В этом выпуске – мы спросили 40 менеджеров, чего они на самом деле хотят от ИИ, и написали пять статей-инструкций по топ-запросам. Параллельно SpaceX купила Cursor за $60 млрд, США заблокировали Fable 5 от Anthropic, а 78% команд фиксируют рост инцидентов от AI-кода. И ещё один неудобный факт: 57% ваших сотрудников скрывают, как пользуются нейросетью.
Чего менеджеры хотят от ИИ: данные 40 ответов
Топ-3 запросов не совпал с тем, что продают вендоры
У нас накопились реальные ответы студентов – менеджеров проектов и продуктов, аналитиков, HR – на простой вопрос: какую рабочую задачу вы хотели бы ускорить с помощью ИИ? Без подсказок, без вариантов ответа. Сорок человек написали, чего хотят. Мы разобрали результаты и написали по каждому топ-запросу отдельную статью с готовыми промптами.
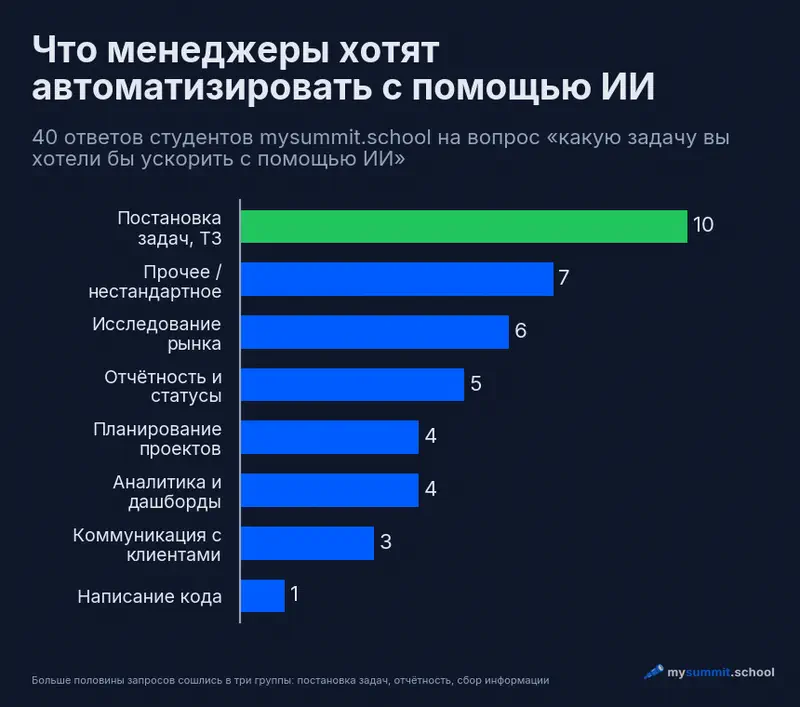
Больше половины запросов сошлись в три группы. Каждый четвёртый ответ – про постановку задач разработчикам (ТЗ, user stories, критерии приёмки). С заметным отрывом идут регулярная отчётность – еженедельные статусы, резюме встреч, материалы к планёркам – и самая разнородная категория: конкурентный анализ, кейсы по отрасли, систематизация данных о рынке.
Мне кажется, самое интересное здесь – что эти три группы почти точно ложатся на то, что языковые модели делают хорошо. Это работа с текстом: взять неструктурированный вход и привести его к нужной форме. Не аналитика, не дашборды, не чат-боты – скучная, повторяющаяся рутина, которая съедает часы каждую неделю. Совпадение спроса и возможностей инструмента здесь почти идеальное.
