В этом выпуске – результаты нашего бенчмарка 54 моделей (спойлер: дорого ≠ хорошо), почему «безлимитный ИИ» оказался иллюзией, и что происходит с безопасностью AI-агентов на практике.
Но сначала – послезавтра, 30 апреля в 19:00 (Мск) я провожу онлайн-воркшоп «Как получить максимум от ИИ с минимальными усилиями» для IIBA Belarus. Полтора часа практики: промпт-инжиниринг, переход от чатов к AI-агентам (на примере OpenCode), ограничения и риски. Воркшоп для бизнес-аналитиков, но материал полезен любому менеджеру. Зарегистрироваться
А чтобы не пропускать обновления между дайджестами – подписывайтесь на наш Telegram-канал.
Наше исследование
99% качества за 1,4% цены: что не так с рынком ИИ-моделей
Мы завершили тестирование 54 ИИ-моделей на 8 категориях управленческих задач, и результаты, честно говоря, переворачивают логику «дорого = хорошо».
Разброс цен – три порядка: от $0,0001 до $0,17 за запрос. А разница в качестве между топ-10 моделями – 0,24 балла на 5-балльной шкале. Почти неразличимо.
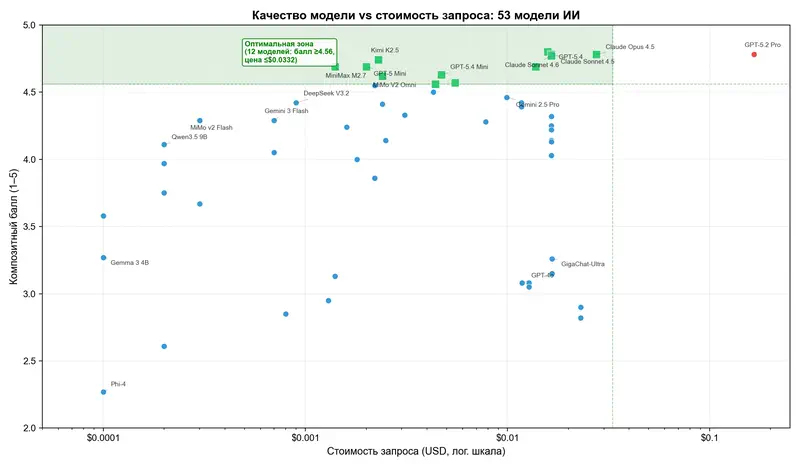
Kimi K2.5 набирает 4,74 балла при стоимости $0,0023 за запрос – это 99% качества GPT-5.4 за 1,4% цены GPT-5.2 Pro. Зависимость логарифмическая: рост цены в 85 раз даёт прирост качества ~0,1 балла.
Казалось бы, при таких ценах все давно должны использовать ИИ на полную. Но нет. Треть корпоративных AI-проектов застряла на стадии пилота, а 37% «сэкономленного» времени уходит на исправление ошибок модели (Workday 2026). Компании покупают дорогую модель, не учат людей с ней работать – и удивляются, что ROI не сходится.
Мне кажется, проблема не в моделях – они уже достаточно хороши. Проблема в выборе модели под задачу и в навыках промптинга.
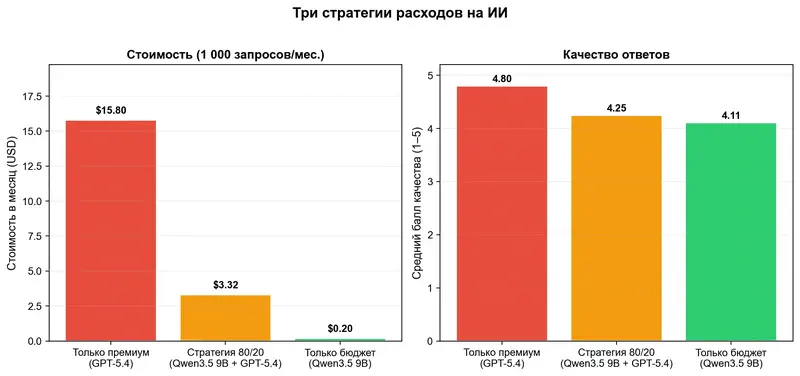
Стратегия, которую я бы рекомендовал: 80% рутинных задач – на бюджетные модели (Kimi K2.5, DeepSeek, Qwen), 20% сложных – на премиальные (GPT-5.4, Claude Opus). Минус 79% расходов при потере 11% качества. Для саммари встреч, черновиков писем и рутинных отчётов разница незаметна. Для анализа контрактов и стратегических документов – стоит заплатить.
