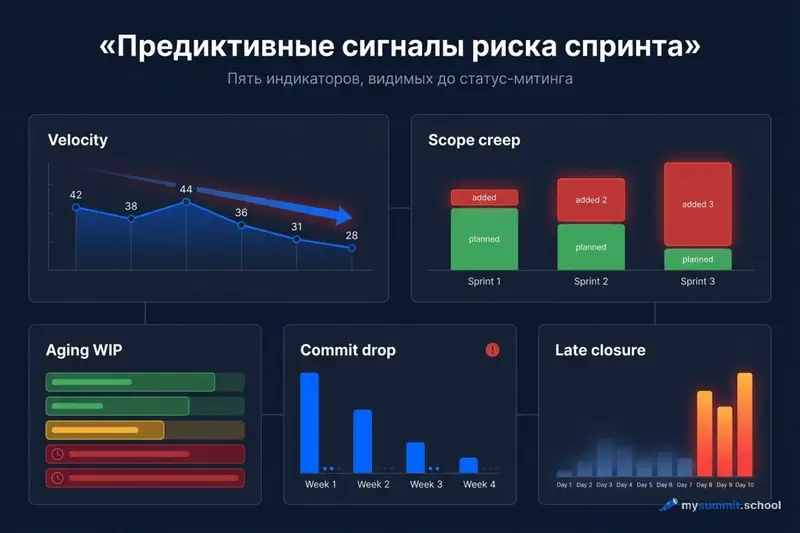
1. Падение темпа команды – скорость снижается от спринта к спринту
Самый очевидный сигнал и при этом самый игнорируемый. Падение velocity на 15%+ за два спринта подряд коррелирует с последующим срывом сроков – это консенсус agile-практиков, подтверждённый данными Digital.ai State of Agile.
Голая velocity – тривиальный случай: тренд видно глазом, никакой агент не нужен, чтобы заметить 42 -> 28. Ценность появляется, когда нужно нормализовать velocity по составу команды (отпуска, онбординг, болезни), учесть будущие праздники и состав следующего спринта, и сформулировать гипотезы – откуда падение, когда нет очевидной причины. Вот промпт, который делает эту работу.
2. Разрастание содержания – сколько задач добавляется на лету
Когда задачи добавляются в спринт быстрее, чем закрываются – команда теряет контроль над содержанием проекта. По данным моделирования Magennis, если добавленные в середине спринта задачи превышают 20% от изначального обязательства спринта – вероятность выполнения падает ниже 50%.
3. Накопление застрявших задач – работа, которая копится без движения
Стареющая незавершённая работа – самый сильный сигнал из всех. Задача, висящая в статусе «В работе» дольше, чем удвоенное среднее время цикла команды, почти наверняка заблокирована. Три таких задачи одновременно – и спринт в опасности. Пять – спринт уже сорван, просто об этом ещё не знают.
Dan Vacanti в «Actionable Agile Metrics for Predictability» показал: объём незавершённой работы (WIP), превышающий пропускную способность команды, создаёт нелинейный рост времени цикла для всех задач.
4. Спад коммитов – тишина в репозитории
Cataldo и Herbsleb (IEEE Transactions on Software Engineering, 2009) обнаружили, что изменения в частоте коммитов и паттернах интеграции кода предшествуют провалам интеграции на 1–3 недели. Паттерн: частота коммитов падает, а объём изменений в одном коммите растёт. Разработчики перестают делать маленькие инкрементальные изменения и начинают «копить» большие патчи.
Для PM это сигнал, который виден без технической экспертизы – достаточно выгрузки из GitHub.
Почему промпт устроен именно так
Этот промпт – не первый черновик. Первая версия теряла половину данных: DeepSeek и Qwen молча выбрасывали PR на границе недель и считали метрики на 5 PR в W1 вместо 9. Структура, которую вы видите выше, появилась после прогона на трёх моделях и фиксации каждого сбоя. Каждый элемент решает конкретную проблему:
- Блок
<data>вокруг исходных данных изолирует их от инструкций. Без изоляции модель путает «что считать» с «откуда брать», особенно когда данные похожи на текст инструкции. - Обязательный Шаг 1 с явным перечислением PR по неделям и контрольной суммой Σ = 23 заставляет модель проверить себя до начала расчётов. Именно эта техника подняла DeepSeek с 5 PR в W1 до правильных 9.
