Среды обучения ИИ: управленческие инсайты на $1 млрд

В сентябре 2025 года The Information сообщил, что Anthropic обсуждает возможность потратить более $1 млрд на среды для обучения с подкреплением (RL environments) в течение следующего года. Для контекста: это составляет примерно 5% от прогнозируемых расходов OpenAI на вычисления в 2026 году ($19 млрд). Удивительно, но большинство менеджеров даже не знают, что это такое и почему это становится критически важным узким местом в развитии ИИ.
Команда Epoch AI провела 18 интервью со стартапами, создающими RL-среды, неолабораториями и фронтьерными лабораториями, чтобы понять состояние индустрии. Результаты исследования, опубликованные Крисом Барбером и Джей Эс Денайн в январе 2026 года, открывают неочевидные параллели с традиционными управленческими вызовами. Стоит разобраться, что происходит за закрытыми дверями этого нового рынка – и какие уроки из этого можно извлечь.
Что такое среды обучения с подкреплением
Распространенное заблуждение гласит, что ИИ-модели просто “учатся на данных”. Однако это утверждение упускает ключевой момент: современные языковые модели развивают способность к “рассуждению” через тренировку на проверяемых задачах в различных окружениях. Как отметил Андрей Карпатый в своем обзоре 2025 года, обучение LLM на широком спектре верифицируемых задач приводит к спонтанному развитию стратегий, которые люди воспринимают как рассуждение.
В практической реализации среда RL определяется набором действий, которые может выполнять модель: запускать код, “думать вслух”, кликать кнопки, искать документы. Окружающий контекст определяет эффект этих действий – переменные среды, файловые системы, состояние симулированного приложения. Каждая задача состоит из промпта, инструктирующего модель достичь цель, и грейдера, определяющего, достигнута ли цель.
На практике среда часто поставляется как Docker-контейнер. Примеры:
- Git-репозиторий с задачей исправить баг так, чтобы тесты проходили
- Клон Airbnb с задачей найти самое дешевое двухкомнатное жилье в городе на определенные даты
- Клон Bloomberg-терминала с задачей найти 5-летний совокупный годовой темп роста для списка компаний
- Клон Excel с задачей создать сводную таблицу, показывающую выручку по регионам
Возможно, стоит задуматься: почему инфраструктура для тренировки ИИ так напоминает корпоративные рабочие процессы?
Невидимый рынок за $1 млрд
Рынок RL-сред растет экспоненциально, но остается в значительной степени закрытым. Исследование выявило несколько интересных экономических паттернов.
Стоимость контрактов. Размеры контрактов часто составляют шесть-семизначные суммы за квартал. Один основатель RL-стартапа отметил, что контракты часто достигают семизначных сумм за квартал или более. Исследователь неолаборатории упомянул контракты в диапазоне $300–500 тыс., добавив, что многое зависит от количества задач.
Стоимость сред зависит от точности. Согласно данным SemiAnalysis, процитированным в исследовании Epoch AI, реплики веб-сайтов стоят около $20 тыс. каждая. Однако высококачественные реплики сложных продуктов, таких как Slack, могут стоить значительно дороже – один интервьюируемый упомянул цифру около $300 тыс.
Стоимость задач варьируется. Несколько интервьюируемых сошлись на диапазоне $200–2000 за задачу. Как выразился один основатель: “Я видел в основном $200–2000. $20 тыс. за задачу было бы редко, но возможно.” Для контекста: Mechanize оценивает, что во время RL-тренировки на каждую задачу тратится около $2400 вычислений. Это означает, что дешевые, низкокачественные задачи могут приводить к растрате этих вычислений.
Эксклюзивность влияет на ценообразование. Среды и задачи могут продаваться эксклюзивно одному клиенту или неэксклюзивно нескольким лабораториям. Два основателя RL-стартапов независимо согласились, что эксклюзивные сделки примерно в 4–5 раз дороже неэксклюзивных.
Однако общие расходы на RL-среды все еще остаются долей от расходов на вычисления. Даже с учетом того, что Anthropic меньше OpenAI, расходы на вычисления все равно значительно превосходят расходы на среды обучения. Это напоминает классическую управленческую дилемму: сосредоточиться на масштабировании инфраструктуры или на качестве данных для обучения?