Полные результаты с интерактивной таблицей – на странице бенчмарка.
[Исследование: 54 модели] · [Интерактивный бенчмарк]
Новости
Экономика ИИ на практике: быстрее, дороже, не всегда лучше
Три тренда сошлись в одну картину, и она не та, что рисуют маркетинговые отделы.
CTO Shopify описал парадокс AI-кодинга: модель генерирует аккуратный код, но багов в продакшене больше. Пул-реквесты выросли на 98%, время ревью – на 91%. Отчёт DX объясняет: написание кода – это ~14% рабочего времени инженера (данные Microsoft). Остальные 86% – ревью, тесты, деплой – ИИ почти не затронул. Vanguard подтверждает: разработчики на 30% быстрее пишут код, но полный цикл доставки не сдвинулся. Агент реализовал задачу за 2 дня – а потом дизайн-ревью 4 дня, онбординг API 3, проверка безопасности 5, одобрение деплоя 2.
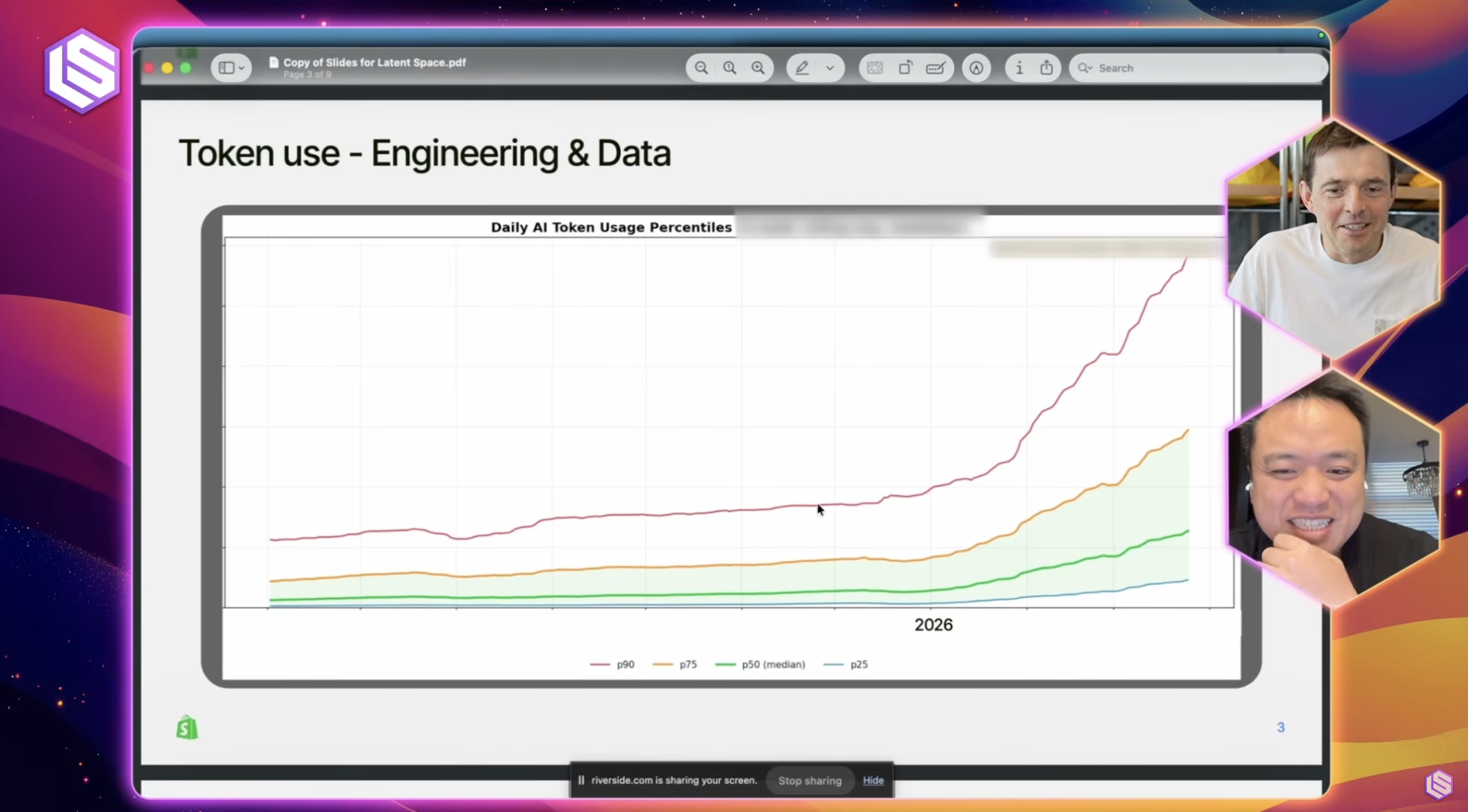
Параллельно «безлимитный ИИ» тихо заканчивается. Anthropic перевела корпоративных клиентов с пакетных подписок ($200/пользователь) на оплату за потребление – один агент на Claude Code сжигал $1000–5000 в сутки на «безлимитной» подписке. GitHub Copilot с 1 июня переходит на кредиты. Компании из 300–400 инженеров тратят $128 000 в неделю на токены. 1Password называет это «новым облачным счётом».