- Восемь пронумерованных шагов вместо общего списка задач удерживают модель от перепрыгивания: каждое действие следует предыдущему, агрегация невозможна без перечисления.
- Напоминание в конце («Шаг 1 обязателен») – техника сэндвича. В длинном промпте внимание модели к началу размывается; повтор критичного требования в конце восстанавливает приоритет.
Структура – не магия и не «секреты промптинга». Это четыре конкретных приёма, которые превращают промпт из черновика в инструмент: изоляция данных, обязательные шаги, самопроверка, сэндвич. Без них агент будет считать на неполных данных – и не скажет об этом.
Четыре приёма выглядят очевидно после прочтения. Сложнее заметить, когда промпт уже ошибся – не в расчётах, а в исходных допущениях. Именно это отделяет аналитика от человека, который верит красиво оформленным таблицам.
Промпт как инструмент, а не лотерея
Статья показала четыре техники – изоляцию данных, обязательные шаги, контрольные суммы и сэндвич. В курсе вы применяете их на 10 задачах со своими данными и учитесь отличать надёжный результат от правдоподобной галлюцинации – навык, который не даёт ни одна статья.
5. Поздние закрытия – всё уходит в последний день спринта
Когда больше 60% задач спринта закрывается в последние два дня – следующий спринт почти гарантированно просядет по velocity на 20–25%. Причина: «героическое» закрытие в конце означает, что задачи либо были недооценены, либо блокировались большую часть спринта, а потом закрывались через overhours. Команда приходит в следующий спринт уставшей.
Как подготовить данные – что экспортировать и в каком формате
Агент работает с текстом. Ему не нужен API-доступ к трекеру – достаточно выгрузки в CSV или скопированной таблицы.
Если вы на Yandex Tracker: Очереди -> Выгрузка задач (CSV / Excel). Нужные поля: ключ задачи, название, статус, дата создания, дата начала работ, дата завершения, story points (если ведёте), исполнитель, спринт, теги. Отдельно: отчёт по спринту из раздела «Гибкие методологии» – там velocity в виде графика, данные копируются вручную за 2 минуты.
Если вы на Kaiten: Экспорт карточек доски в CSV. Kaiten по умолчанию не оперирует story points и спринтами, поэтому метрики читаются иначе: вместо velocity – пропускная способность (закрытых карточек за неделю), вместо разрастания содержания – рост числа карточек в бэклоге или на доске за период, вместо завершения спринта – распределение времени цикла. Все промпты выше работают, если в данных есть даты входа и выхода из лейнов.
Если вы на Jira / Asana / Bitrix / YouTrack: Board export -> CSV. Нужные поля: ID задачи, название, статус, дата создания, дата начала работы, дата закрытия, story points, assignee, sprint, labels. Отдельно: sprint report (velocity chart data) за 4–6 спринтов. Changelog, если доступен: когда задача меняла статус, когда добавлялась в спринт.
Из GitHub / GitLab / Bitbucket:
- Contributor activity за 4 недели (commits per week, lines changed).
- PR list с датами: opened, first review, merged/closed.
- Не нужны diff’ы или содержание коммитов – только метаданные.
Минимальный набор, который уже работает
Темп команды (velocity) за 4–6 спринтов + текущий статус задач спринта. Для Yandex Tracker это два отчёта, оба встроенные. Для Kaiten – пропускная способность и список карточек с датами. Этого достаточно для сигналов #1, #2 и #5. Для сигналов #3 и #4 нужны данные по блокерам и коммитам соответственно.
Формат
Агенту всё равно – CSV, Markdown-таблица, даже скриншот (мультимодальные модели прочитают). Но лучше всего работает текстовая таблица: меньше ошибок распознавания, проще проверить.
Реальный пример: данные одного спринта команды из 5 человек
Вот пример выгрузки, которую PM может получить из трекера (или собрать вручную за 15 минут) и загрузить в агента целиком вместе с промптом. Команда мобильного приложения для финтех-стартапа, 5 разработчиков, двухнедельные спринты. Sprint 23 – шестой день из десяти.
