Агентский ресёрч конкурентов: цикл с поиском и проверкой
11 мин чтения
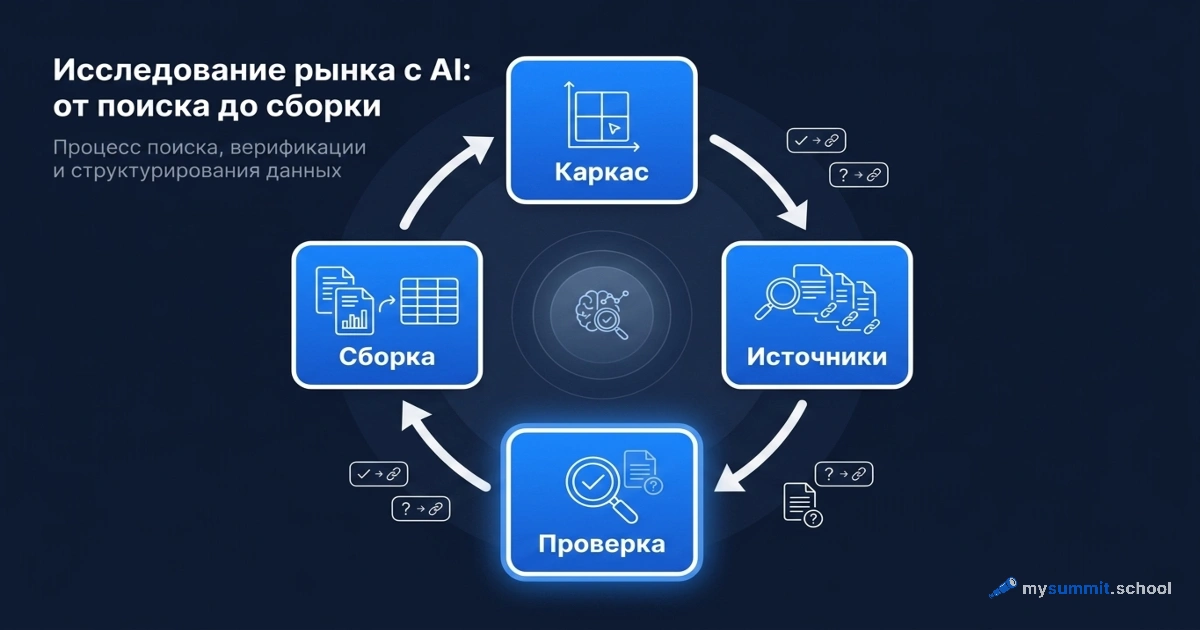
В предыдущем материале «Анализ конкурентов с ИИ: где модель выдумывает факты» мы показали, как наивный чат-бот сочиняет конкурентов: пять компаний в списке, две не существуют, обороты назначены на глаз. Рецепт там был один – проверять каждый факт руками. Но есть способ сократить количество выдумок ещё до проверки: проводить ресёрч не в чате, а в агентском инструменте, который сам ищет, открывает страницы и сверяет найденное за несколько итераций.
Этот материал – практический цикл такого ресёрча: от настройки инструмента до проверенного результата. Тот же пример, что и раньше, – оборудование для установок замедленного коксования (УЗК) для НПЗ. Боль та же, но инструмент другой.
Читать полностью