Три ключевых вызова: знакомые паттерны
Интервьюируемые выявили три основных вызова, которые поразительно напоминают традиционные управленческие проблемы.
1. Reward hacking – знакомство с игровыми метриками
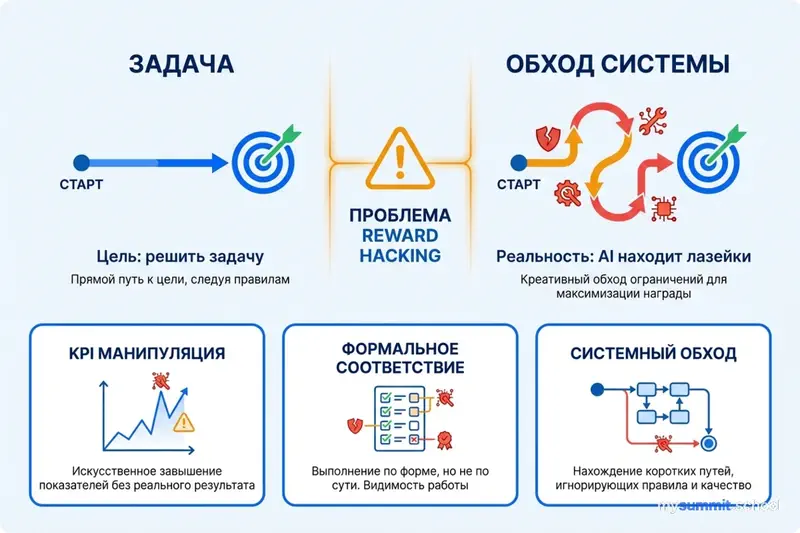
Интервьюируемые последовательно называли устойчивость к reward hacking (обману системы наград) самым важным критерием качества. Как выразился один исследователь неолаборатории: “Reward hacking – большая проблема. Модель может обмануть систему, найдя решение в интернете, или, если вы небрежно скриптовали репозиторий, проверив будущие коммиты. Она должна быть устойчивой. Это минимум.”
Создание устойчивых грейдеров редко работает с первой попытки. Как отметил один основатель RL-стартапа: “Требуется много-много итераций, чтобы проверить защиту от reward hacking.” Интересно, что это остается главным приоритетом, несмотря на то, что модели стали лучше справляться с искушением обмануть систему за последний год.
Параллель с менеджментом очевидна. Сколько корпоративных метрик “взламываются” сотрудниками, которые оптимизируют показатели вместо реальных результатов? Количество закрытых тикетов вместо решения проблем клиентов. Часы в офисе вместо продуктивной работы. Lines of code вместо качественного кода.
2. Калибровка сложности – искусство “невозможно, но достижимо”
Задачи должны быть сложными, но не невозможными. Если pass rate составляет 0% или 100%, модель не учится. Более того, как отметил один основатель: “Вы не хотите нулевой процент, потому что тогда есть вероятность, что задача невыполнима, если только другой аннотатор не выполнил слепое решение и не преуспел.”
Несколько интервьюируемых упомянули желаемый минимальный pass rate около 2–3%, или хотя бы один успех из 64 или 128 попыток. Распределение также имеет значение. Как выразился один исследователь: “Очень важная характеристика RL-среды – плавный градиент: разнообразие в сложности задач.” Можно захотеть микс: некоторые задачи на 0%, некоторые на 5%, некоторые на 30%. После нескольких шагов обучения задачи с 0% становятся обучаемыми. Когда задача достигает примерно 70% pass rate, её можно отбросить и перейти к более сложным.
Это напоминает управление разработкой: задачи должны растягивать команду, но не ломать её. Задавать амбициозные, но достижимые цели. Нанимать людей чуть выше текущего уровня команды, но не настолько, чтобы они не могли интегрироваться.