Полный пример выгрузки лежит отдельным файлом: скачать sprint-23-export.txt – вставьте его в чат сразу после промпта (или прикрепите файлом). Шаблон легко адаптируется под ваш проект: замените имена, ID задач и статусы. Ниже – тот же набор данных, встроенный в промпт целиком, чтобы пример был воспроизводим прямо из статьи.
Структура, которую я видел в десятках реальных проектов. Sandbox-доступ от банка, который «будет завтра» уже пятый день. Макеты от дизайнера, которые «почти готовы». CEO, который «просто попросил одну табличку». Каждый из этих элементов по отдельности – мелочь. Вместе – срыв спринта.
Агент видит это за 30 секунд. PM видит это на ретроспективе, когда спринт уже закончился. Это, кстати, меняет и распределение ответственности в команде: когда PM приходит с конкретными данными, а не ощущениями, разговор о приоритетах становится принципиально другим.
Промпты выше выглядят прямолинейно. Сложность начинается, когда нужно понять, где агент посчитал правильно, а где подставил правдоподобную цифру. Прочитать прогноз агента – минута. Понять, можно ли ему верить, – навык, который нарабатывается практикой.
Прочитать прогноз агента – минута. Понять, где он подставил правдоподобную цифру вместо правильной – навык, который не появляется от чтения статей. В открытом модуле вы тренируете его на 9 задачах с реальными данными: выгрузки, промпты, ловушки. Бесплатно, без регистрации.
Доступ сразу после регистрации
Red flags vs. false positives – когда агент кричит «волк»
Каждый из пяти сигналов может врать. Вот конкретные ситуации, когда отклонение от нормы – это план команды, который агент не видит без контекста.
Праздничная неделя
Velocity падает, коммитов меньше, задачи закрываются позже. Агент видит падение и бьёт тревогу. Решение простое: добавьте в контекст промпта строку «В этом спринте 3 рабочих дня из-за праздников, нормализуй метрики». Одна строка контекста – и ложного срабатывания нет.
Технический долг-спринт
Команда сознательно взяла меньше задач, чтобы разобраться с рефакторингом. Velocity низкий, разрастания содержания нет, объём изменений в коммитах высокий. Без контекста агент поднимет тревогу. С контекстом – всё по плану.
Онбординг или spike-исследование
Два случая, которые выглядят на графике одинаково, а на деле разные. Новый разработчик вызывает просадку velocity на 2–4 спринта – это нормальная инвестиция в рост, и агент должен знать: «Елена вышла на проект в Sprint 22, ожидаемое освоение – 3 спринта». Исследовательская задача (spike) даёт ту же картину – мало коммитов, мало закрытых тикетов, много времени в одном – но по сути это разведка технологии, а не блокировка. Без контекста агент бьёт тревогу в обоих случаях.
Согласованное изменение содержания
Самый неочевидный случай. PO добавил три задачи в спринт по договорённости с командой, которая в обмен убрала задачи аналогичного объёма. Формально разрастание содержания высокое – 25% от планового объёма добавлено в середине спринта. Реальной проблемы нет: пропускная способность сохранена, цель спринта осталась прежней, просто содержание обменяли на эквивалент. Если PM не передал агенту эту договорённость, отчёт будет с ложной тревогой. Решение: в контекст промпта добавляется одна строка – «Обмен в середине спринта: добавлены FIN-415, 416, 417 (8 SP), убраны FIN-409, 413 (8 SP), согласовано с PO». Этого достаточно.
Общее правило: агент считает числа, PM понимает контекст. Вопрос не в том, доверять ли агенту. Вопрос в том, передали ли вы ему контекст, без которого нельзя отличить праздничную неделю от системного замедления. Автоматический алерт полезен меньше, чем структурированный вопрос: «Вот что я вижу в данных. Это проблема или нет?»
