AI-агент – это не промпт: 5 слоёв рабочего агента для руководителей
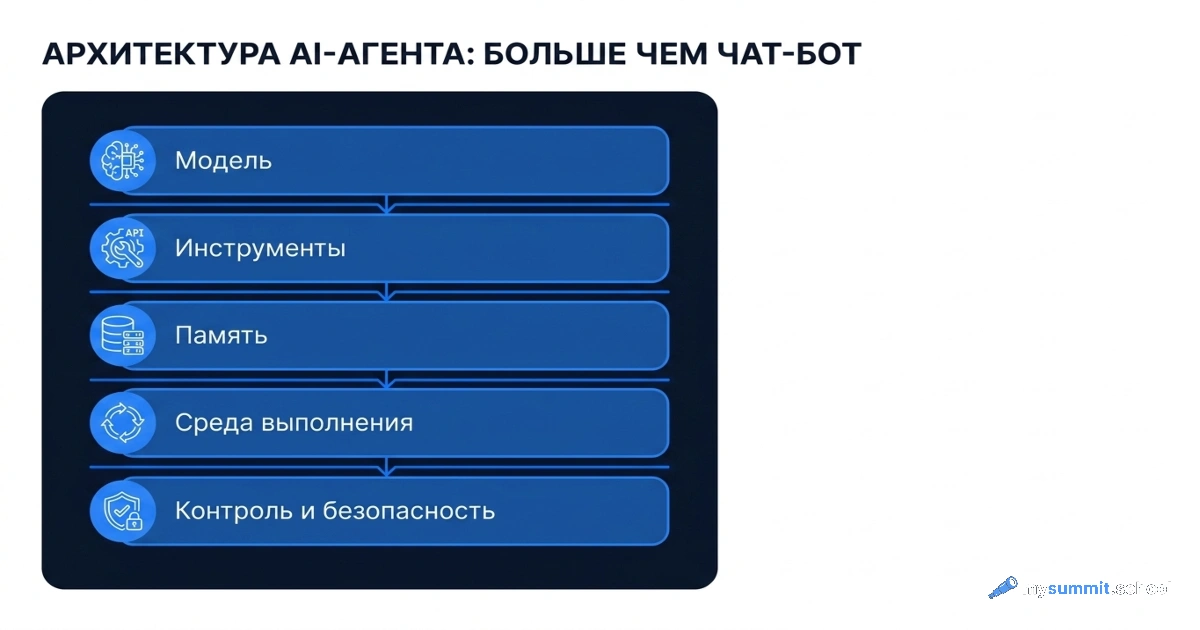
«Большинство людей до сих пор думают, что AI-агент – это просто ChatGPT с хорошим промптом». С этой фразы начинается статья Sunil Ramlochan «The AI Agent Stack Is Not a Prompt. It’s a Production System», и дальше автор называет это убеждение «утешительным мифом». Полезная правда, по его словам, в другом: настоящий агент ближе к маленькой операционной системе для работы. У него есть мозг, руки, память, правила, логи, планы восстановления и кто-то, кто отвечает, когда агент делает не то.
Тезис статьи укладывается в одну строчку: агент – это целый стек. И надёжность ему даёт архитектура вокруг, тогда как сама по себе модель или удачный промпт – лишь один из ингредиентов. Картина инженерная, поэтому разберём её с другой стороны – что из этого стека реально касается менеджера, который не пишет код, но решает, запускать ли агента в работу.
Читать полностью