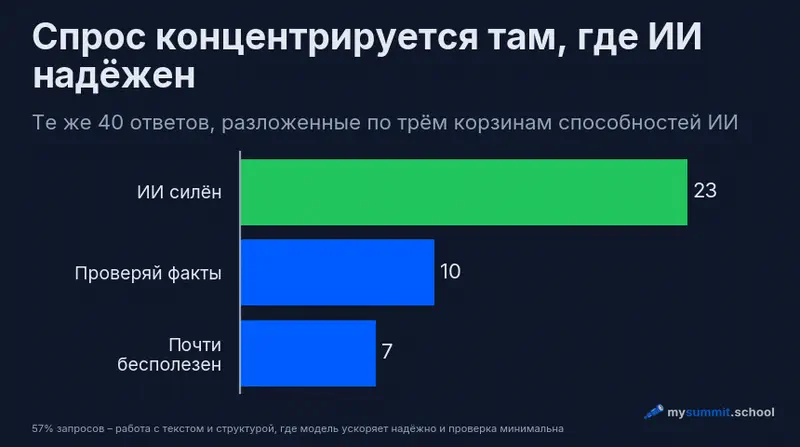
В прошлом выпуске мы разбирали thinkslop – ситуацию, когда люди отдают ИИ само мышление. Эта серия – своего рода антидот: структурируйте рутину и отдавайте модели, оставляя суждения себе. ТЗ, статусы, черновики – задачи, где ИИ ускоряет работу, а решение по-прежнему за вами.
По каждому из трёх запросов мы написали отдельную статью с промптами, которые можно копировать и адаптировать:
- Как ставить задачи разработчикам с ИИ – от размытой формулировки до проверенного ТЗ за 5 шагов
- Автоматизация отчётов и статусов – цикл черновик-правка-публикация для еженедельных статусов
- Конкурентный анализ: где ИИ врёт – почему Perplexity работает лучше чата и как отличать факты от галлюцинаций
- Разбор обращений клиентов с ИИ – классификация + черновик ответа, минус 50% времени
Вся серия построена по одному принципу: реальная задача менеджера, готовый промпт, объяснение, почему он устроен именно так. Без теории про трансформеры.
Парадокс AI-кода: $60 млрд за Cursor и 78% инцидентов
Принятие – на максимуме. Контроль качества – отстаёт.
Три новости сходятся в одной точке. SpaceX купила Anysphere – разработчика AI-редактора Cursor – за $60 млрд. Самая дорогая сделка в истории ИИ. Глава NVIDIA Дженсен Хуанг ещё в октябре заявлял: 100% инженеров компании перешли на Cursor. Не пилот, не эксперимент – полное покрытие. На другом конце спектра – продакт-овнер без навыков программирования, который внедрил 7 фич за один цикл за 4 часа и прошёл ревью без замечаний. Порог входа в код стремится к нулю.
А теперь вторая сторона. Исследование New Relic (State of AI Coding 2026) фиксирует: 78% инженеров отмечают рост инцидентов, связанных с AI-сгенерированным кодом. 86% говорят, что старшие разработчики тратят больше времени на исправление проблем. И самое тревожное: две трети команд не проводят построчное ревью AI-кода. Код принимается «как есть».
Это парадокс нынешнего момента. Принятие – на максимуме. Контроль качества – отстаёт. SOTA-модели склонны к оверинжинирингу: вместо простого решения предлагают избыточно сложную архитектуру, нарушая принцип KISS. А менеджер видит метрику «количество фич» и не замечает растущий техдолг.
Мы написали отдельную статью о том, что AI-агент – это не промпт, а система из пяти слоёв: модель, инструменты, память, рантайм и слой безопасности. Если вы запускаете агентов в продакшен – без архитектуры вокруг модели они будут генерировать ровно тот мусор, о котором пишет New Relic.
Практический вывод простой: если вашей команде уже раздали Cursor или Copilot, проверьте, что у них есть процесс ревью AI-кода. Если нет – вы на стороне тех 78%.
Reuters: SpaceX + Cursor · New Relic: State of AI Coding 2026 · 5 слоёв AI-агента
Fable 5 заблокировали – но это уже не катастрофа
Vendor-риск стал реальным. Монополия флагманов – закончилась
Самая громкая инфраструктурная история двух недель – США заблокировали доступ к Fable 5 и Mythos 5 от Anthropic. Экспортный контроль со ссылкой на угрозу кибербезопасности. Доступ отключили даже сотрудникам Anthropic без гражданства США – за 15 минут, без переходного периода. Если вы строили продукт на Fable, вы узнали об этом из новостной ленты, а не от вендора.