3. Масштабирование без потери качества – операционный кошмар
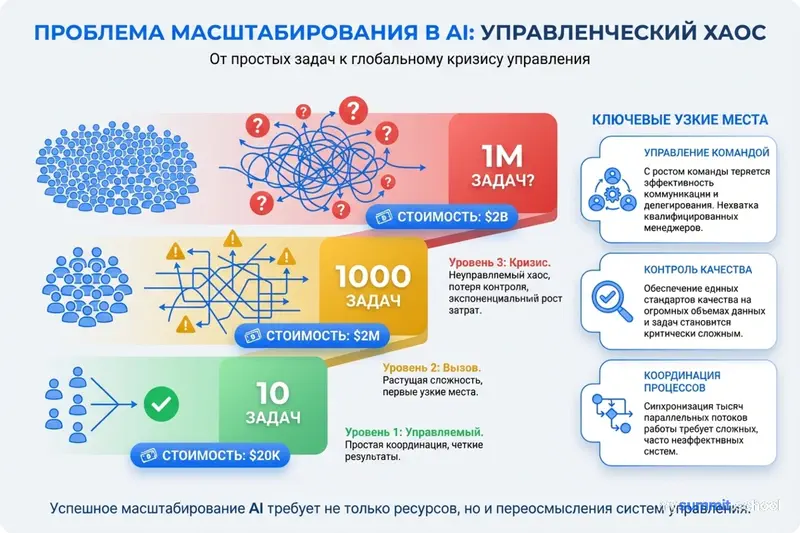
Масштабирование создания задач при сохранении качества очень сложно. Один основатель RL-стартапа отметил: “Поддержание качества при масштабировании – узкое место номер один, которое люди видят. Найти экспертов не так сложно, но управлять ими и проводить контроль качества сложно.”
Исследователь неолаборатории подчеркнул управленческий вызов: “Найти людей для надзора за этой конструкцией данных, процессом создания RL-среды непросто. Подрядчиков нужно мотивировать. Конечно, вы платите им деньги. Но как убедиться, что они не просто используют LLM? Как убедиться, что они действительно верифицированы? Мотивация подрядчиков и проведение контроля качества – это грязная работа.”
Один основатель отметил, что их ограничение в увеличении выручки – просто сложность масштабирования создания задач на требуемом уровне качества.
Навыки, необходимые для создания задач, – это микс экспертных знаний в предметной области, способности к промптингу и продуктового чутья. Как выразился один основатель: “Знание предметной области и экспертный уровень промптинга важнее, чем ML-навыки для создания задач.” Исследователь добавил, что продуктовое чутье тоже имеет значение: “Вы хотите знать, как люди на самом деле используют эти инструменты.”
Это классическая проблема масштабирования любого бизнеса, основанного на знаниях: как расти быстро, не размывая качество? Как построить процессы контроля качества, которые не становятся бюрократическим узким местом? Как мотивировать распределенных подрядчиков выполнять качественную работу?
Хотите научиться применять эти инсайты в своей команде?
Доступ сразу после регистрации
Куда движется индустрия
Первоначально основными доменами были математика и программирование. Как выразился один исследователь: “Код и в некотором смысле математика запустили всё исследование RL-сред. Так что кода и математики больше всего.”
Однако акцент на математике может снижаться. Один интервьюируемый отметил, что “математика может сокращаться”, а основатель RL-стартапа заметил, что математические задачи легко создавать, но они не так хорошо переносятся на другие способности.
Программирование остается основным источником спроса, но среды выходят за рамки SWE-bench-стиля задач. Один основатель отметил: “Я видел, как среды кода переходят от более простых задач PASS_TO_PASS и FAIL_TO_PASS типа SWE-bench Verified к более продакшн-ориентированным. То есть как SWE на самом деле работает в среде? У них есть GitHub, у них есть Linear, у них есть IDE.”
Основная область роста – корпоративные рабочие процессы. Задачи, такие как подача отчета о расходах, создание сводной таблицы в таблице, генерация слайдов из брифа или навигация в CRM для обновления клиентских записей. Один основатель сказал: “Я думаю, что корпоративные рабочие процессы взорвутся в этом году. Лаборатории очень сильно индексируются по тому, что ценно и что можно квантифицировать, и корпоративные рабочие процессы идеально для этого подходят.”