Что делать, если данных нет (или им нельзя верить)
Всё сказанное выше предполагает, что у вас есть нормально заполненный трекер. Это заставляет задуматься: для значительной части команд это не так. Статусы не обновляются, story points не ставятся, задачи добавляются в трекер постфактум или не добавляются вовсе. Трекер превращается в дорогой список дел.
Трекер без данных – это смена источника, а не конец аналитики. Меняется и роль агента. С нормальным трекером агент считает тренды по числам. Без трекера человек становится сенсором, а агент – долговременной памятью и распознавателем паттернов в свободном тексте. Люди плохо помнят, что «почти готово» произносится четвёртую неделю подряд, или что у одного разработчика число сообщений в чате упало вдвое за две недели. Агент с этим справляется без усилий.
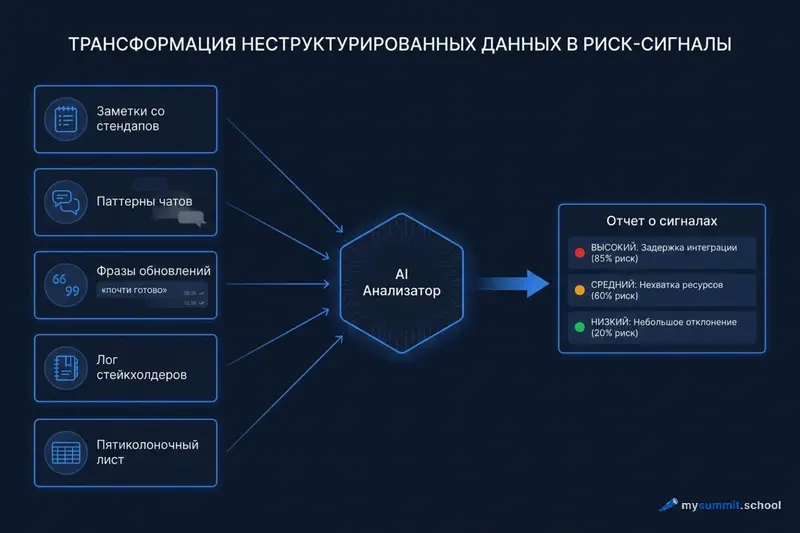
Стендап как источник сигналов
Кто третий день подряд говорит «вчера то же, что позавчера». Кто перестал называть конкретные тикеты и переходит на «дорабатываю прошлое». Кто впервые за месяц молчит. Это наблюдаемые данные – они не требуют трекера. Один промпт после стендапа: скопируйте свои заметки за пять дней стендапов в свободном тексте и попросите агента найти повторяющиеся блокеры и людей, которые буксуют дольше двух дней. Агент справится с нестрогим форматом.
Тишина в каналах и календарях
Резкое падение активности в Slack, Teams или Mattermost. PR-обсуждения сжимаются до «LGTM» (looks good to me – формальное одобрение без обсуждения). Разработчик, который обычно отвечает за час, отвечает через день. То, что PM ощущает как «что-то стихло», агент превращает в конкретное «у Дмитрия 8 сообщений за неделю против 24 в прошлой». Копипаст истории канала за две недели плюс одна просьба: посчитать сообщения по людям и дням, найти провалы активности, оценить, как изменилась длина обсуждений в PR. Обратный сигнал: календарь PM внезапно забит внеплановые встречами с CTO. Это сигнал про проект, не про команду.
Язык апдейтов
«Почти готово», сказанное три недели подряд – математически невозможная ситуация. «Финализируем» часто означает, что финализация не начата. «Последние штрихи» неделю подряд означают, что есть проблема, о которой не говорят вслух. Скопируйте последние пять-десять апдейтов от команды в чат с агентом и попросите найти повторяющиеся формулировки и оценить, насколько «90% готово» смещается во времени. Это займёт две минуты и часто называет вещи своими именами.
Поведение заинтересованных сторон как опережающий индикатор
CEO внезапно стал заходить в проектный чат. Заказчик прислал три внеплановые запроса за неделю вместо обычного одного раз в две недели. PO молчит на планировании. Реакция заинтересованных сторон часто опережает то, что показывают данные трекера, – они чувствуют тревожность ещё до того, как velocity упал на 15%. PM, который ведёт хотя бы короткий журнал контактов (одна строка в неделю на человека), отдаёт его агенту вместе с данными за прошлые месяцы и получает в ответ: «частота запросов от заказчика выросла в три раза, новые участники в чате – два, тон вопросов сместился от уточнений к проверкам». Сам по себе журнал ничего не стоит. С агентом он становится системой раннего предупреждения.
