SMM на автопилоте с AI: как мы провалились в Threads за 3 недели
Привет! Мы – команда mysummit.school, и мы, как и многие в сфере EdTech, одержимы идеей использования AI во всем. Недавно мы оживили аккаунт в Threads и поставили себе амбициозную цель: построить сильный бренд в нише AI/GenAI, не потратив на это ни минуты человеческого времени.
Спойлер: ничего не вышло. Но мы получили бесценный опыт, которым хотим поделиться. Эта история – о наших ошибках, неверных гипотезах и о том, как за красивыми метриками может скрываться полный провал.
Наша цель: бренд через охват, а не подписчиков
С самого начала мы поставили себе четкую цель: построить узнаваемый бренд в нише AI/GenAI через максимальный охват. Нас интересовали не подписчики (это оказалось ошибочным предположением, о чем позже), а просмотры – количество людей, которые видят наш контент.
Логика была простой:
- Цель: Охватить тысячи людей, интересующихся AI
- Метрика успеха: Средние просмотры на пост (целевое значение: 150-200+)
- Философия: Качественный контент найдет свою аудиторию, подписчики придут сами
- Ошибка: Мы недооценили важность вовлеченности и построения сообщества
Мы хотели использовать преимущественно AI-генерированный контент, но не бездумный спам. Наш подход был таким:
- Источники: Мы собирали факты вручную из качественных источников – подкастов ведущих экспертов (Lex Fridman, Andrew Ng, AI-подкасты на русском), YouTube-видео, технических конференций
- Предобработка: Каждый факт проходил через специализированный промпт для извлечения и оценки
- Оценка качества: Факты получали оценку от 1 до 10 по нескольким критериям
- Генерация постов: AI превращал факты в посты, адаптированные под русскоязычную аудиторию
Технические детали: как работала наша система
Архитектура решения
Backend: .NET 9 / C# – надежная, быстрая платформа для автоматизации База данных: PostgreSQL – хранение фактов, постов, метрик, истории вариантов AI-модели:
- Извлечение фактов: Claude 4.5 Sonnet (Anthropic) – лучшая модель для понимания контекста и извлечения структурированных данных из длинных текстов
- Генерация постов: Gamma 3 от Google – создание эмоционально окрашенных постов с учетом российской психологии (конкретика, прямота, эмоциональность)
- Оценка качества: Claude 4.5 Haiku (быстрая модель) – для быстрой оценки вариантов
Выбор Gamma был осознанным: эта модель показывает лучшие результаты в работе с русским языком и понимании культурного контекста. Особенно важна способность Gamma следовать сложным промптам с множеством критериев.
Процесс извлечения фактов
Мы разработали двухэтапный процесс обработки контента:
Этап 1: Ручной сбор источников
- Слушаем подкасты про AI (Lex Fridman, All-In Podcast, российские AI-подкасты)
- Смотрим выступления на конференциях (NeurIPS, OpenAI DevDay, Яндекс Scale)
- Читаем технические отчеты и исследования
Этап 2: Извлечение фактов через AI
Мы используем специализированный промпт (Не, мы его не шарим - он занимает больше, чем эта статья), который анализирует контент по 8 категориям эмоциональных триггеров:
- Fear + Specificity (Страх с конкретикой): «1.1М американцев потеряли работу за 10 месяцев, +65%»
- Status Threat (Угроза статусу): «OpenAI $588 млрд контрактов vs российский AI-бюджет $1 млрд. Разница в 588 раз»
- Shock + Contradiction (Шок и противоречие): «Все говорят ‘AI создаст места’, а реальность: 1.1М потеряли работу»
- Absurdity + Scale (Абсурдный масштаб): «Обучение модели: 2020 = $4.6М → 2024 = $100М+. Рост в 20x»
- Insider Reveal (Инсайдерская информация): «CoreWeave получит $0.15-0.20 чистой на каждый $1. Они скрывают масштабы»
- Loss Aversion + Countdown (Дефицит времени): «2-3 года осталось переучиться. После 2027 рынок не узнаете»
- Russian Companies (Российские компании): «Яндекс потратил $150М на GPU за 6 месяцев»
- Personal Story (Личные истории): «3 знакомых программиста потеряли работу за месяц. Все – AI»
Каждый факт получает:
- Оценку 1-10 (engagement_score)
- Категорию эмоционального триггера
- Анализ психологического воздействия
- Соответствие российской культуре (конкретика, прямота, эмоциональность, статус, противоречия)
Статистика эксперимента: Цифры
За время эксперимента наша система превратилась в настоящего монстра контента. Мы собрали 351 уникальный факт и опубликовали 216 постов. Из них 72% были созданы полностью автоматически – наш цифровой автор трудился без устали. Вручную было написано всего 60 постов. Средняя оценка качества извлеченных фактов держалась на уровне 7.9/10 – мы были уверены в качестве нашего сырья. Но, как вы увидите, этого оказалось недостаточно.
