Промпты 2026: почему AI теряет 30% данных в середине – 3 техники + таблица

Вы отправили AI промпт с техническим заданием на 5000 слов. В середине документа было критичное ограничение: «Бюджет не должен превышать $50,000». AI прочитал начало, прочитал конец – и пропустил бюджетное ограничение. Результат: план проекта на $150,000.
Это не галлюцинация. Это архитектурная особенность нейросетей.
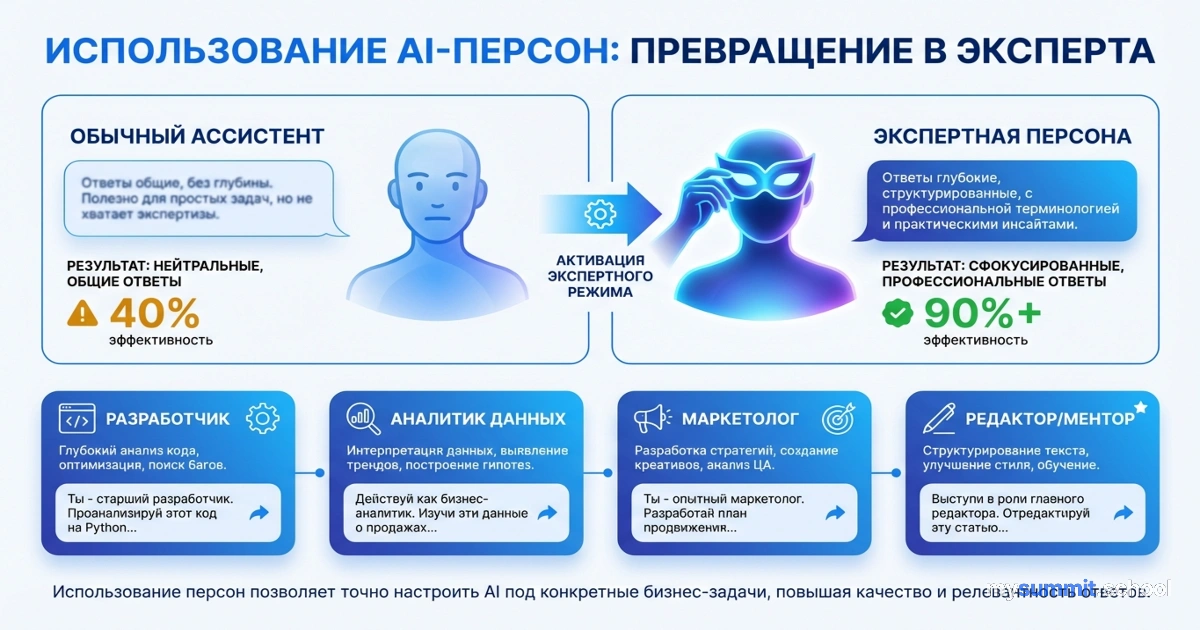
Это третья статья из серии «Промпт-инжиниринг для начинающих». В первой мы разобрали структуру промпта, во второй – персону. Сегодня – размер и позиционирование информации.
Исследование «Lost in the Middle»
В 2023 году исследователи из Стенфорда, Беркли и UC San Diego провели эксперимент, который изменил понимание работы с длинными контекстами.
Они обнаружили U-образную кривую точности:
- Модели отлично работают с информацией в начале промпта (primacy bias)
- Модели отлично работают с информацией в конце (recency bias)
- Точность резко падает для данных в середине
Даже Claude с контекстом 200 000 токенов и Gemini с 2 000 000 токенов подвержены этому эффекту при решении сложных задач.
Почему это критично для менеджера
Представьте реальные ситуации:
- Анализ резюме: AI пропускает важный навык, указанный в середине CV
- Техническое задание: Критичное ограничение теряется среди требований
- Финансовый отчёт: Ключевой показатель в середине таблицы игнорируется
Это не баг – это особенность механизма внимания (Attention) в Transformer-моделях.
Безопасные размеры промптов
Для инструкций (System Prompt)
| Модель | Идеальный размер | Максимум без потерь |
|---|---|---|
| Claude, GPT-4o | 500–1500 токенов | ~2000 токенов |
| Haiku, YandexGPT Lite | 300–800 токенов | ~1000 токенов |
Что происходит при превышении: После 2000 токенов инструкций модели начинают «забывать» первые правила, приоритизируя последние. Это называется «инструкционная интерференция».
Для общего контекста
| Зона | Размер | Точность |
|---|---|---|
| Safe Zone | До 32 000 токенов (~40 стр.) | 95–100% |
| Efficiency Zone | 32–128 000 токенов (~160 стр.) | 85–95% |
| Danger Zone | 250 000+ токенов (~300+ стр.) | 70–80% |
Не путайте размер контекстного окна (сколько токенов модель может прочитать) с эффективным использованием (сколько она реально обрабатывает с высокой точностью).
Три техники для длинных промптов
1. Принцип «Сэндвич»
Размещайте важные инструкции до и после данных.