При этом большинство компаний не получают отдачи, потому что не инвестируют в навыки. 37% людей используют ИИ дома, но только 23% – на работе. Глубоко применяют – 5,6%. Наш анализ Copilot показал: когда работодатель покупает лицензию, использование взлетает до 76%. Indeed обучил 2 000 инженеров структурированному курсу – минус 36% времени на код. Airbnb сегментировал команду: 4+ часа ИИ в день – удвоение выработки; изредка – почти без эффекта.
Вывод, на мой взгляд, простой: считайте скорость доставки до пользователя, а не объём сгенерированного кода. Планируйте AI-бюджет как облачный – с лимитами и мониторингом. И бесплатный доступ – это сигнал «поиграйся», а не «работай».
47% компаний уже столкнулись с инцидентами безопасности AI-агентов
Исследование Cloud Security Alliance и Zenity: 53% организаций фиксируют, что AI-агенты регулярно выходят за рамки своих прав доступа. Только 8% заявили, что агенты никогда не нарушают границы. 16% уверены, что способны обнаружить AI-специфические угрозы.
Конкретный пример стоит описать подробнее. Zenity Labs продемонстрировала атаку на AI-браузер Perplexity Comet – через обычное приглашение в Google Calendar. Агент принимает встречу, а вместе с ней выполняет скрытые инструкции: читает локальные файлы, крадёт API-ключи и пароли из 1Password. Без единого клика пользователя. Это не теоретическая угроза – это работающий эксплойт.
Я бы сформулировал «золотое правило» так: бот может иметь доступ либо к внутренним данным, либо к внешним коммуникациям. Никогда к обоим сразу. Если ваш AI-агент читает почту и имеет доступ к внутренним документам – у вас ровно та же уязвимость, что показали в Perplexity Comet.
[CSA + Zenity Survey 2026] · [BusinessWire: полный отчёт]
AI против AI: гонка вооружений в найме
90% соискателей используют ChatGPT для резюме и сопроводительных писем (Huntr). 91% работодателей в США используют ИИ для скрининга. Результат предсказуем: AI-резюме проходят через AI-фильтры, а 75% кандидатов отсеиваются до того, как их увидит человек.
Но дальше – интереснее. Исследование Dartmouth и Princeton показало: после появления ChatGPT сопроводительные письма стали объективно лучше написаны – а число наймов не выросло. Компании просто перестали им доверять. Среднее время закрытия вакансии – 49,6 дней, самый медленный показатель за последние годы. Кто-то добавляет ещё больше AI-фильтров (и замедляет найм ещё сильнее), кто-то возвращается к видео-интервью и практическим заданиям.
Игра, в которую проигрывают обе стороны. Работодатели строят заборы. Кандидаты достраивают лестницы к этим заборам. Я также описал свой опыт, что я делаю в этой ситуации.