Вы можете запустить его и получить те же данные, которые мы здесь приводим.
| Метрика | Значение | Комментарий |
|---|---|---|
| Период эксперимента | 27.10.2025 – 19.11.2025 | Даты первого и последнего поста в анализируемом периоде. |
| Всего извлечено фактов | 351 | Общее количество уникальных фактов, извлеченных из подкастов и статей. |
| Средняя оценка факта | 7.9/10 | Средний “эмоциональный рейтинг” факта по нашей шкале от 1 до 10. |
| Всего опубликовано постов | 216 | Общее количество постов, появившихся в Threads. |
| AI-сгенерированные посты | 156 (72.2%) | Посты, созданные полностью автоматически, без участия человека. |
| Ручные/другие посты | 60 (27.8%) | Посты, написанные вручную, или те, что не были привязаны к фактам. |
Эволюция подхода:
- Фаза 1 (начало ноября): 10-13 постов/день, 100% автоматика
- Фаза 2 (середина ноября): Оптимизация промптов, смена алгоритмов выбора
- Фаза 3 (сейчас): 2-3 поста/день, ручная выборка вариантов
Акт 1: Медовый месяц. «Смотрите, оно работает!»
Идея была простой и гениальной (как нам казалось):
- Берем базу из сотен фактов про AI.
- Пишем AI-промпт, который превращает их в «глубокие, основанные на данных» посты.
- Запускаем бота, который постит это 8-13 раз в день.
- Profit!
Первые результаты обнадёживали. В начале ноября мы получали в среднем 134 просмотра на пост. Не виральный успех, но для полностью автоматического аккаунта – вполне достойно. Мы быстро выяснили, что лучше всего работают посты с эмоциональными крючками («Ребята, вы это слышали?!») и шокирующими цифрами.
Например, пост о сравнении пузыря доткомов с бумом AI собрал почти 600 просмотров. Успех!

Мы чувствовали себя гениями. Нужно было лишь немного докрутить промпты.
Акт 2: Первые трещины и shadowban. «Почему Threads нас не показывает?»
Мы создали новый «супер-промпт» для высокой вовлеченности. И он действительно работал! Посты, созданные с его помощью, получали в среднем на 68% больше просмотров.
Проблема? Мы использовали его всего в 15% случаев. Наша система работала вразнобой, и 8 ноября случился показательный провал: средние просмотры рухнули до 22.
Сначала мы думали, что это техническая ошибка – мол, «забыли включить хороший промпт». Но реальность оказалась куда хуже: Threads дал нам shadowban на 2 дня.

Что произошло: Мы неправильно интерпретировали алгоритмы Threads. Постили 10-13 раз в день в одно и то же время, с похожей структурой постов, без какой-либо реакции на комментарии. Платформа распознала паттерн автоматизации и тихо понизила наш охват до минимума.
Это был первый звонок, что наш подход фундаментально сломан. Но мы еще не готовы были это признать.
Хотите научиться эффективно использовать AI, не повторяя наших ошибок?
Доступ сразу после регистрации
В тот же период мы сделали ещё одно открытие: посты про российские тех-компании (Яндекс, Сбер) выстреливали в 3-5 раз лучше, чем про глобальные. Пост про покупку GPU Яндексом принес нам рекордные 1,412 просмотров.

Вывод казался очевидным: нужно использовать только лучший промпт и сосредоточиться на фактах о российском AI. Мы отключили все старые промпты и приготовились к взлёту.
Акт 3: Синдром уставшего зрителя. «Я это уже где-то видел»
Взлёта не случилось. Наоборот, началось стремительное падение. Средние просмотры упали до 39, а в один из дней – до катастрофических 5.7.
В чём дело? Мы стали жертвой «баннерной слепоты» собственного производства. 90% наших постов имели одну и ту же структуру:
- Крючок: «Ребята, вы это слышали?» / «Подождите, что?!»
- Данные: [шокирующие цифры]
- Вывод: «Это значит, что…»
- Вопрос: «А вы как думаете?»
Аудитория моментально распознавала этот паттерн и просто пролистывала. Наши посты-близнецы стали невидимыми.