Это новый тип vendor-риска. Раньше мы думали о цене или об отключении API по техническим причинам. Теперь добавился регуляторный: правительство может отозвать доступ к инструменту, на котором построена часть вашего стека, в любой момент и без предупреждения. Для менеджера это означает одно – single-vendor зависимость от американской модели стала неприемлемым риском.
Но здесь же – главное отличие от ситуации год назад. Качественный разрыв между флагманом и преследователями почти исчез, и всё за те же две недели:
- Z.AI выпустила GLM-5.2 – открытая модель под MIT-лицензией с контекстом 1 млн токенов. По тестам на логику почти догоняет Claude Opus, а в кодинге местами обходит. Мы разбирали её в статье про вайб-кодинг и агентный инжиниринг.
- Японская Sakana AI запустила Fugu – multi-model систему, которая собирается из более лёгких моделей и достигает frontier-качества без Fable. Буквально позиционируется как ответ на блокировку: «No Fable? No problem».
Если у вас в продакшене один Anthropic или один OpenAI – сейчас самое время завести второй контур. Качество здесь ни при чём – регулятор может решить за вас. И впервые за всю историю LLM это не означает падения качества – достаточно открыть бенчмарк и выбрать из нескольких моделей, которые делают то же самое.
TechCrunch: ban overview · Anthropic official · GLM-5.2 review · Sakana Fugu
57% скрывают, что пользуются ИИ. Проблема не в инструментах
Разрыв между домом и офисом – 14 процентных пунктов
Свежие данные Axios: 37% сотрудников используют ИИ в личных целях, но только 23% – на работе. Разрыв в 14 п.п. – и он не про отсутствие инструментов. Люди умеют, но не применяют. Параллельно глобальное исследование KPMG показывает: 57% сотрудников скрывают, как используют ИИ на работе. Не потому что нарушают политику – потому что боятся.
Мы разобрали это подробно в статье. Три рациональных расчёта сотрудника: репутационный риск («выгляжу как читер»), риск нагрузки («если покажу, что стал быстрее – догрузят»), риск замены («мой метод задокументируют и передадут другому»). Данные Техасского A&M подтверждают: профессор Мэтью Колл прямо советует сотрудникам использовать личные инструменты для самой ценной работы, чтобы метод оставался при них.
А вот что интересно. Отсутствие плохих новостей и споров в команде – не признак гармонии. Исследования показывают, что команды с открытой культурой обратной связи на 30% эффективнее в решении кризисных ситуаций. Если в вашей команде все молчат об ИИ – это не потому, что им нечего сказать.
Картина дополняется данными о том, что внедрение делится на трети: активные пользователи, эпизодические и те, кто сознательно в стороне. Ошибка большинства планов внедрения – считать команду однородной. На практике каждой трети нужно разное: продвинутым – сложные сценарии, эпизодическим – одна конкретная задача, которая закрепит привычку, скептикам – доказательство ценности на их собственной работе.
Мне кажется, проблема – в разрешении. Доступ к инструментам у людей есть, они ими пользуются дома. Если вы руководите командой и ни один человек за последний месяц не показал вам свой AI-метод – это управленческий красный флаг.
Почему команда скрывает ИИ · Внедрение делится на трети
Идеи и ссылки
Фреймворк для делегирования задач ИИ: три условия – наличие локального контекста, существующие примеры и низкая стоимость исправления ошибки. Если все три выполнены – отдавайте задачу модели, не раздумывая. Простой фильтр, который экономит время на сомнения.
Рынок моделей перетряхивается. Доля ChatGPT впервые упала ниже 50%: 46,4% к маю 2026, Gemini – 27,7%, Claude – 10,3%. Параллельно идут слухи, что OpenAI готовит GPT-5.6 с контекстом 1,5 млн токенов и ценой ниже Anthropic – война за кошельки переходит в фазу демпинга. Привязка к одному инструменту – теперь стратегический риск, а не удобство.