Если нет ничего – заведите пять колонок
Google Sheets, Excel, заметка в телефоне – неважно. Колонки: задача, кто делает, начато (дата), статус на сегодня (одно слово), блокер если есть. Заполнение – десять минут раз в день после стендапа. Через две недели у вас есть данные, которые скармливаются в любой из промптов выше без изменений.
Google Sheets – не Jira. Но этого достаточно, чтобы увидеть, кто буксует пятый день подряд и какие задачи живут дольше остальных. Не нужно сразу выстраивать дисциплину всей команды – достаточно начать с собственной.
Пять описанных источников склеиваются в один промпт. Промпт ниже работает на свободном тексте – никаких CSV, никаких выгрузок, всё копируется руками за десять минут.
Главный принцип здесь – регулярность взгляда, а не объём данных. Пять колонок раз в день обыгрывают идеально настроенный Jira, в который никто не смотрит. Одна оговорка: качество анализа зависит от модели. DeepSeek, Qwen и Gemini стабильно находят все пять сигналов в свободном тексте. Модели послабее (включая некоторые локальные) могут пропустить неочевидные паттерны – например, не заметить, что «почти готово» повторяется четвёртый день подряд, или оценить визит CEO в проектный чат как норму. Если ваша модель выдаёт общие советы вместо конкретных имён и дат – попробуйте другую.
Интеграция с P5.express – сигналы, которые поднимаются на уровень портфеля
Если вы работаете с P5.express и агентным ИИ, эти пять сигналов – именно то, что питает Z1-цикл ежедневного мониторинга. Когда агент обнаруживает velocity decay в двух проектах одновременно – это паттерн, который должен попасть в Общий реестр последующих действий.
А ежемесячная оценка проектов (Y2) становится точнее, когда вместо ручного сбора данных PM приходит с готовым анализом по каждому из пяти сигналов. Вместо «прогресс 50%» – «прогресс 50%, но темп команды упал на 15% за 2 спринта, разрастание содержания 45%, два критических блокера с цепочкой зависимостей на 3 задачи». Разговор переходит от описания к прогнозу.
В ритме проекта эти сигналы ложатся в еженедельный цикл: пятничная выгрузка -> анализ агентом -> понедельничное планирование с учётом рисков. Час раз в неделю – столько уходит на то, чтобы PM приходил на планирование с аргументами вместо ощущений.
Ловушка арифметики
Те же грабли, что в анализе P5.express: агент уверенно считает, но иногда считает неправильно. Monte Carlo-симуляцию он проведёт – но может использовать равномерное распределение вместо нормального, забыть учесть выходные в расчёте дней или посчитать velocity как сумму, а не среднее. Конкретный пример: в промпте про velocity одна из моделей рассчитала, через сколько спринтов velocity упадёт ниже 25 SP – но за точку отсчёта взяла среднее за полгода (39,5), а не текущее значение (28). Результат: «5 спринтов до порога» вместо реальных одного-двух. Формула выглядела безупречно, ошибка была в исходной посылке.
Правило: проверяйте любое число, которое влияет на решение. Почему модель взяла именно это распределение? Откуда точка отсчёта? Какие спринты попали в выборку? Исследование паттернов поверхностного внедрения показывает, что именно некритичное принятие AI-выводов – главная причина, по которой инструмент остаётся игрушкой, а не рабочим инструментом. Прогноз «закроем 28 SP из 34» звучит точно – но за ним может стоять ошибка в формуле. Агент – черновик для проверки, не оракул.
Специфическая ловушка для финансовых данных: если в выгрузке из Jira story points записаны как текст (а не число), агент может их проигнорировать или посчитать как 0. Всегда проверяйте, что агент увидел те же данные, которые вы загрузили.