Мы погрузились в анализ алгоритмов Threads и поняли: платформа наказывает за однотипный контент. Решение? Создать ещё более гениальный промпт с 8-ю разными структурами, списком «запрещенных фраз» и другими оптимизациями. Теперь-то точно полетим!
Акт 4: Настоящий виновник. «Двигатель сломан, а мы полируем сиденья»
Новый «алгоритм-оптимизированный» промпт был внедрен. Результат: средние просмотры обвалились до 19.5. Это был полный провал, на 93% ниже цели.
Наступил момент истины. Мы полезли в код и обнаружили нечто абсурдное. Наш сервис постинга выбирал факты для публикации по принципу: OrderByDescending(f => f.Id). Он просто брал самый новый факт из базы, полностью игнорируя его качество, категорию или рейтинг.
Мы потратили недели на создание системы оценки фактов, а наш бот всё это время её не использовал.
Это был шок. Мы тут же переписали алгоритм на умную, взвешенную выборку, оптимизировали время постинга под пиковые часы и перезапустили систему. Мы были уверены, что вот он, корень зла.
Акт 5: Крушение всех надежд и новое начало
И… ничего не изменилось. Даже с умной выборкой лучших фактов, в лучшее время, с лучшим промптом – просмотры остались на уровне 19-20.
Тут до нас дошло.
Проблема не в том, КАК мы генерируем контент. Проблема в том, что мы вообще пытаемся его генерировать полностью автоматически.
Наши 5 итераций оптимизации были похожи на попытку улучшить комфорт кресел в самолете с отказавшими двигателями. Система была сломана на фундаментальном уровне. Алгоритмы Threads умнее, чем мы думали. Они видят:
- Поведение бота: 10+ постов в день в одно и то же время? Спам.
- Отсутствие человека: Ноль ответов на комментарии? Нет вовлеченности, пессимизация.
- Стиль AI: Даже лучшие промпты выдают себя, если их много.
Те 3-4 виральных поста, что у нас были? Чистая удача. Случайность, которую невозможно воспроизвести с помощью автоматики.
Наша новая стратегия: человек + AI
Мы признали поражение в попытке полной автоматизации. Наш новый подход – гибридный:
- Снижаем частоту. Вместо 10-13 постов в день – 2-3 самых качественных.
- AI – ассистент, а не автор. Бот генерирует несколько вариантов поста на основе одного факта.
- Человек – куратор. Живой редактор выбирает лучший вариант, дорабатывает его и постит вручную.
- Вовлеченность – приоритет. Мы отвечаем на каждый комментарий, вступаем в диалоги.
Главные уроки
1. Метрика «просмотры» была неправильной целью
Мы гнались за просмотрами, игнорируя подписчиков и вовлеченность. Результат: тысячи просмотров, но никакого сообщества. Алгоритмы социальных сетей оптимизированы на вовлеченность, а не на пассивное потребление.
Правильно: Фокусироваться на подписчиках, комментариях, сохранениях. Качество аудитории > количество глаз.
2. «Социальные» сети не просто так называются социальными
Нельзя автоматизировать искреннее общение и экспертизу. Threads, Instagram, X – это платформы для людей, которые хотят взаимодействовать с людьми. AI может помочь, но не может заменить.
3. Алгоритмы платформ умнее промптов
Threads видит:
- Паттерны публикации (время, частота, интервалы)
- Поведенческие сигналы (ответы на комментарии, время создания поста)
- Стилистические маркеры AI-контента
- Вовлеченность аудитории (не просто просмотры, а действия)
Никакой промпт не обманет эти системы надолго.
4. AI как второй пилот, не автопилот
AI отлично подходит для:
- Извлечения фактов из длинных источников
- Генерации вариантов постов
- А/Б тестирования формулировок
- Оценки качества контента
AI плохо справляется с:
- Пониманием тонкостей аудитории в реальном времени
- Построением долгосрочной стратегии бренда
- Живым общением и реакциями на комментарии
- Чувством момента («сейчас этот пост зайдет»)
5. Техническое совершенство ≠ успех продукта
Мы построили красивую систему: .NET 9, PostgreSQL, Claude 4.5 Sonnet, многоуровневая оценка фактов, 8 эмоциональных триггеров, адаптация под российскую психологию.
И всё это не имело значения, потому что фундаментальная гипотеза была неверной.
Урок: Сначала проверяйте гипотезу на минимальном MVP, потом стройте инфраструктуру.