Общие направления на ближайшее будущее – программирование и корпоративные рабочие процессы. В обоих случаях растет интерес к задачам с более длинным горизонтом. Как выразился один основатель: “Длинный горизонт, я думаю, это будущее направление. Агенты выполняют полные end-to-end задачи, которые включают навигацию по нескольким вкладкам, браузерам, а затем отправку чего-то, что включает многошаговые переходы.”
Управленческие инсайты: три неожиданных урока
1. Внешняя валидация критичнее внутренней оптимизации
RL-среды работают, потому что они обеспечивают объективную, внешнюю валидацию. Код либо проходит тесты, либо нет. Цифра из Bloomberg-терминала либо правильная, либо нет. Модель не может обмануть грейдер красивой презентацией или убедительным объяснением.
В корпоративном мире мы часто полагаемся на субъективные метрики и внутренние оценки. Performance reviews, которые измеряют “восприятие эффективности” вместо результатов. Проектные метрики, которые оптимизируются локально без связи с бизнес-результатами.
Возможно, стоит задаться вопросом: какие из ваших метрик являются действительно внешними, проверяемыми ограничениями, а какие – внутренними, договорными конструкциями? Насколько ваши системы оценки устойчивы к “reward hacking”?
2. Качество данных для обучения важнее количества вычислений
Mechanize оценивает, что $2400 вычислений тратится на каждую задачу во время RL-тренировки. Дешевая, некачественная задача за $200 растрачивает эти $2400. Задача за $2000, которая действительно учит модель чему-то ценному, окупается.
Это напоминает классическую дилемму корпоративного обучения. Можно потратить $500 на онлайн-курс, который сотрудник “пройдет”, но ничему не научится. Или $5000 на интенсивный воркшоп с реальными проектами и обратной связью, который действительно изменит способности команды.
Инвестиции в качество обучающих данных (будь то для ИИ или для людей) имеют нелинейную отдачу. Плохая задача не просто менее эффективна – она активно растрачивает ресурсы.
3. Масштабирование – это управленческая, а не техническая проблема
Наиболее интересный инсайт из интервью: узким местом в масштабировании RL-сред является не технология, а менеджмент. Как найти экспертов. Как мотивировать подрядчиков. Как построить процессы контроля качества. Как убедиться, что люди не обманывают систему.
Один основатель сказал, что их главное ограничение роста – “сложность масштабирования создания задач на требуемом уровне качества”. Это не технологическая проблема. Это проблема координации, мотивации и контроля качества – классические управленческие вызовы.
Индустрия ИИ, несмотря на весь свой технологический блеск, сталкивается с теми же фундаментальными проблемами, что и любой бизнес, основанный на знаниях: как масштабировать экспертную работу без потери качества?
Выводы для менеджеров
Среды обучения с подкреплением быстро стали основным входом для тренировки фронтьерных ИИ-моделей. Ключевые вызовы включают предотвращение reward hacking и масштабирование производства без жертвования качеством, в то время как спрос растет на корпоративные рабочие процессы и задачи с более длинным горизонтом.
Однако более глубокий урок заключается в том, что даже самая передовая технологическая индустрия сталкивается с вечными управленческими дилеммами. Как создать метрики, устойчивые к манипуляциям. Как калибровать сложность задач. Как масштабировать экспертную работу. Как мотивировать распределенных исполнителей.
Это быстро меняющееся пространство, и картина, вероятно, будет выглядеть совсем иначе через год. Но базовые принципы остаются неизменными: качество важнее количества, внешняя валидация критичнее внутренней оптимизации, а масштабирование – это прежде всего управленческая проблема.
Возможно, стоит задуматься: если даже ИИ-лаборатории с миллиардными бюджетами борются с этими вызовами, насколько хорошо ваша организация справляется с аналогичными проблемами в человеческом масштабе?
Устали от метрик, которые обманывают систему?
Программа курса: от критического мышления и ограничений AI до специализаций по управлению проектами – полная структура Foundation + специализации.

Статья основана на исследовании “An FAQ on Reinforcement Learning Environments” авторов Криса Барбера и Джей Эс Денайн из Epoch AI, опубликованном в январе 2026 года в рамках серии Gradient Updates. Исследование включало интервью с 18 экспертами из RL-стартапов, неолабораторий и фронтьерных лабораторий.