Разделение планирования (Claude Fable 5) и исполнения (GPT-5.5) снижает стоимость разработки на 59% без потери качества. Мысль здравая: зачем платить за «мозг» там, где нужны только «руки». Мы разбирали похожий подход в контексте стоимости моделей.
MiniMax M3 находит 13 из 17 багов в коде за $0,07 – столько же, сколько Claude Opus, но в 10 раз дешевле. А стоимость инференса MiniMax M2.5 через европейские шлюзы дошла до $0,15 за миллион входных токенов. Китайские модели продолжают давить на цены.
Grok Build 0.1 – AI-агент xAI для рутинных задач. Очистка Git-истории за 41 секунду, $0,09. Скрытый пароль в истории коммитов – тоже за 41 секунду, на что у человека уходит 30 минут. Стоимость смешная, скорость впечатляющая.
Сатья Наделла ввёл термин Loopcraft: успех компании зависит не от выбора лучшей модели, а от «петель обучения», связывающих человеческий капитал с токен-капиталом. «Вы можете аутсорсить задачу или даже работу, но вы не можете аутсорсить обучение». На мой взгляд, это хорошо формулирует то, что мы видим на практике – инструмент без навыков не даёт отдачи.
AI-агенты превращаются в штат. В McKinsey уже работают 25 000 агентов на 60 000 сотрудников – почти один цифровой коллега на двух людей. И Gartner прогнозирует, что к концу 2026 года до 40% корпоративных приложений будут включать ИИ-агентов. Цифры разные, сигнал один – агенты переходят из пилотов в операционку.
Параллельно агенты начинают платить сами. На одной неделе: Mastercard запустил AP4M – платежи агентов за логистику и домены в рамках лимитов, Visa и OpenAI договорились о платежах через ChatGPT по картам Visa, Coinbase for Agents дал Claude и ChatGPT доступ к крипто-аккаунтам, а Ramp Stack превратил AI-агентов в операционку для финотдела. Четыре инфраструктурные новости за две недели – это уже не эксперимент.
AI режет штаты. Shopee сократил 8% разработчиков (сотни человек) под предлогом внедрения ИИ. Больше всего пострадали QA и рутинные технические роли. В целом увольнения из-за AI в 2026 году достигли 50 000 – почти столько же, сколько за весь прошлый год. Тренд прямой замены набирает обороты.
Stripe обучил ИИ на десятках миллиардов транзакций – точность обнаружения фрода выросла с 59% до 97%. Заблокировано мошенничества на $112 млрд за год. Пример, где AI не экспериментирует, а работает на масштабе.
Кризис AI-бюджетов, который мы разбирали в прошлом выпуске (Copilot по токенам, Uber за 4 месяца, tokenmaxxing), продолжается. Databricks запустил Unity AI Gateway для контроля «теневых» расходов – компании тратят десятки миллионов в месяц на токены из-за неуправляемых агентов. Microsoft переводит Copilot на оплату по объёму вычислений. Если вы ещё не ввели лимиты – самое время.
Два предупреждения о тёмной стороне. KPMG отозвала собственный отчёт об ИИ из-за галлюцинаций: нейросеть выдумала кейсы внедрения для UBS и NHS. Сапожник без сапог. И исследование в Nature: врачи, привыкшие к AI-ассистенту, стали на 6% хуже находить опухоли сами. Дескиллинг стал измеримым эффектом. Это перекликается с темой thinkslop из прошлого выпуска: инструмент ускоряет, но если не следить – забирает с собой и экспертность.
Из нашего блога
52% компаний запустили AI-агентов – отчёт Google Cloud о новой роли менеджера как супервайзера агентов. Меняется не количество подчинённых, а тип подчинённых.
Thinkslop: как ИИ подменяет мышление – разбор исследования HBR (более 12 тысяч кейсов): в четверти случаев люди отдают модели само суждение. Эта статья легла в основу выпуска #16 – перечитайте, если пропустили. А свежие данные о дескиллинге врачей и провале KPMG – лучшее тому подтверждение.