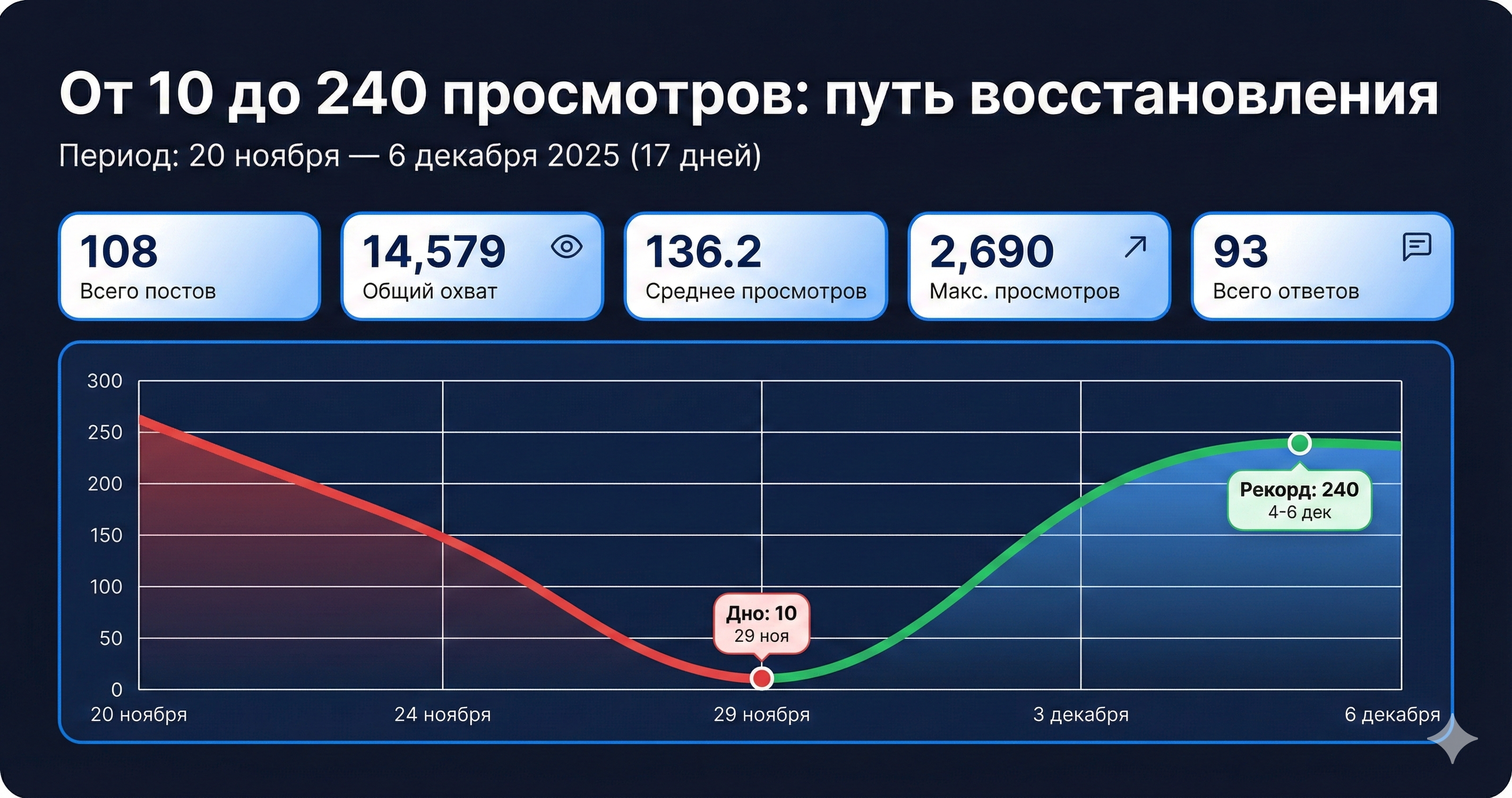


Что дальше?
Этот эксперимент дорого нам обошелся с точки зрения времени, но он преподал главный урок: в 2025 году полная автоматизация контента в социальных сетях – это утопия. Платформы эволюционировали, алгоритмы стали умнее, аудитория устала от AI-генерированного контента.
Мы не отказываемся от AI, но теперь он – наш второй пилот, а не автопилот. Посмотрим, куда нас приведет этот новый путь.
Следите за продолжением нашего эксперимента в нашем аккаунте в Threads!
Научитесь использовать AI правильно
Полная программа курса: от основ промптинга и критического мышления до специализаций по автоматизации и AI-агентам. Foundation + специализации для менеджеров.
P.S. Если вы тоже экспериментируете с AI в маркетинге/контенте – поделитесь опытом в комментариях. Особенно интересно услышать от тех, кто нашел рабочую формулу автоматизации.