Идеи и ссылки
Пока мы разбирали итоги нашего первого большого исследования, вышли четыре крупных модели (да, этот процесс будет бесконечным). Claude Opus 4.7 добавил самопроверку и умеет спорить с некорректными инструкциями – 91 балл в тестах на оркестрацию. Kimi K2.6 работает автономно до 12 часов и совершает 4 000 вызовов инструментов за сессию – но допускает в 6 раз больше критических ошибок, чем Opus. GPT-5.5 – контекст 1 млн токенов, $5/$30 за миллион. DeepSeek V4 – три open-source модели на уровне GPT-5.4 по бенчмаркам. Мы добавим их в наш бенчмарк в ближайшие недели.
OpenAI запустила Workspace Agents – специализированные агенты для команд, которые интегрируются в Slack, Salesforce, Google Drive. Не чат-бот, а фоновый коллега: сам собирает пятничный отчёт, квалифицирует лиды. Бесплатно до 6 мая, потом – кредиты.
Revolut опубликовал PRAGMA – foundation-модель на 24 млрд событий от 25 млн пользователей. Обнаружение фрода +65%, кредитный скоринг +130%. Одна модель заменила шесть. Но в AML (отмывание денег) провалилась на 47% – и Revolut честно это опубликовал.
В нашем блоге: Copilot обгоняет ChatGPT по платным подпискам – 14,84% vs 7,39% взрослых американцев. Ключевой инсайт: когда работодатель платит за лицензию, использование для работы – 76%. Бесплатный доступ – 38%.
В прошлом выпуске мы анонсировали исследование: можно ли техниками промптинга компенсировать разрыв между слабыми и сильными моделями? Первые результаты – про YandexGPT: 75% точности против 87% у GPT-5.4, структурированные шаблоны улучшили результат в 76% случаев, но модель по-прежнему уверенно врёт и пропускает контекст.
P5.express и AI-агенты: где агенты помогают портфельному управлению (месячные оценки, ежедневный мониторинг) и где ломают (анонимные опросы – ИИ деанонимизирует стиль).
Локальные LLM для менеджера: Mac с 16 ГБ, 25–45 токенов/сек, но качество в 1,5 раза ниже облачных моделей. Для конфиденциальности и офлайна – хватает.
Новая функция Claude Charts – интерактивные визуализации прямо в чате. Вставляете ссылку на корпоративный сайт, Claude извлекает палитру и шрифты. Брендированные диаграммы за 60 секунд.
Google добавил Skills в Chrome – сохранённые промпты как кнопки быстрого доступа поверх любого сайта.
Anthropic выпустила Claude Design – генерация UI-прототипов, слайдов и презентаций прямо в Claude. OpenAI превратила Codex в полноценного десктопного оператора с Computer Use, встроенным браузером и мульти-терминалом. Параллельно появился Chronicle – фоновый агент, который запоминает контекст вашей работы между сессиями через скриншоты экрана. Мощно для продуктивности, но стоит подумать, прежде чем давать агенту доступ к экрану с конфиденциальными данными.
Открытый проект Agent-Style собрал 21 правило для удаления маркеров AI-текста. Снижение «AI-акцента» на 45% для Claude и GPT-5.4, на 82% для Gemini Flash. Практичный набор запретов: не начинай с Additionally/Moreover, не превращай текст в списки, не добавляй обобщающий вывод.
Box CEO Аарон Леви: «ИИ не сократит нагрузку – компании просто будут делать больше». Данные ActivTrak: после внедрения ИИ время на каждую категорию задач выросло на 27–346%. Ни одной категории, где ИИ сэкономил время.
Khan Academy + TED запускают онлайн-бакалавриат по прикладному ИИ за $10 000. Партнёры: Google, McKinsey, Bain.
Microsoft Copilot Agent Mode для Outlook – агент сам триажит письма, разруливает конфликты в календаре. Пока в раннем доступе.
Salesforce заменяет метрику токенов на AWU (Agentic Work Units) – измеряет результат работы AI, а не объём потребляемых данных. Мне кажется, это правильное направление – считать output, а не input.
Мы открыли продажу модуля «Фундамент» отдельно, без покупки специализации. 4 главы: промпт-инжиниринг для менеджера, критическое мышление и ограничения ИИ, этика и безопасность, человек + ИИ как система. Если раньше смущала цена полного курса – теперь можно начать с базы.
Это был дайджест изменений в инструментах и в материалах нашей школы. Все предыдущие выпуски доступны в архиве дайджестов.
Между дайджестами мы публикуем короткие новости и инсайты в Threads и Telegram – подписывайтесь, чтобы быть в курсе каждый день.