Вы только что видели, как модель взяла среднее за полгода вместо текущего значения и предсказала 5 спринтов вместо двух. Три из 9 задач открытого модуля – именно про это: вы практикуетесь ловить ошибки, которые выглядят правильно. Бесплатно, без регистрации.
Доступ сразу после регистрации
Агент vs. специализированные инструменты
На рынке есть инструменты, которые делают всё это автоматически: LinearB, Jellyfish, Swarmia, Pluralsight Flow, Apache DevLake. Они интегрируются с Jira и GitHub по API, строят дашборды, шлют алерты.
Честное сравнение:
| Агент (ChatGPT / Claude / Kimi) | Специализированный инструмент | |
|---|---|---|
| Стоимость | $0–20/мес | $30–100/мес за разработчика |
| Настройка | 0 минут | Дни–недели |
| Данные | Ручная выгрузка | Автоматическая интеграция |
| Real-time алерты | Нет | Да |
| Кросс-командная аналитика | Ограничена контекстом | Полная |
| Глубина git-аналитики | Метаданные | Полная (включая code churn, PR review bottlenecks) |
| Точность прогноза | ~70% (оценка LinearB для аналогичных метрик) | 70–80% |
Исследования LinearB на реальных командах показывают: агент – хороший первый шаг. Для одной команды из 5–7 человек еженедельная выгрузка и промпт закрывают 70–80% того, что дают платные инструменты. Если нужно обосновать переход на платный инструмент руководству – разбор ROI даст нужные аргументы. Разница в мгновенных оповещениях и автоматической интеграции имеет значение, когда у вас 5+ команд и нужен постоянный мониторинг.
Для команды финтех-стартапа из примера выше – агент достаточен. Для портфеля из 15 проектов – стоит смотреть на DevLake (open source) или LinearB.
Что попробовать на этой неделе
Начните с velocity. В Jira: Board -> Reports -> Velocity Chart, скопируйте числа за 4–6 спринтов. В Asana или Bitrix – соберите вручную, там пять строчек. Скопируйте промпт «Анализ velocity-тренда» из этой статьи, подставьте свои числа, отправьте в ChatGPT или DeepSeek. Семь минут суммарно.
Потом – один взгляд на текущий спринт: есть задачи в «In Progress» дольше пяти дней? Не пытайтесь сразу всё посчитать. Просто добавьте их в промпт «Анализ заблокированных задач» и посмотрите, что скажет агент. Часто он называет вслух то, что PM уже знал, но не формулировал.
Если агент нашёл хотя бы один реальный сигнал, которого вы не видели – поздравляю, у вас работает предиктивная аналитика. Без платных инструментов, без интеграций, без дашбордов. Если не нашёл ничего нового – значит, у вас хорошая видимость. Тоже полезно знать.
Воспроизводимый процесс – пятничная выгрузка, анализ, корректировка в понедельник – описан подробнее в отдельной статье про ритм проекта. А если вы хотите, чтобы агент не просто анализировал выгрузку, а сам читал файлы и запускался по расписанию – посмотрите кейс с агентным анализом данных.
Удивительно, но главный результат предиктивной аналитики – качество разговора. PM приходит на планирование не с ощущением «что-то идёт не так», а с конкретным вопросом: «темп падает третий спринт, разрастание содержания растёт, два блокера с цепочкой на три задачи – что будем делать?» Первый разговор заканчивается эскалацией. Второй – решением.
От промптов к пайплайну
Статья дала промпты, которые вы вставляете вручную раз в неделю. Курс строит систему: MCP-интеграция с трекером, агенты, которые запускаются по расписанию, и еженедельный отчёт, который собирается без вас. Три главы – от стресс-теста плана до автоматизации полного цикла.

Часто задаваемые вопросы
Что такое velocity decay и почему он опасен?
Какие AI-инструменты работают без VPN для российских PM?
Чем AI-агент отличается от LinearB, Jellyfish или Swarmia?
Какие данные нужно выгружать из Yandex Tracker, Kaiten или Jira?
Что делать, если статусы в трекере не обновляются и данным нельзя верить?
Почему AI иногда уверенно считает неправильно, и как это распознать?

Stanislav Belyaev
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.