[Вступление: роль и глобальная задача – 200 токенов]
[Данные: финансовый отчёт – 20 000 токенов]
[Финальная инструкция: алгоритм и формат вывода – 500 токенов]
Почему работает:
- Вступление активирует нужный «режим» модели
- Данные находятся в середине (где точность ниже, но это просто сырая информация)
- Финальная инструкция использует recency bias – модель лучше всего помнит последнее
2. Prompt Chaining (Цепочка промптов)
Вместо одного промпта на 50 000 токенов – 5 промптов по 10 000.
Пример: Анализ 50 резюме
❌ Один промпт со всеми резюме → AI пропустит информацию о кандидатах 20–30
✅ 5 промптов по 10 резюме → Каждый промпт в Safe Zone, ничего не теряется
Бонус: Между промптами можно добавить промежуточные выводы. После первых 10 резюме попросите AI выявить паттерны, затем используйте их для анализа следующих.
3. Якорные точки
Если длинный промпт неизбежен – повторяйте ключевую инструкцию каждые 5–10 тысяч токенов.
[Инструкция: "Ищи финансовые аномалии"] [Данные Q1 – 10 000 токенов] [Напоминание: "Помни: фокус на финансовых аномалиях"] [Данные Q2 – 10 000 токенов] [Напоминание: "Помни: фокус на финансовых аномалиях"] [Данные Q3 – 10 000 токенов] [Финальная инструкция]
Вы «перезагружаете» внимание модели, не давая ей забыть о задаче.
Many-Shot Learning: альтернатива длинным инструкциям
Иногда вместо длинных текстовых описаний эффективнее показать 15–25 примеров.
Преимущества:
- Каждый пример – самодостаточный блок
- Даже если модель «потеряет» примеры 8–12 в середине, она увидит паттерн из примеров 1–7 и 13–20
- Модель копирует ваш формат точно, не «изобретая» свой
Когда использовать: Для задач с чётким форматом вывода (анализ отзывов, классификация тикетов, генерация отчётов).
Ключевые выводы
«Lost in the Middle» – не баг, а особенность архитектуры. Планируйте структуру промпта с учётом этого.
Размер контекстного окна ≠ эффективный контекст. Gemini может обрабатывать 2 млн токенов, но точность падает задолго до этого предела.
Инструкции – в начале и в конце. Данные – в середине.
Цепочка коротких промптов лучше одного длинного. Меньше потерь, больше контроля.
Якорные точки для неизбежно длинных промптов. Повторяйте ключевую задачу каждые 5–10 тысяч токенов.
Что дальше
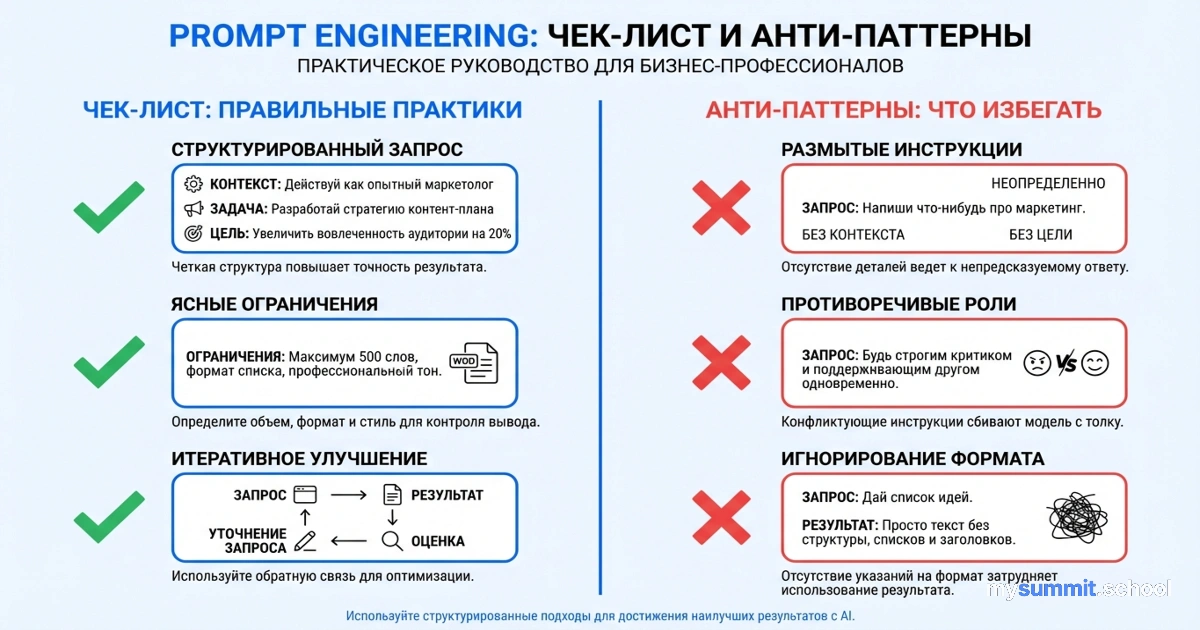
В финальной статье серии мы соберём всё вместе: чек-лист для создания промптов, типичные антипаттерны и практические рекомендации.
Практика
На mysummit.school/prompts вы можете экспериментировать с разными размерами промптов и техниками структурирования. Проверьте, как меняется качество ответа при перемещении ключевой информации.
Научитесь работать с длинными документами
Полная программа курса: от базовых техник промптинга до продвинутой работы с объёмными документами, анализом данных и AI-агентами. Foundation + специализации.